AMDは本日開催された「AMD Advancing AI」イベントで、AIアクセラレーター「Instinct MI300X」と世界初のデータセンター向けAPU「Instinct MI300A」を発表した。
このデータセンター向けAPUは、24個のZen 4 CPUコアとCDNA 3グラフィックス・エンジン、8スタックのHBM3を融合したチップを作成するために、その多くが3Dスタックされた合計13個のチップレットをブレンドしている。全体として、このチップは1,530億トランジスタを搭載しており、AMDが投入したチップの中で最大のものとなっている。
AMDによると、Instinct MI300X GPUは、AI推論ワークロードにおいてNVIDIA H100の最大1.6倍の性能を発揮し、トレーニングワークにおいても同等の性能を発揮する。さらに、これらのアクセラレータは、NVIDIAのGPUの2倍以上のHBM3メモリ容量(1つあたり192GB)を搭載しており、MI300Xプラットフォームは、NVIDIA のH100 HGXよりも大きなモデルを実行するだけでなく、システムあたり2倍以上のLLM数をサポートすることが可能だという。
AMD Instinct MI300Aは、MI300Xと同じ設計をベースにしているが、GPUコアの一部を削減する一方で、CPUコアを設計に混ぜている。AMDは、このチップは一部のワークロードでNVIDIA のH100 GPUより最大4倍の性能を発揮し、ワット当たりの性能は2倍であるとしている。
Instinct MI300X

MI300Xは、AMDのチップレットベースの一つの頂点だ。、8つの12HiスタックのHBM3メモリと、XCDと呼ばれる8つの3Dスタックされた5nm CDNA 3 GPUチップレットを、AMDの現在成熟しているハイブリッド・ボンディング技術を使って接続された4つの6nm I/Oダイ上に融合させている。
その結果このチップは、304個のコンピュートユニット、192GBのHBM3容量、5.3TB/秒の帯域幅を持つ。このアクセラレーターはまた、256MBのInfinity Cacheを搭載しており、チップレット間の通信を促進する共有L3キャッシュ層として機能する。AMDは、チップレットを結合するパッケージング技術を「3.5D」と呼んでいる。これは、3DスタックされたGPUとI/Oダイをハイブリッド結合で組み合わせ、モジュールの残りの部分を標準的な2.5Dパッケージと組み合わせたものである。

MI300Xアクセラレーターは、AMDの生成AIプラットフォームで8つのグループで動作するように設計されており、Infinity Fabricインターコネクトを介したGPU間の896GB/秒のスループットによって促進される。このシステムは、合計1.5TBのHBM3メモリーを搭載し、最大10.4ペタフロップスの性能(BF16/FP16)を発揮する。このシステムは、OCP Universal Base Board(UBB)設計標準に基づいて構築されているため、導入が容易な点も特徴だ。
AMDのMI300Xプラットフォームは、NVIDIAのH100 HGXプラットフォーム(BF16/FP16)と比較して、メモリ容量が2.4倍、演算能力が1.3倍向上している。AMDはMI300Xプラットフォームに400GbEネットワーキングを搭載し、さまざまなNICをサポートしている。

AMDは、HPCワークロードの理論上のピークFP64およびFP32ベクトル・マトリックス・スループットがH100の最大2.4倍、AIワークロードの理論上のピークTF32、FP16、BF16、FP8、INT8スループットが最大1.3倍であることを示し、多くのパフォーマンス指標を共有した。ただし、これについては第三者機関の評価が必要だろう。

MI300Xの膨大なメモリ容量と帯域幅は、推論に理想的である。AMDは、1,760億パラメータのFlash Attention 2モデルを使用して、トークン/秒のスループットでNVIDIA H100に対して1.6倍の性能優位性を主張し、700億パラメータのLlama 2モデルを使用して、1.4倍のチャットレイテンシの優位性を強調した(2Kシーケンス長/128トークンのワークロードの開始から終了まで測定)。

