
Intelは、12月14日に発売が予定されているコードネーム「Meteor Lake」と呼ばれる次期モバイルCoreプロセッサを明らかにした。これらのプロセッサーは、EUVリソグラフィをベースとし、性能と電力効率を改善したIntelの新しい「Intel 4」プロセスノードを初めて採用する。これは、チップの異なるコンポーネントが異なるプロセス・ノードで製造され、Intelの3D Foverosパッケージング・テクノロジーを使って積層されることを意味する。

Meteor Lake CPUは、「i」ブランドを廃止した初のCPUシリーズとなる。次期Core Ultra CPUは、Arc GPUアーキテクチャ(Xe-LPG)、Redwood Cove Pコア、Crestmont Eコアを搭載する。また、SoCダイには専用の高効率Eコアが搭載される。
Intelは、Meteor LakeがPCIe Gen5インターフェイス、USB4、Thunderbolt 4をサポートすることを確認している。
Intelは、その新しい設計手法によって電力効率が驚くほど向上したと述べているが、性能ベンチマークはまだ共有していない。同社はFoverosパッケージング技術への移行を、過去40年間で最大のアーキテクチャの転換であると説明している。
Meteor Lakeは、Intelのプロセッサー設計を根本的に見直しただけでなく、プロセッサー製造のアプローチも見直した。Intelは、プロセッサー上の4つのアクティブ・タイルのうち3つにTSMCのプロセス・ノード技術を採用し、一部の機能にはより安価なTSMCノードを2つ、CPUタイルに使用している自社の「Intel 4」ノードよりも高密度で高性能なTSMCノードを1つ選択している。
目次
Intel Meteor Lakeアーキテクチャの概要

Intelが呼ぶ新たな「タイル型」アーキテクチャだが、これは他の業界ではチップレット・アーキテクチャと呼ばれているもので、両社に明確な技術的な違いはない。Intelによれば、「タイル型」プロセッサーとは、チップユニット間のパラレル通信を可能にするアドバンスト・パッケージングを採用したチップのこととのことだ。標準的なパッケージングで採用されているシリアル・インターフェースと比較し、性能やエネルギー効率の面で秀でているとしている。
Meteor Lakeは、1つのパッシブ・インターポーザーの上に、コンピュート(CPU)タイル、グラフィックス(GPU)タイル、SoCタイル、I/Oタイルの4つの分割されたアクティブ・タイルを搭載している。これらのユニットはすべてIntelが設計し、Intelのマイクロアーキテクチャを搭載しているが、I/O、SoC、GPUタイルは外部のファウンドリであるTSMCが製造し、CPUタイルはIntelがIntel 4プロセスで製造する。これら4つのアクティブ・タイルはすべて、Intelが製造する単一のFoveros 3Dベース・タイルの上に乗っており、十分な高帯域幅と十分な低レイテンシで機能ユニットを結びつけることで、チップは可能な限り1つのモノリシック・ダイに近い形で機能する。
俯瞰してみると、Meteor LakeにはAIワークロードを処理できるCPU、NPU、GPUの3つのコンピュートユニットがある。AIワークロードは、ワークロード要件に基づいて各ユニットに振り分けられるようだ。
| Intel Meteor Lake タイル/チップセット | マニュファクチャ / ノード |
|---|---|
| コンピュート・タイル | Intel / ‘Intel 4’ |
| 3D Foverosベース・ダイ | Intel / 22FFL (Intel 16) |
| グラフィックス・タイル (tGPU) | TSMC / N5 (5nm) |
| SoC・タイル | TSMC / N6 (6nm) |
| IOE・タイル | TSMC / N6 (6nm) |
Intel 4プロセスノード

Intel 4の主な利点の1つは、そのエリア・スケーリング能力である。Intel 4プロセスは、以前のIntel 7プロセスと比較して、高性能ロジック・ライブラリの面積を2倍に拡大することができる。このような方法でスケールアウトする能力を持つことは、より多くのトランジスタをチップに搭載するために不可欠であり、理論的にはシリコンの全体的な性能と効率を向上させるはずだ。Intel 4はまた、高性能コンピューティング・アプリケーション向けに最適化されており、低電圧(0.65V未満)と高電圧(1.1V以上)の両方の動作をサポートしている。Intelは、このような柔軟性を持つことで、Intel 7に比べてアイソパワー性能が20%以上向上すると主張している。また、この技術には高密度のMIM(Metal-Insulator-Metal)コンデンサが組み込まれており、チップへの電力供給が優れていると主張している。

