
2020年9月25日に、AMDがI/Oダイ(IOD)に垂直方向に積層した機械学習(ML)アクセラレータを提供するユニークなプロセッサの特許を申請していた事が判明した。この特許は、AMDがFPGA(Field Programmable Gate Arrays)またはGPUベースの機械学習アクセラレータを統合した特殊用途またはデータセンター向けシステムオンチップ(SoC)の構築を計画している可能性を示している。
Free Patents Online : DIRECT-CONNECTED MACHINE LEARNING ACCELERATOR
この特許から、AMDがCPUにキャッシュを追加できるようになったように、プロセッサのI/Oダイの上にFPGAやGPUを追加することも考えられる。しかし、より重要なのは、この技術によって、同社は将来的にCPU SoCに他の種類のアクセラレータを追加することができるようになるということだ。ただ、特許を取得した事は、この技術を使った設計が市場に出ることを保証するものではない。しかし、同社がどのような方向性で研究開発を進めているかを知ることができ、そしてこの技術、またはそれに近い派生技術に基づく製品が市場に出る可能性を予想することが出来る。
I/Oダイの上にAI/MLアクセラレーターを積層させる革新的技術
「Direct-connected machine learning accelerator」(直接接続された機械学習アクセラレーター)と題されたAMDの特許は、AMDが自社のスタッキング技術を利用してI/OダイにMLアクセラレータを追加する方法を、かなりオープンに説明している。どうやらAMDの技術では、特殊なアクセラレータポートを持つI/Oダイの上に、機械学習ワークロード用のFPGA(Field-Programmable Processing Array)やCompute GPUを追加することが可能なようだ。
AMDは、アクセラレータを追加する方法として、独自のローカルメモリを持つアクセラレータ、IODに接続されたメモリを使うアクセラレータ、システムメモリを使うアクセラレータ、IODの上に積み重ねる必要がないアクセラレータの3つのシナリオを挙げている。
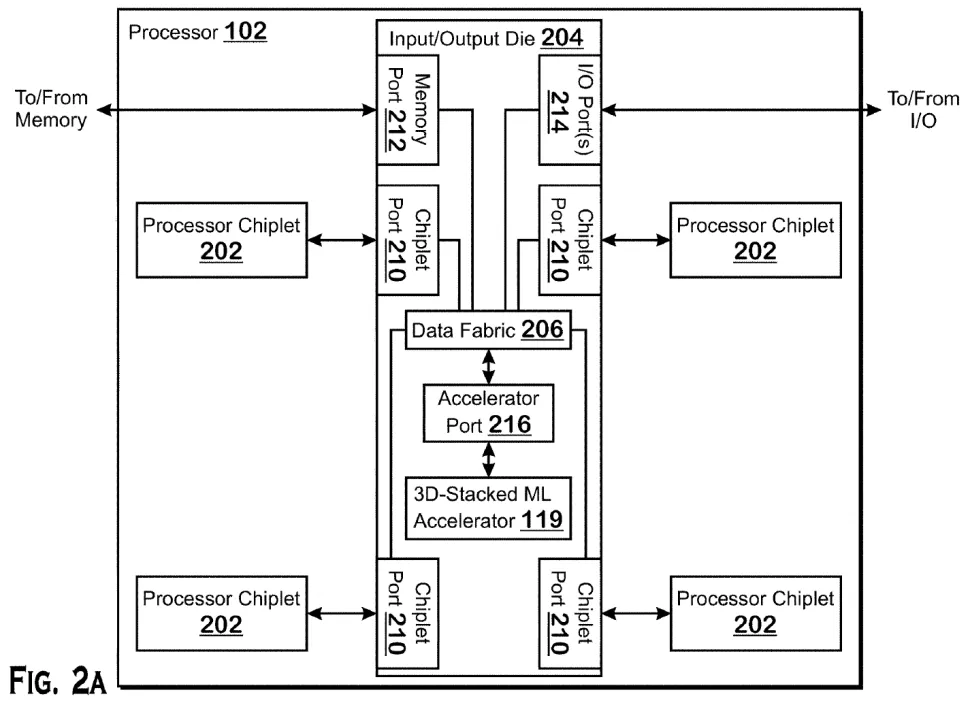
機械学習技術は、将来のデータセンターで広範囲に利用されるようになると予想されており、競争力を高めるために、AMDは自社のチップを使用してMLワークロードを高速化する必要がある。CPUのI/Oダイの上に機械学習アクセラレータを積み重ねることで、高価なカスタムML最適化シリコンをCPUチップレットに統合することなく、MLワークロードを大幅に高速化することができる。また、密度、消費電力、データスループットの面でもメリットがあるという。
この特許は、AMDとXilinxの経営陣が、AMDがXilinxを買収することで最終合意に達したと発表する1カ月余り前の2020年9月25日に申請されている。特許は2022年3月31日に公開され、発明者としてAMDのフェローであるMaxim V. Kazakovが記載されている。AMDがXilinx IPを採用した最初の製品は、2023年に予定されている。
AMDがその特許を実際の製品に使用するかどうかはわからないが、ほとんどすべてのCPUにML機能を追加できるという革新性から、このアイデアは採用される可能性が高い物と思われる。
AMDの第5世代EPYC「Turin」プロセッサのcTDP(configurable thermal design power)は600Wにすると噂されており、これは現世代のEPYC 7003シリーズ「Milan」プロセッサのcTDPより2倍以上高いことは注目に値するだろう。ちなみに第4世代および第5世代EPYC CPU向けのAMDのSP5プラットフォームでは、最大700Wの電力をプロセッサーに供給することが出来る仕様となっている。
AMDの将来のデータセンター向けCPUがどれほどの電力を必要とするかはわからないが、プロセッサ・パッケージにMLアクセラレータを追加すれば、消費量が増えることは間違いない。そのため、次世代サーバープラットフォームが、実際にアクセラレータを積層したCPUをサポートできるようにすることは、省電力化の観点からも非常に意味があるだろう。