AMDのMI300Xプラットフォームは、300億パラメーターのMPTトレーニング負荷でH100 HGXシステムとほぼ同じ性能を発揮したが、このテストはアクセラレーターを1対1で比較するものではないことに注意が必要だ。その代わり、このテストでは8つのアクセラレータのグループを互いに戦わせるため、プラットフォームレベルの能力がより制限要因になる。

加えて、AMDはMI300Xプラットフォームのメモリ容量の優位性により、H100システムよりも最大2倍の30Bパラメータの学習モデルと70Bパラメータの推論モデルをホストできるとも主張している。さらに、MI300Xプラットフォームは最大70Bのトレーニングモデルと290Bの推論モデルをサポートすることができ、これはH100 HGXがサポートするモデルの2倍に相当する。
当然ながら、NVIDIAの近日リリース予定のH200 GPUは、メモリ容量と帯域幅の面でより競争力が高まるが、演算性能は同程度にとどまるだろう。NVIDIAがこれらのGPUの出荷を開始するのは来年になるため、MI300Xとの競合比較はまだ先のことになる。
Instrinct MI300A

AMD Instinct MI300Aは、世界初のデータセンター向けAPUで、CPUとGPUを同じパッケージに搭載しており、CPUとGPUを別々のチップパッケージに搭載し、連動して動作するNVIDIAのGrace Hopper Superchipsと直接競合することになる。MI300AはすでにEl Capitanスーパーコンピューターに搭載されており、AMDはこのシリコンをパートナーに出荷している。
MI300Aは、MI300Xと基本的な設計と手法は同じだが、EPYCやRyzenプロセッサと同じ8個のZen 4 CPUコアを搭載した3個の5nmコアコンピュート・ダイ(CCD)に置き換え、XCD GPUチップレットのうち2個を置き換えた。
これにより、MI300Aは24個のスレッドCPUコアと228個のCDNA 3コンピュートユニットを6個のXCD GPUチップレットに搭載することになる。MI300Xと同様に、すべてのコンピュート・チップレットは4つのI/Oダイ(IOD)にハイブリッド結合されており、標準的なチップ・パッケージング技術よりもはるかに優れた帯域幅、レイテンシ、エネルギー効率を実現している。
AMDは、MI300Xに使用されていた8基の12Hiスタックの代わりに8基の8Hi HBM3スタックを使用することでメモリ容量を削減し、容量を192GBから128GBに削減した。ただし、メモリ帯域幅は5.3TB/秒のままだ。AMDによれば、メモリ容量の削減は電力や熱の制限によるものではなく、対象とするHPCやAIのワークロードに合わせてチップを調整するためだという。とはいえ、128GBの容量と5.3TB/秒のスループットは、いずれもNVIDIAのH100 SXM GPUが提供するものより1.6倍多い。
MI300AのデフォルトのTDPは350Wだが、最大760Wまで設定可能だ。AMDは、使用状況に応じてチップのCPUとGPUの間で動的に電力を配分し、性能と効率を最適化する。
メモリ空間はCPUとGPUで共有されるため、データ転送が不要になる。この技術は、ユニット間のデータ転送をなくすことで性能とエネルギー効率を高めるとともに、コーディングの負担を軽減する。MI300Xと同様、このチップには中央に256MBのインフィニティ・キャッシュがあり、チップを流れるデータの帯域幅とレイテンシの確保に役立っている。
AMDは、FP64 Matrix/DGEMMおよびFP64/FP32 VectorのTFLOPSにおいて、H100の1.8倍の優位性を主張している。また、TF32、FP16、BF16、FP8、INT8においてもH100と同等であるとしている。