EUVを採用したIntel 4では、SAQP(self-aligned quad patterning)を採用した30mmのフィンピッチと、Intel 7の54/60nmから0.83倍スケールダウンした50nmのタングステンゲートピッチを採用している。M0ピッチも40nmから30nmへと0.75倍縮小され、HPライブラリの高さもIntel 7の408nmからIntel 4の240nmへと0.59倍と大幅に縮小された。4フィンから3フィンの割り当てに移行したことで、Intel 4のMeteor LakeはIntel 7よりもゲート間隔が狭くなっている。
Intel 4で新たに導入された重要な点の1つは使用される材料で、Intelは「Enhanced Copper」と呼ぶものを使用している。Intelは具体的な混合比率を明らかにしていないが、エンハンスド・カッパーは基本的に銅(Cu)にコバルト(Co)を付着させたもので、高抵抗と大容量の障壁を排除するように設計されている。銅とコバルトの複合冶金はM0層からM4層で使用され、M5層からM15層は50nmから280nmまでの異なるピッチの銅で作られている。
| Intel 4 | Intel 7 | 変化量 | |
|---|---|---|---|
| フィンピッチ(FP) | 30 nm | 34 nm | 0.88倍 |
| コンタクトゲートピッチ(CGP) | 50 nm | 54/60 nm | 0.83倍 |
| 最小メタルピッチ (M0) | 30 nm | 40 nm | 0.75倍 |
| HPライブラリの高さ | 240h | 408h | 0.59倍 |
| 面積 (ライブラリの高さ x CGP) | 12K nm2 | 24.4K nm2 | 0.49倍 |
Intel 4での極端紫外線(EUV)リソグラフィーの使用は、半導体製造における大きな進歩である。波長約13.5ナノメートルのX線(レーザーで錫をザッピングすることにより発生)を使用することにより実現されるEUVリソグラフィは、フォトリソグラフィプロセスを大幅に改善・最適化し、解像度とパターン忠実度の計測を向上させる。この技術には、高精度光学系や真空チャンバーなどの特殊な装置が必要で、EUVリソグラフィ・システム1台の価格は約1億5000万ドルだ。
製造チップを使用するとなると、シングルパターニングとマルチパターニングの両方、さまざまなレベルのパターニングがある。EUVを使用することで、Intelは製造工程におけるマスクとステップの数を減らすことができ、マルチパターニングのステップを単一のEUVレイヤーに置き換えることで、Intel 4ではIntel 7よりもマスクの数を最大20%減らすことができる。各パターニング・レベルにはそれぞれ独自の課題があるが、EUVでは、1つのパターンを1回の露光でエッチアウトすることができる。これは、生産量が増加し、プロセス全体を通してフローが速くなることを意味する。マルチパターニングを選択することは、より多くのコストと高いばらつきを意味する。シングルパターンのEUVプロセスを使用するもう一つの利点は、シリコン内の欠陥の数を減らすことである。
多額の設備投資と運用費がかかるにもかかわらず、この技術は、Intel 4ではマスク数を20%削減し、プロセス工程を5%削減するなど、多くの利点を提供する。これらの効率は、優れた面積のスケーリングと歩留まりの最適化に貢献し、EUVリソグラフィは、リーダーシップを取ろうとするIntelのプロセッサ・ロードマップの礎石となる。また、EUVリソグラフィは、エンベデッド・マルチ・ダイ・インターコネクト・ブリッジ(EMIB)のようなアドバンスト・パッケージング技術(APT)との相乗効果もあり、Foveros 3Dパッケージングと組み合わせることで、半導体およびチップ製造における先進技術としての役割をさらに確実なものにしている。
Foveros 3D パッケージング

パッケージングと相互接続の進歩は、最新のプロセッサの姿を急速に変えつつある。両者は現在、基礎となるプロセス・ノード技術と同様に重要であり、ある面ではより重要であることは間違いない。なぜなら、性能、消費電力、およびコストの最適なブレンドを引き出すために、単一のパッケージ内で異なるタイプのプロセス・ノードを混在させ、マッチングさせることができるからだ。