究極のデータセンター向けSoCの構築
AMDは、2006年にATI Technologiesを買収して以来、データセンター向け高速処理装置(APU)について様々取り組んできている。この15年間で、一般的なワークロードには汎用のx86コアを、高度な並列ワークロードにはRadeon GPUを統合した複数のデータセンターAPUプロジェクトに取り組んでいるという。
この2つのプロジェクトはいずれも実現していない。理由としては、AMDのBulldozerコアに競争力がなかったため、限られた需要しか見込めない大型で高価なチップを作ることにあまり意味がなかったからだ。また、もう1つの理由は、従来のRadeon GPUがデータセンター/AI/ML/HPCのワークロードに必要なすべてのデータ形式と命令をサポートしておらず、AMD初のコンピュート中心のCDNAベースGPUが2020年に登場したばかりだったからだ。
しかし、AMDが競争力のあるx86マイクロアーキテクチャ、コンピュート指向のGPUアーキテクチャ、XilinxのFPGAポートフォリオ、Pnesandoのプログラマブルプロセッサの技術を持っている今、これらの多様なIPブロックを単一の大型チップに入れることはあまり意味のないことかも知れない。それどころか、TSMCが提供する先進的なパッケージング技術とAMD独自のInfinity Fabric相互接続技術を利用すれば、汎用x86プロセッサ・チップレット、I/Oダイ、GPUまたはFPGAベースのアクセラレータを搭載したマルチタイル(またはマルチチップレット)モジュールを構築する方がはるかに理にかなっているのである。
実際、多様なIPを内蔵した大型モノリシックCPUよりも、マルチチップレットのデータセンタープロセッサを構築する方が理にかなっている。たとえば、マルチチップのデータセンターAPUでは、TSMCのN4Xという性能最適化ノードで製造したCPUタイルと、N3Eという密度最適化プロセス技術で製造したGPUまたはFPGAアクセラレータタイルを利用することができる。
ユニバーサルアクセラレータポート
この特許のもう一つの重要な部分は、FPGAやコンピュートGPUを使用して機械学習ワークロードを加速するように設計された特定の実装と言う面ではなく、あらゆるCPUに特殊目的のアクセラレータを追加出来るという原理的な面にある。アクセラレータポートは、AMDのI/Oダイに提示されるユニバーサルインターフェイスとなるため、いずれAMDはクライアントやデータセンターアプリケーション向けのプロセッサに他の種類のアクセラレータを追加することができるようになるだろう。
「本明細書の開示に基づき、多くのバリエーションが可能であることを理解されたい」と、特許の説明には書かれている。「適切なプロセッサは、例として、汎用プロセッサ、特殊目的プロセッサ、従来のプロセッサ、グラフィックスプロセッサ、機械学習プロセッサ、[DSP、ASIC、FPGA]、および他のタイプの集積回路(IC)を含む。[中略)このようなプロセッサは、ハードウェア記述言語(HDL)命令やネットリストを含む他の中間データ(コンピュータ可読媒体に格納できるような命令)の処理結果を用いて製造工程を構成することによって製造することができる。」と述べている。
FPGA、GPU、DSPは現在でもさまざまな用途に利用できるが、データセンター向けのデータ処理装置(DPU)などは、今後ますます重要性を増していくだろう。しかし、データセンターがより多くの種類のデータをより高速に処理するように変化するにつれ(AppleがProRes RAWのようなアプリケーション固有のアクセラレーションをクライアントSoCに統合するように、クライアントPCも同様)、アクセラレータがより一般的になってきている。つまり、それらを必要な時に、すべてのサーバープロセッサに追加する方法が必要になる。そして実際、AMDの今回明らかになった特許は、それを可能にしてくれるだろう。







コメントを残す