AMDは、OpenFOAMのHPCバイクテストにおいて、MI300AがNVIDIAのH100よりも4倍高速であると主張しているが、この比較は理想的なものではない:H100はGPUであるのに対し、MI300AはCPUとGPUが混在しているため、メモリアドレス空間が共有され、メモリ負荷の高いこのワークロードにおいて本質的な優位性を発揮する。同じくCPUとGPUを密結合実装したNVIDIA Grace Hopper GH200 Superchipとの比較の方がここでは良いだろうが、AMDによれば、NVIDIAのチップのOpenFOAMの結果は公表されていないとのことだ。
AMDは、NVIDIAのGH200とのパーフ・パー・ワット比較データを提示し、2倍の優位性を強調したが、この結果はH200に関する公開情報に基づくものである。AMDはまた、Mini-Nbody、HPCG、GromacsベンチマークにおいてH100との比較を強調し、それぞれ1.2倍、1.1倍、1.1倍のリードを主張した。このベンチマークでも、GH200との比較がより理想的だろう。
アーキテクチャ

MI300は、コンピューティング、メモリ、通信のレイヤーケーキであり、3スライスのシリコンの高さがあり、これらのスライス間で17テラバイトものデータを縦に流すことができる。その結果、ある種の機械学習に不可欠な計算速度が3.4倍も向上する。このチップは、NVIDIAのGrace-HopperスーパーチップやIntelのスーパーコンピュータ用アクセラレータPonte Vecchioなど、競合するアプローチと対照的であると同時に類似している。
MI300Aは、3個のCPUチップレット(AMDの専門用語でコンピュート・コンプレックス・ダイ、CCDと呼ばれる)と6個のアクセラレータ・チップレット(XCD)を4個の入出力ダイ(IOD)の上に積み重ね、それらをスーパーチップを囲む8個の高帯域幅DRAMスタックにつなぐシリコンの一部で構成されている。対して、MI300Xは、CCDの代わりにさらに2つのXCDを搭載し、アクセラレーター専用システムとなっている。シリコン平面内のトランジスタのスケーリングが鈍化する中、3Dスタッキングは、同じ面積により多くのトランジスタを搭載し、ムーアの法則を前進させ続けるための重要な手法と考えられている。
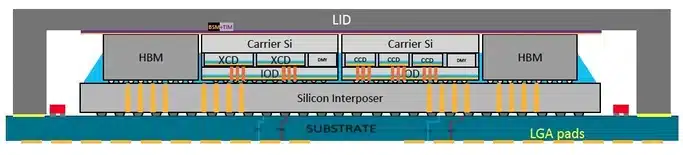
統合は、SoIC (system on integrated chips) とCoWoS (chip on wafer on substrate)という2つのTSMC技術を使って行われる。後者は、ハイブリッド・ボンディングと呼ばれる、はんだを使わずに各チップの銅パッドを直接つなぐ方法で、より小さなチップをより大きなチップの上に積み重ねる。これは、AMDのV-Cache(最高級CPUチップレット上にスタックするキャッシュ・メモリ拡張チップレット)の製造に使用されている。前者のCoWosは、インターポーザーと呼ばれる、高密度インターコネクトを内蔵するために作られたより大きなシリコン片にチップレットを積み重ねる。
最大のライバルであるNVIDIAのアプローチには、類似点と相違点の両方がある。NVIDIAがHopperアーキテクチャで行ったように、AMDのアクセラレーター・アーキテクチャであるCDNA3は、TF32と呼ばれる切り捨てられた32ビット数と、2つの異なる形式の8ビット浮動小数点数で計算する機能を追加した。後者の属性は、大規模な言語モデルなど、トランスフォーム・ニューラル・ネットワークの特定の部分のトレーニングを高速化するために使用される。また、4:2スパースと呼ばれる、ニューラルネットワークのサイズを縮小するスキームも含まれている。
もうひとつの類似点は、CPUとGPUの両方が同じパッケージに含まれていることだ。多くのAIコンピューター・システムでは、GPUとCPUは4対1の割合で別々にパッケージされたチップとして配備されている。これらを1つのスーパーチップに統合する利点の1つは、CPUとGPUの両方が同じキャッシュと広帯域DRAM(HBM)に高帯域幅でアクセスでき、データの読み書きの際に互いにつまずくことがないことだ。
NVIDIAのGrace-Hopperは、NVIDIAのNVIDIA NVLink Chip-2-Chipインターコネクトを通じてGrace CPUとHopper GPUをリンクする、このようなスーパーチップの組み合わせである。AMDのMI300Aも同様で、Genoaライン用に設計された3つのCPUダイと、AMD Infinity Fabricインターコネクト技術を使用した6つのXCDアクセラレータを統合している。
しかし、Grace HopperとMI300を何気なく見てみると、大きな違いがあることがわかる。GraceとHopperはそれぞれ、コンピュート、I/O、キャッシュといったオンチップに必要なすべてのシステム機能ブロックを統合した個別のダイである。これらは水平方向にリンクしており、フォトリソグラフィ技術の限界に近い大きさである。
AMDは、数世代前のCPUやライバルのIntelが3D積層型スーパーコンピューター・アクセラレーター「Ponte Vecchio」で採用している、異なるアプローチをとった。このコンセプトは、システム・テクノロジー協調最適化(STCO)と呼ばれている。つまり、設計者はまずチップを機能に分解し、どの機能にどの製造技術が必要かを決定する。
機能を分割すると、MI300に関わるシリコンの断片はすべて小さい。最も大きいI/Oダイはホッパーの半分もない。また、CCDはI/Oダイの約1/5の大きさしかない。小さなサイズは大きな違いを生む。一般的に、チップは小さい方が歩留まりが良い。つまり、1枚のウェハーで、大型のチップよりも小型のチップを使用する割合が高くなるのだ。