Intelは、低コストかつ低消費電力に最適化された22FFLプロセスでFoverosインターポーザーを製造している。Intelは、パッシブFoveros 3Dインターポーザー/ベース・タイルの上に4枚のMeteor Lakeタイルを配置し、タイルとインターポーザーを高速通信と効率的な電力供給を可能にするマイクロバンプ接続で融合させる。パッシブ・インターポーザーはロジックを持たないため、何らかの処理を行うことはなく、ほとんどがタイル間の高速通信経路として機能する。しかし、MIMキャパシタ(500nf/mm^2)が内蔵されており、高負荷時にタイルへの安定した電力供給に役立っている。
Foverosは、36ミクロンのバンプピッチ(相互接続密度の重要な測定値)を使用しており、Lakefield(最初のFoverosチップ)で使用した55ミクロンのバンプピッチよりも改善されている。現時点では、フォベロスは1平方ミリメートルあたり最大770マイクロバンプを可能にしているが、将来的には飛躍的に向上するだろう:フォベロスのロードマップには、将来の設計で25ミクロンと18ミクロンのピッチが含まれている。Intelによれば、将来的には、ハイブリッド・ボンディング相互接続(HBI)を使用して1ミクロンのバンプピッチを実現することも理論的には可能だという。
| インターコネクト | ピコジュール/ビット(pJ/b) |
|---|---|
| NVLink-C2C | 1.3 pJ/b |
| UCIe | 0.5 – 0.25 pJ/b |
| Infinity Fabric | ~1.5 pJ/b |
| TSMC CoWoS | 0.56 pJ/b |
| Foveros | Sub-0.3 pJ/b |
| EMIB | 0.3 pJ/b |
| Bunch of Wires (BoW) | 0.7 to 0.5 pJ/b |
| On-die | 0.1 pJ/b |
Foverosは電力効率も非常に高く、1ビットあたり0.3ピコジュール(pJ/b)未満と、オフダイ・インターコネクトの中でも最高のエネルギー効率を実現しています。また、インターポーザーの高密度接続により、Intelは外部I/Oインターフェースで発生した海岸線の問題を心配することなく、タイルを分割することができる。Intelは、Foverosダイを可能な限り低コストでありながら、電気的および性能的目標を達成できるように設計した。
Intelによれば、Foverosのインターコネクト/ベースタイルは1mmあたり最大160GB/秒をサポートするため、インターコネクトを追加すれば帯域幅は拡張できる(インターフェイスは「複数GHz」で動作可能)。そのため、Foverosでは、設計上のトレードオフを必要とするような大きな帯域幅やレイテンシの制約は発生しない。
全体として、Intelは、インターフェイスが信じられないほど高速で電力を節約できるため、Foveros技術によるトレードオフは、トラブルに見合う価値があると感じている。また、より小さなチップレットを使用できるため、ウェハー1枚当たりのダイ数を10%増やすことができ、全体的なコスト削減に貢献するなど、三次的なメリットもある。Intelはまた、Foverosの背後にあるパッケージング技術は、全体として、既存の生産フローとドロップイン互換性があると述べている。

結局のところ、先進のパッケージング技術は、モノリシック・ダイの主要な性能と電力特性を、チップレット・ベースのアーキテクチャで模倣するために使用される。Intelは、Foverosがこれらの目標を満たす勝利の方程式であると考えている。
Meteor Lake コンピュートタイル
Intelはコンピュート(CPU)タイルをIntel 4プロセスで製造しているが、このプロセスを選択した理由は、ハイパワーCPUの特定の要件に合わせてプロセスノードを厳しくチューニングする機会を提供できるからである。


前回と同様、IntelはPコアとEコアを混在させており、Pコアはレイテンシに敏感なシングルスレッドとマルチスレッドの作業を処理し、Eコアはバックグラウンドと高負荷のスレッドタスクの両方を処理する。しかし、これら2種類のコアは現在、SoCタイル上に配置された2つの新しい低消費電力アイランドEコアによって増強されている。この2つの新しいコアは、以下のSoCタイルのセクションで説明する低消費電力タスク向けだ。Intelはこの新しい3層コア・ヒエラルキーを3Dパフォーマンス・ハイブリッド・アーキテクチャと呼んでいる。