AMDは、TSMCの3DハイブリッドボンディングSoICを活用し、CPU CCD(コアコンピュート・ダイ)やGPU XCDなど、さまざまな演算素子を4つのI/Oダイの上に3Dスタックしている。各I/Oダイは、2つのXCDまたは3つのCCDを搭載できる。各CCDは既存のEPYCチップと同じで、それぞれ8個のハイパースレッドZen 4コアを搭載している。MI300Aには3つのCCDと6つのXCDが使用され、MI300Xには8つのXCDが使用されている。
HBMスタックは、2.5Dパッケージング技術による標準的なインターポーザーを使用して接続される。AMDは2.5Dと3Dのパッケージング技術を組み合わせることで、「3.5D」パッケージングという呼称を生み出した。各I/Oダイには、8つのHBMスタックのうち2つをホストする32チャネルのHBM3メモリ・コントローラが搭載されており、合計128の16ビット・メモリ・チャネルがデバイスに搭載されている。Mi300Xは192GBの容量に12HiのHBM3スタックを使用し、MI300Aは128GBの容量に8Hiスタックを使用する。
AMDはまた、4つのI/Oダイすべてにまたがる合計256MBのInfinityキャッシュ容量を追加し、プリフェッチャを介してデータ・トラフィックをキャッシュすることで、バスの競合とレイテンシを低減しながら、ヒット率と電力効率を高めている。これにより、GPU用に共有L3キャッシュを提供しながら、CPU用に新しいレベルのキャッシュ(概念的には共有L4)が追加されます。AMD Infinity Fabric AP(Advanced Package)インターコネクトと名付けられたInfinity Fabric NoC(ネットワーク・オン・チップ)は、HBM、I/Oサブシステム、およびコンピュートを接続する。

チップには合計128レーンのPCIe 5.0接続があり、4つのI/O Diesにまたがっている。これらは2つのグループに分かれている:1つは4つのx16 PCIe 5.0 + 第4世代Infinityファブリックリンクの組み合わせで、もう1つはInfinityファブリック専用の4つのx16リンクだ。後者は、MI300同士の接続(クロスソケット・トラフィック)にのみ使用される。
MI300Xは純粋にエンドポイントデバイスとして機能し、外部CPUに接続するため、PCIeルートコンプレックスはエンドポイントデバイスとして機能する必要がある。対照的に、MI300AはネイティブCPUコアによりセルフホスト型であるため、PCIeルートコンプレックスはホストとして機能する必要がある。両方のシナリオに対応するため、AMDのカスタムI/Oダイは、同社のIPポートフォリオに新たに追加された同じPCIe 5.0ルート・コンプレックスから両方のモードをサポートする。

AMDのCPU CCDは、I/Oダイに3Dハイブリッド結合されているため、新しいインターフェイスが必要となる。これはEPYCサーバー・プロセッサーに搭載されているのと同じCCDだが、これらのチップは標準的な2.5Dパッケージを活用するGMI3(Global Memory Interconnect 3)インターフェイスを介して通信する。AMDは、GMI3リンクをバイパスする新しいbond pad via interfaceを追加し、チップを垂直に積み重ねるために必要なTSV(スルー・シリコン・ビア)を提供する。このインターフェイスは2リンクワイドモードで動作する。
5nm XCD GPUダイは、AMDのGPU設計の完全なチップレット化を意味する。MI200で使用されたチップレットが2つの独立したデバイスとして提供されていたのとは異なり、MI300チップレットは1つのモノリシックGPUとして提供される。
各XCDは40個の物理的なCDNA3コンピュート・ユニットを持つが、起動するのは38個だけである。各38CPUチップレットには4MBの共有L2(16x256KB)がある。XCDとIODは、ジョブをより小さな部分に分割し、ディスパッチし、同期を保つためのハードウェア支援メカニズムを備えており、ホストシステムのオーバーヘッドを削減する。また、ハードウェア支援によるキャッシュ・コヒーレンスも備えている。


2つのXCDが各I/Oダイに取り付けられ、2つのHBM3スタックに接続される。これにより、GPUは、帯域幅、レイテンシ、および一貫性の問題を軽減するために、接続された2つのスタックと個別に通信することができる。しかし、すべてのXCDはどのメモリスタックとも通信可能だ。
当然ながら、リモート・スタックへのアドレス指定にはレイテンシ・ペナルティが発生する。メモリ・トランザクションは、移動距離が長いほどレイテンシが大きくなる。AMDは、IODとXCDに直接接続されたHBMはゼロホップ・トランザクションである一方、IOD上の別のメモリ・スタックへのアクセスは2ホップ・ジャンプであると指摘している。最後に、隣接するIOD上のメモリ・スタックへのアクセスは3ホップ・ジャンプとなる。2ホップ・ジャンプのペナルティはレイテンシがおよそ30%増加することであり、3ホップ・ジャンプはレイテンシが60%増加する。
3枚目のスライドは、NoCから利用可能な帯域幅を示している。パッケージの垂直セクションを横切るI/O Dies間の帯域幅は1.2TB/s/dirで、水平データパスはI/Oデバイスからの追加トラフィックに対応し、それをメモリトラフィックとは別に処理できるようにするため、わずかに多い1.5TB/s/dirの帯域幅を提供する。パッケージの左右にあるPCIeコンプレックスは、各I/Oダイから64 GB/s/dirのスループットを提供する。パッケージの上部と下部では、各HBMスタックが665GB/秒のスループットを提供していることがわかる。
AMDは、EPYCプロセッサーのNPS設定のように、コンピュート・ユニットをさまざまな論理ドメインに分割する複数のパーティショニング・スキームを持っている。これにより、さまざまなXCDをさまざまなグループに分割して帯域幅を最適化できるため、パフォーマンスを最大化し、「NUMAネス」の影響を抑えることができる。
AMDは、コンピュート・ユニットとI/Oダイの間に十分な帯域幅を確保するには、3Dハイブリッド・ボンディングが唯一の現実的な方法だと判断した。AMDはこの技術について豊富な経験を持っており、すでに何百万もの3D V-Cache搭載PCプロセッサーを出荷している。
現在では成熟したこのハイブリッド・ボンディング・テクノロジーに関する長年の経験が、MI300プロセッサーでこのテクノロジーを採用する自信につながった。AMDのコンシューマー向けPCチップは、3D V-Cacheと標準モデルの両方で構成されているが、MI300プロセッサーは、AMDが製品スタック全体をこの技術に完全に依存する初めてのケースとなる。
Sources




コメントを残す