コンピュート・タイルにはRedwood Cove PコアとCrestmont Eコアが搭載されているが、IPCの改善はあまり見られない。これはIntelによれば、Redwood Coveは従来から「ティック」と呼ばれてきたものに近いという。つまり、第12世代および第13世代のAlder/Raptor Lakeプロセッサーに採用されているGolden CoveおよびRaptor Coveマイクロ・アーキテクチャと基本的に同じマイクロ・アーキテクチャとIPCということだ。
ティックでは、マイクロアーキテクチャのIPC向上に頼る代わりに、Intelは実績のあるアーキテクチャを使用して、より洗練されたより小さなプロセス(この場合はIntel4)の利点を引き出す。新しいIntel 4プロセスは、IntelのPCチップで以前使用されていたIntel 7ノードよりも、電圧/周波数カーブのどの点においても優れた性能を発揮する。Intelは、この設計でより高い電力効率を引き出すことに注力したと述べており、Pコアから急激な性能向上を期待すべきではないことは明らかだ。Intelは、Intel 4プロセスによって電力効率が20%向上したと述べているが、これは印象的なことだ。
Intelは、新しいタイル型設計に対応するため、メモリとキャッシュの帯域幅をコア単位とパッケージ単位の両方で改善するなど、いくつかの改良を行った。また、電力管理ユニットのテレメトリーデータも強化され、電力効率を改善し、スレッドディレクターに供給されるリアルタイムデータをより適切に生成することで、適切なワークロードが適切なタイミングで適切なコアに配置されるようになった。
IntelのCrestmont E-Coreマイクロアーキテクチャは、前世代のGracemontに比べてIPCが3%向上しているが、その多くは、AIワークロードの性能を向上させるVector Neural Network Instructions(VNNI)命令のサポートが追加されたことに起因している。また、Intelは分岐予測エンジンにも未指定の改良を加えている。
しかし、Crestmontには1つの大きな進歩がある:このCrestmontアーキテクチャは、4MBのL2キャッシュ・スライスと3MBのL3キャッシュを共有する2コアまたは4コアのクラスタへのeコアの配置をサポートしている。前世代のGracemontにはこの機能がなかったため、Intelはeコアを4コアのクラスタでしか使用できなかった。現在、Intelはコアあたり2倍のキャッシュ量を持つ、より小さなデュアルEコア・クラスターを切り出すことができ、これはまさに、SoCタイル上の低消費電力アイランドEコアに採用されたアプローチだ。これらのコアは、コンピュート・ダイ上の標準Eコアと同じCrestmontアーキテクチャを使用しているが、TSMC N6プロセス・ノード用に調整されている。
前世代と同様、各Eコアはシングルスレッドである。Intelはまた、L1キャッシュを64KBに倍増し、6ワイドデコードエンジン(レイテンシと消費電力を改善するためデュアル3ワイド)、5ワイドアロケート、8ワイドリタイアを採用している。
CrestmontコアはAMXやAVX-512をサポートしていないが、AVX10をサポートしている。そのため、このチップは対称型ISAをサポートしており、両方のタイプのコアがホストに対してISAサポートレベルを列挙することになる。Intelはまだ詳細を明らかにしていないが、CrestmontアーキテクチャがAVX10の最初のリビジョンをサポートしていることは分かっている。最終的には、IntelがAVX-512のサポートをPコアに追加できるようになる可能性がある。Intelがこのアプローチを完全に採用するかどうかは、今後の発表を待たなければならない。Crestmontは、BF16、FP16、AVX-IFMA、AVX-DOT-PROD-INT8もサポートしている。
Meteor Lake グラフィックス(GPU)タイル
Meteor Lakeの分離アーキテクチャの一環として、Intelはグラフィックスに別のタイルを使用することを選択した。Intelは、グラフィックスを分離するために興味深い路線を進んでおり、最も注目すべきは、IntelのArc Graphicsアーキテクチャのアップグレードによる搭載だ。IntelのMeteor Lake向け統合グラフィックスを支えるのは、IntelがXe-LPGと呼ぶ新しいグラフィックス・アーキテクチャだ(ここで燃料の話をしているわけではない)。Xe-HPGとして知られるIntelの現在のディスクリート・グラフィックス・アーキテクチャ(同社のArc GPUで使用)をベースにしており、Intelの第12世代Coreシリーズに搭載されているXe-LPアーキテクチャ・ベースのIris Xe統合グラフィックスと比較して、ワットあたり2倍の性能を発揮すると主張している。
Meteor Lakeのグラフィックスとメディア領域には多くの異なる要素があるが、その大部分はXe-LPGグラフィックス・アーキテクチャが配置されているグラフィックス・タイルに組み込まれている。TSMCのN6(6nm)で製造されるコンピュート・タイル(Intel4)やSoCタイルとは異なり、グラフィックス・タイルはTSMCのN5ノード(5nm)で製造され、これはAMDやNVIDIAのディスクリートGPUや統合GPUが使用するノードと同じ世代ファミリーである。

Meteor LakeとXe-LPGグラフィックス・プロセッサを搭載したグラフィックス・タイルにより、Intelは統合型フォームファクターでディスクリートレベルのパフォーマンスを約束する。より詳細な仕様を見ると、Intelは8 x Xeグラフィックス・コアに128ベクトル・エンジン(Xeコアあたり12)と8サンプラーを搭載しており、Intelの以前のXe LPグラフィックスと比較して1.33倍の増加となっている。また、4つのピクセルバックエンドがあり、Xe LPの3PBより改善されています。Intelはまた、Xe-LPG内のジオメトリー・パイプラインの数を2つへと倍増させ、Intelの統合グラフィックス・ラインナップとしては新しい8つの専用レイトレーシング・ユニット(RTU)も導入している。

IntelのXeコアの構成を見ると、前述の通り、バス幅256ビットのベクターエンジンが16基あり、各コアには192KBの共有L1キャッシュも搭載されている。各ベクトルエンジンは、1クロックあたり16個のFP32オペアンプと32個のFP16オペアンプ、そして1クロックあたり64個のINT8オペアンプを持つ共有FP64実行ポートを備えている。クロックあたり1つの専用FP64オペアンプユニットは、これまでのRaptor Lakeに見られたものより新しく、電力効率に関するMeteor Lakeの全体的な設計思想を共有している。
ユーザーにとってXe-LPGの全体的な体験を向上させるというIntelの目標の一環として、グラフィックはDX12に最適化され、IntelはXe-LPGにOut of Order Samplng(OoOS)を導入した。実行ユニット(EU)について話すとき、Intelの新しい現在の用語はXe Vector Engines、略してXVEであることは注目に値する。
| Meteor Lake (Xe-LPG) | Raptor Lake (Xe-LP) | Alder Lake GT1 (Xe-LP) | Tiger Lake GT2 (Xe-LP) | |
|---|---|---|---|---|
| プロセスノード | TSMC N5 | Intel 7 | Intel 7 | Intel 7 |
| ベクターエンジン/EU | 128 | 96 | 96 | 96 |
| ALU/シェーダー | 1024 | 768 | 768 | 768 |
| TMU | ? | 48 | 16 | 48 |
| ROP | ? | 24 | 8 | 24 |
| レイトレーシングユニット | 8 | – | – | – |
| TDP | ? | 15 W | 15 W | 15 W |
Intelは、Xe-LPG統合型グラフィックスの詳細な仕様については明らかにしていない。同様のスペックを持つ既存の統合型Intel Arcを見ると、Meteor Lake Xe LPGは、Arc A370Mのように64個のTMUと32個のROPを持ち、1024個のALUを持つ可能性がある。
Intelの統合Xeグラフィックスを以前のモバイル・アーキテクチャと比較すると、Meteor LakeはXe-LPG Arcベースのグラフィックスを通じて128 XVEを搭載しており、これは以前のXe-LP世代よりも1.33倍、つまり32 XVE/EUs増加している。実質的なシェーダーコアである算術論理演算ユニット(ALU)については、Xe-LPGが1024に増加し、Xe-LPGコアあたり128ALUとなった。前述の通り、IntelはTMUやROPなど、より細かい仕様については明らかにしていないが、Xe-LPと直接比較した場合、Xe-LPGでは新しい8つのRay Tracingユニットを搭載している。
一方、IntelのFoveros 3Dパッケージング技術では、メディアエンジンとディスプレイエンジンをグラフィックスタイルから分離することで、エンコードやデコード、ビデオ再生を行う際に、グラフィックスタイルをパワーアップする必要がなく、より消費電力の高いコアでワークロードを行うことができる。

IntelXe-LPGは、Xe LPの次のステップアップであり、性能と効率が向上している分野の1つは、より低い電圧周波数(V/F)カーブである。Intelはまた、より高速な周波数のためにパイプラインを最適化し、等電圧で最大2倍の性能を主張しており、Meteor Lakeのようなモバイル・プラットフォームでは、前世代と比較して最大20%の省電力化を達成することに重点を置き、さらなる可能性を追加している。
Meteor Lake SoCタイル

このSoCタイルは、低消費電力のTSMC N6プロセスで製造され、新しい次世代アンコアを搭載したタイルの中心的な通信ポイントとして機能する。SoCタイルが低消費電力使用に重点を置いていることから、Intelはこれを「低消費電力(ローパワー)アイランド」とも呼んでいる。このSoCタイルには、2つの新しいコンピュート・クラスタ、2つの低消費電力アイランドeコア、そしてIntelのニューラル・プロセッシング・ユニット(NPU)が搭載されている。
Intelは、メディア、ディスプレイ、画像処理ブロックをすべてGPUエンジンからSoCタイルに移し、GPUが低消費電力状態にある間にこれらの機能をSoCタイル上で動作させることで、電力効率を最大化するのに役立てた。また、GPUタイルはより高価なTSMC N3ノードで製造されているため、これらの性能に依存しないブロックを削除することで、IntelはGPUタイル上の高価なトランジスタをグラフィックス演算に有効活用できるようになった。このように、SoCタイルにはHDMI 2.1、DisplayPort 2.1、DSC 1.2aなどのディスプレイ・インターフェイスが搭載され、8K HDRとAV1エンコーディング/デコーディングもサポートしている。
SoCタイルはGPUタイルの隣に存在し、両者はダイの片側にあるダイ間(タイルとタイルの間)インターフェイスを介して通信する。上のアルバムで、このタイル間インターフェイスを見ることができる。インターコネクトの各側には、チップ間のデータ転送に必要な帯域幅を提供するプライマリ・メインバンド・インターフェースがある。この接続はFoveros 3Dシリコンの下を通るため、(PCBのような)有機基板を通る標準的なトレースよりもはるかに効率的な経路を提供する。さらに、セカンダリ接続は、クロック、テスト、デバッグ信号用のインターフェイスと、タイル間の専用電源管理コントローラー(PMC)インターフェイスを提供する。
GPUは、分離された高性能キャッシュコヒーレント・ネットワーク・オン・チップ(NOC)に接続されており、NPU、低消費電力eコア、メディアエンジンおよびディスプレイエンジンを接続し、同じバス上に存在するメモリコントローラによって提供されるメモリ帯域幅に効率的にアクセスできるようにしている。このNOCは、タイルの反対側にある別のタイル間インターフェイスを介して、コンピュート(CPU)タイルにも接続される。
Intelには、別のタイル間インターフェイスを介してI/Oタイルに接続する、2番目の低消費電力IOファブリック(コヒーレントではない)がある。このIOファブリックには、Wi-Fi 6Eおよび7、Bluetooth、セキュリティ・エンジン、イーサネット、PCIe、SATAなど、他の優先順位の低いデバイスも含まれている。
そのため、Intelはダイ上に2つの独立したファブリックを持つことになるが、これらは互いに通信できなければならない。Intelは、2つのファブリック間のトラフィックをバッファリングするI/Oキャッシュ(IOC)で2つを接続した。これにより、2つのバス間のクロスファブリック通信にレイテンシ・ペナルティが発生するが、追加レイテンシは、優先度の低いI/Oファブリックの性能目標内に収まる。
Intelは、この新しいファブリック階層を次世代アンコアと呼んでいる。上の画像アルバムにあるように、前世代のチップ設計では、デバイスをI/Oファブリック上に配置し、分離されたメモリコントローラに接続されたシステムエージェントコントローラを介して通信していた。しかし、このシステム・エージェントは、CPUコアを接続するリング・ファブリックに流れるメモリ帯域幅も制御していたため、不要な競合や帯域幅の制約が生じていた。NPUや低消費電力のEコアなど、帯域幅を多く消費するデバイスをI/Oファブリックに追加するには、スケーラビリティが不十分だった。
次世代アンコアは、これらの問題を解決している。Intelはまた、各タイルに独立した電源管理コントローラー(PMC)を追加し、電圧と周波数を独立して制御できるようにした。しかし、これらはすべて、独立したファブリックを制御するSoCタイル上の2つのPMCに接続されているため、より大きなエネルギー節約を可能にする電源管理階層が形成されている。また、すべてのタイルには、帯域幅とサービス品質要件に基づいて調整されるダイナミック・ファブリック周波数とともに、電圧を密接に変調するための独自のDLVRが含まれている。
Meteor Lake I/Oタイル
しかし、Intelの次世代アンコア設計手法に欠点がないわけではない。SoCタイルにはDDR5メモリとPCIeコントローラが搭載されているが、これらの外部インターフェイスはダイの2辺にしか配置できず、残りの2辺は他のタイルとの通信に使用される。このため、ダイの端(ショアライン)に配置できる接続数には限界がある。この問題を解決するため、IntelはセカンダリI/Oタイルを作成し、追加のPCIeレーンやThunderbolt 4外部インターフェイスへの接続に余裕を持たせた。SoCタイルのアスペクト比を変更するなどの他のオプションは、既存のソケット・インターフェースとの互換性の問題により機能しない。
I/Oタイルは4つのMeteor Lakeタイルの中で最も小さく、TSMC N6プロセスで製造される。このタイルには、Thunderbolt 4(そう、バージョン5ではない)やPCIe Gen 5.0などのI/O機能が搭載されている。Intelは、必要なコネクティビティの量に応じて、製品ごとに異なるサイズのI/Oタイルを使用する。
低消費電力アイランドEコア
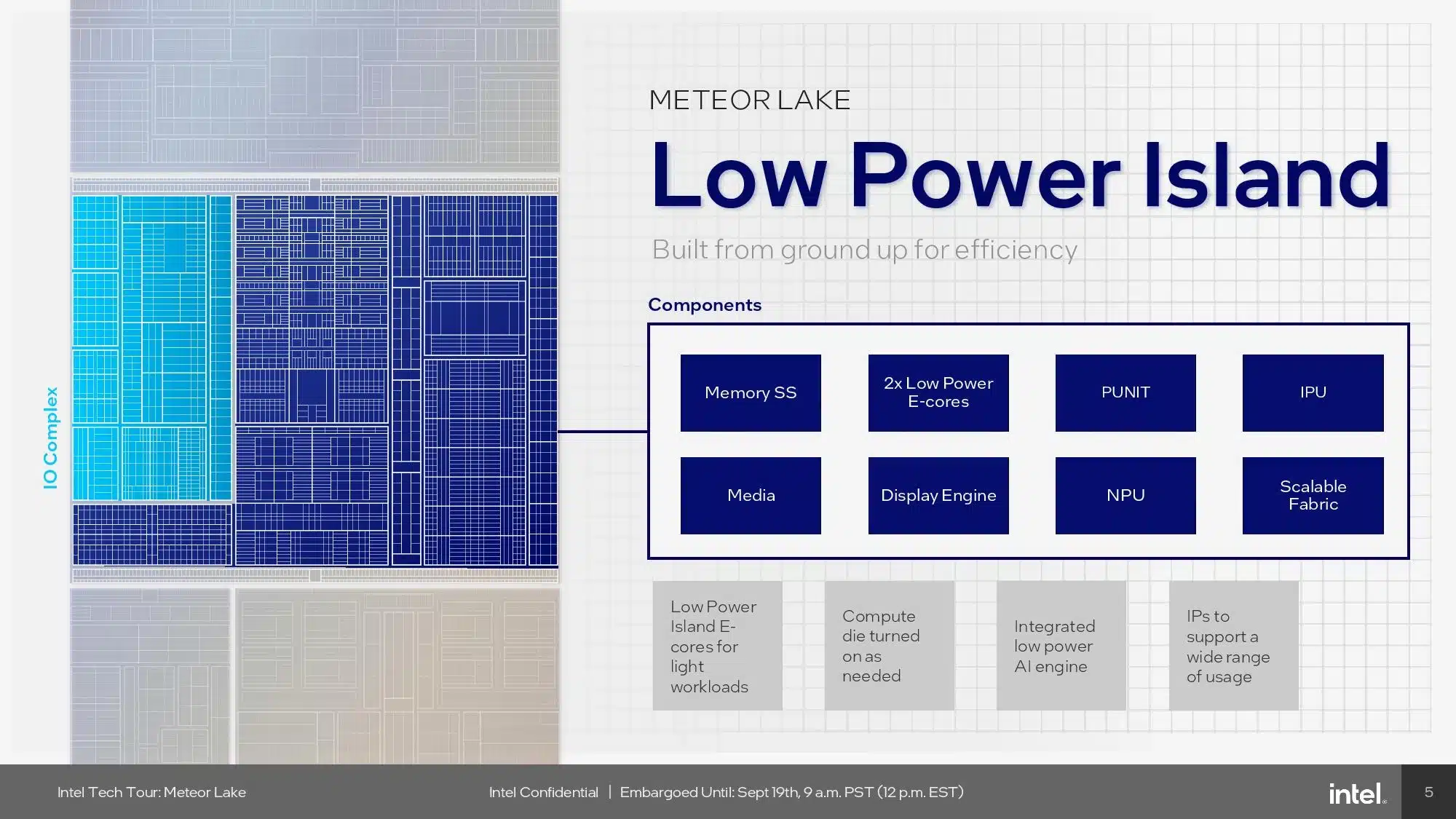
IntelのSoCタイルには、コンピュート・タイルのセクションで説明したのと同じCrestmontマイクロアーキテクチャを採用した2つの低消費電力Eコアが搭載されている。これらの低消費電力コアは、ビデオの再生中など、特定の軽い使用モードでオペレーティング・システムを実行することができ、コンピュート・タイル全体を低消費電力モードにしてエネルギーを節約することができます。さらに、このコアは、コンピュート・タイル上のクアッドコアEコア・クラスタの重さを必要としない、日常的な軽いバックグラウンド・タスクの多くを処理できるため、個々のコアをより頻繁にスリープさせることができる。Intelは、これらのコアの性能について詳細を明らかにしていないが、TSMCの低消費電力N6ノード向けに特別にチューニングされていることは分かっている。
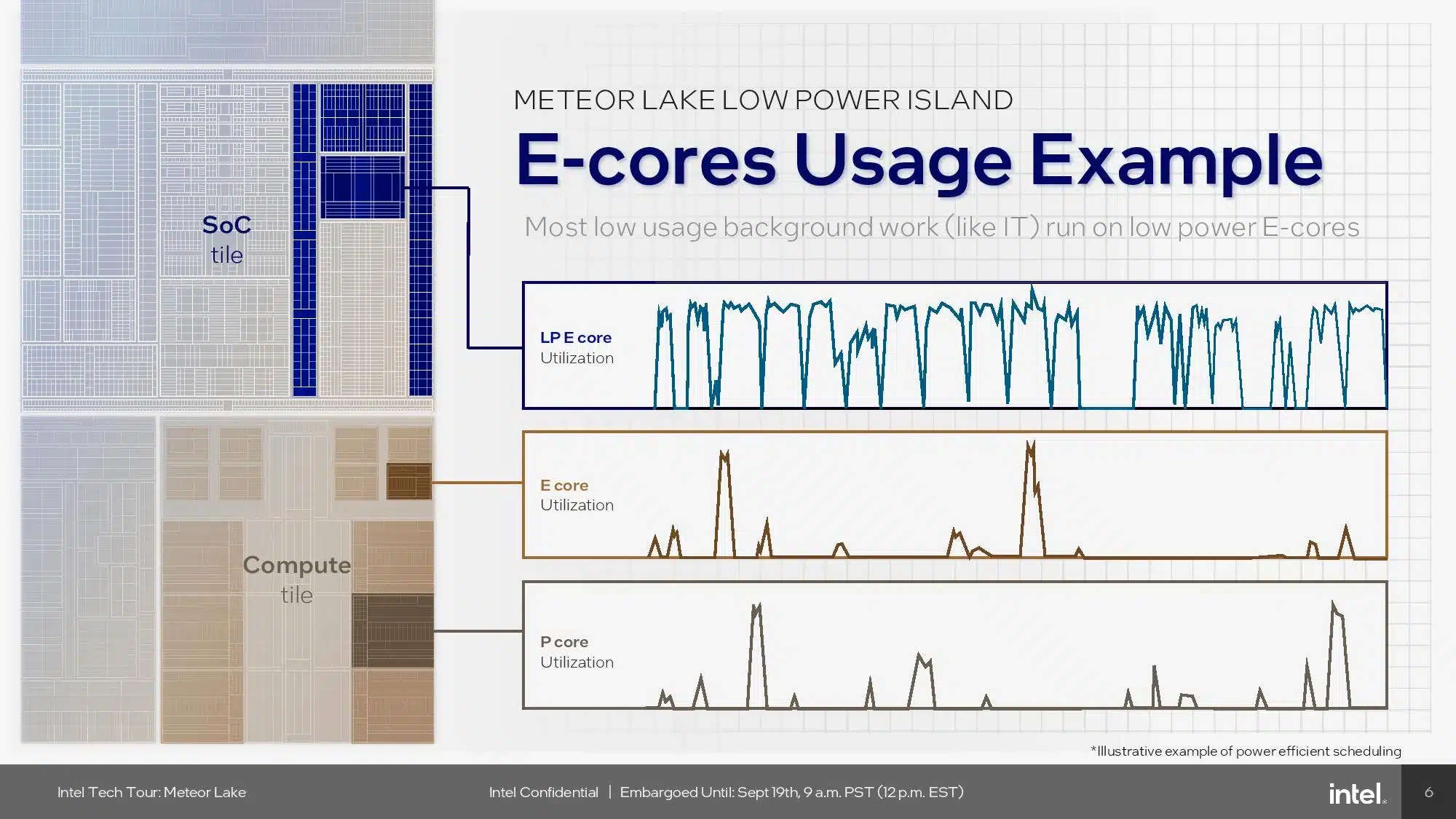
Intelはまた、スレッド・ディレクターが、特定のコア・タイプを特にターゲットにしていないスレッドをどこに配置するかを決定する際に、低消費電力のEコアを最初に優先するようになったことも示した。しかし、スレッドが低電力Eコアで実行され始め、より多くの計算能力が必要であることが明らかになった場合、オペレーティング・システムはそのスレッドをより高速なコアに移動させる。これまでThread Directorは、どのようなワークロードに対してもPコアを第一優先としていました。この低電力eコアを優先させるという決定は、性能応答性への影響について疑問を投げかけるものだが、チップが我々のラボに到着するまで、その影響の全容はわからない。
ニューラルプロセッシングユニット(NPU)

Intelのニューラル・プロセッシング・ユニット(NPU)は、持続的なAI推論ワークロード(トレーニングではない)を実行するために特別に設計された専用のAIエンジンだが、Meteor Lakeには他にも様々なAIワークロードを実行できるCPU、GPU、GNAエンジンも含まれている。NPUは主にバックグラウンドタスク用で、GPUはより重い並列化作業に対応する。一方、CPUは低レイテンシーの軽い推論作業に対応する。
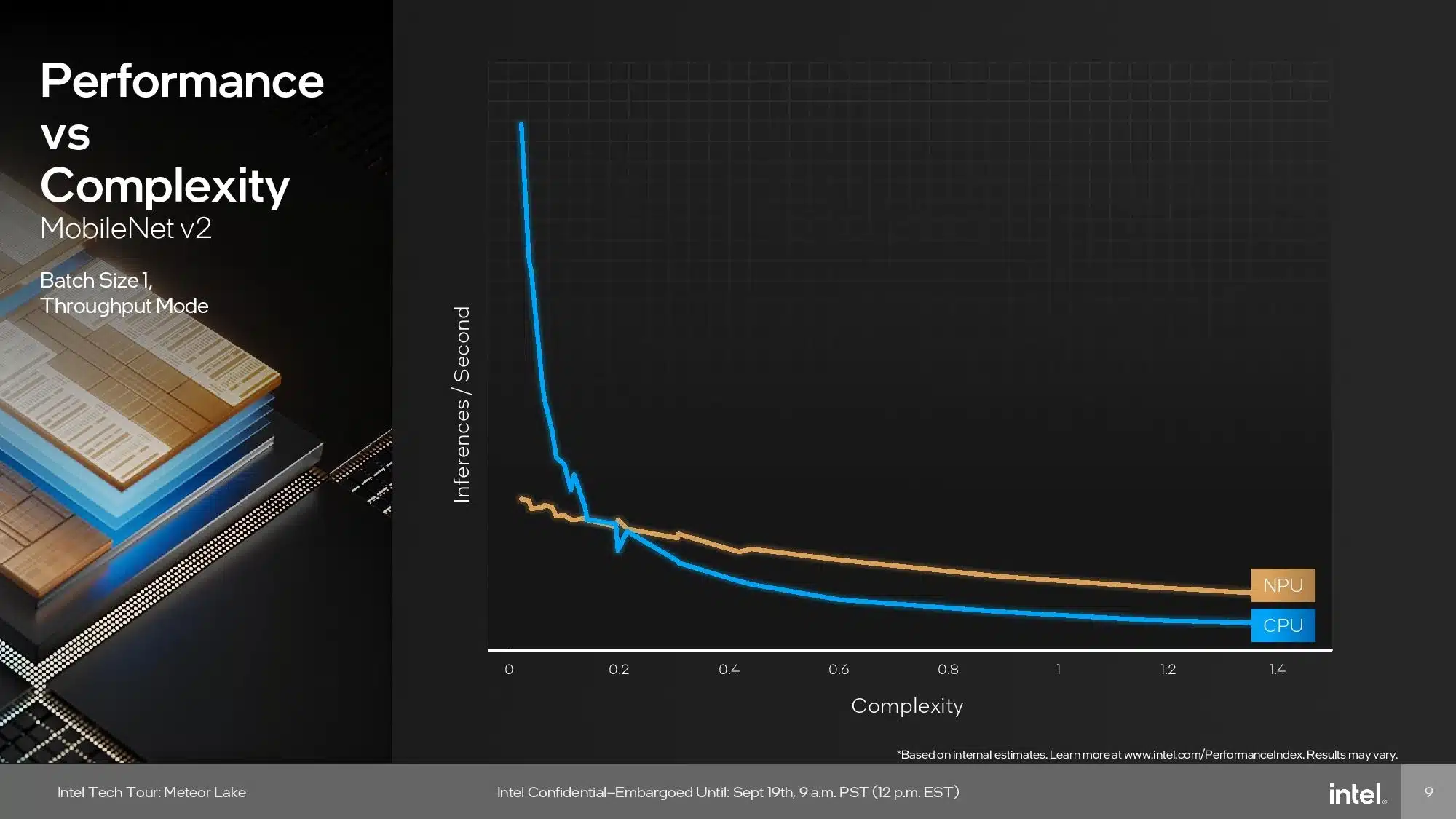
AIワークロードの中には、NPUとGPUの両方で同時に実行できるものもあり、Intelは、開発者が手元のアプリケーションのニーズに基づいて、異なるコンピュート・レイヤーをターゲットにできるメカニズムを実現した。これは最終的に、より低い消費電力でより高い性能を実現することになり、実際には8倍削減できる–AIアクセラレーションNPUを使用する主な目標だ。
ChatGPTのような大規模な言語モデルのトレーニングなど、今日のより強力なAIワークロードの多くは、強力な計算能力を必要とし、データセンターで実行され続けるだろう。しかし、Intelは、オーディオ、ビデオ、画像処理のような一部のAIアプリケーションは、PC上でローカルに処理されるようになり、レイテンシ、プライバシー、コストが改善されるとしている。
NPUアーキテクチャには、推論パイプライン用の固定ファンクション・アクセラレータと、プログラマブルなSHAVE DSPが混在している。以下は、Intelのエンジンに関する説明である:
- ホスト・インターフェースとデバイス管理 – デバイス管理エリアは、マイクロソフト・コンピュート・ドライバー・モデル(MCDM)と呼ばれるマイクロソフトの新しいドライバー・モデルをサポートしています。これにより、Meteor Lake NPUは、セキュリティに重点を置いた最適な方法でMCDMをサポートすることができます。一方、メモリ管理ユニット(MMU)は、マルチコンテキストの分離を提供し、高速で低消費電力な状態遷移のための電力とワークロードのスケジューリングをサポートします。
- マルチエンジンアーキテクチャ – NPUは、2つのニューラル演算エンジンが1つのワークロードで一緒に動作したり、それぞれのワークロードで独立して動作したりするマルチエンジンアーキテクチャで構成されています。このニューラル・コンピュート・エンジンには、主に2つのコンピュート・コンポーネントがあります:
- 推論パイプライン – これは効率的なコンピューティングの核となるもので、データの移動を最小限に抑え、一般的で高負荷のタスクに対して固定関数演算を行うことで、ニューラルネットワークの実行電力を節約します。計算の大部分は推論パイプラインで行われ、標準的なニューラルネット ワーク操作をサポートする固定関数ハードウェアのパイプラインです。パイプラインは、MAC(Multiply Accumulate)アレイ、活性化関数ブロック、データ変換ブロックから構成される。
- SHAVE DSP – AI用に特別に設計された高度に最適化されたVLIW DSP(Very Long Instruction Word/Digital Signal Processor)です。ストリーミング・ハイブリッド・アーキテクチャー・ベクター・エンジン(SHAVE)は、推論パイプラインおよびダイレクト・メモリー・アクセス(DMA)エンジンとパイプライン接続することができ、NPU上で並列に実行される真のヘテロジニアス・コンピュートにより、パフォーマンスを最大化します。
- DMAエンジン – 最大限の効率とパフォーマンスを実現するために、データ移動を最適化します。
Intelのチップは現在、オーディオとビデオ処理機能の低消費電力AI推論にガウシアン・ニューラル・アクセラレーター(GNA)ブロックを使用しており、GNAユニットはMeteor Lakeにも残る。しかし、Intelによれば、すでにGNAに特化したコードの一部をNPUで実行し、より良い結果を得ており、Intelが将来のチップで完全にNPUに移行し、GNAエンジンを削除することを重々示唆しているという。
IntelのNPUはDIrectMLをサポートしているが、ONNXとOpenVINOもサポートしている。しかし、ONNXとOpenVINOは、最大限の性能を引き出すために、ソフトウェア開発者がより的を絞った開発を行う必要がある。
Intelのチップだけでなく、競合するAMDのRyzen 7040シリーズプロセッサーにもすでに専用のAIエンジンが搭載されている。しかし、現在のところ、メインストリーム向けのアプリケーションはそれほど多くない–今のところ、鶏と卵のような状況だ。Intelは2025年までに数千万台のデバイスにNPUを搭載する計画であり、AMDも同様の設計決定を下していることから、ソフトウェアイネーブルメントへの取り組みが加速することが予想される。
Intelによると、待望のIntel4プロセスは予想以上の歩留まりを記録しており、次世代Core Ultra「Meteor Lake」プロセッサーの製造に向けた強固な基盤が整ったことを示している。タイル型/チップレット型アーキテクチャの追加は、Intelにとって分水嶺となる瞬間であり、同社初の分割ダイ・チップ設計を市場に投入することになる。破壊的な3D Foverosパッケージング技術によって強化されたコンポーネントの驚異的な再アーキテクチャーと、AIワークロードの推進に焦点を当てた新しいMeteor Lakeチップは、有望に見える。
Intelは、性能指標やSKUの詳細については明らかにしていないが、電力効率の20%向上については確実なようだ。
Sources





コメントを残す