
ServiceNow、Hugging Face、NVIDIAの3社は、コードを生成するためにローカルで実行できるLLM、「StarCoder2」をリリースした。StarCoder2には、3B、7B、15Bのパラメータを持つ3つの異なるサイズが存在する。フラッグシップモデルであるStarCoder2-15Bは、The Stack v2の4兆以上のトークンと619のプログラミング言語で学習されている。すべてのモデルは、16,384個のトークンのコンテキストウィンドウと4,096個のトークンのスライディングウィンドウアテンションを持つGrouped Query Attentionを使用し、Fill-in-the-Middle目的語を使用して学習されている。

それぞれ、30億パラメータモデル、Hugging Faceによってトレーニングされた70億パラメータモデル、NVIDIAによってNVIDIA NeMoを使用してNVIDIAアクセラレーションインフラストラクチャ上でトレーニングされた150億パラメータモデルの3つのモデルサイズがある。
StarCoder2はBigCodeコミュニティによって構築された。このプラットフォームの背後にあるインスピレーションは、GitHub上の開発者の意思を尊重しつつ、透明性と費用対効果を考慮していることだ。訓練されたソースコードのコレクションは「The Stack v2」と呼ばれ、67.5TBのコードが含まれている。重複を除いたバージョンは32.1TBのコードで、それでもまだ多い。
コーディングのために特別に訓練されたLLMの利点は、パラメータを大幅に小さくできるため、移植性が高くなることだ。StarCoder2の研究論文では、150億パラメータ・モデルは、その2倍のサイズのモデルであるCodeLlama-34Bと一貫して一致するか、それを上回ることさえあると述べられている。StarCoder2の30億パラメータ・モデルでさえ、オリジナルのStarCoderの150億パラメータ・モデルを凌駕している。
小型、中型、大型モデルの違いについては、主にプログラミング言語とトレーニングデータに起因する。最大のモデルには619のプログラミング言語があるが、70億と30億のパラメータモデルでは、これをわずか17に減らしている。その17言語以下の通りだ:
- C, C++
- C#
- Go
- Java
- JavaScript
- Kotlin
- Python
- Lua
- PHP
- Python
- R
- Ruby
- Rust
- SQL
- Shell
- Swift
- TypeScript
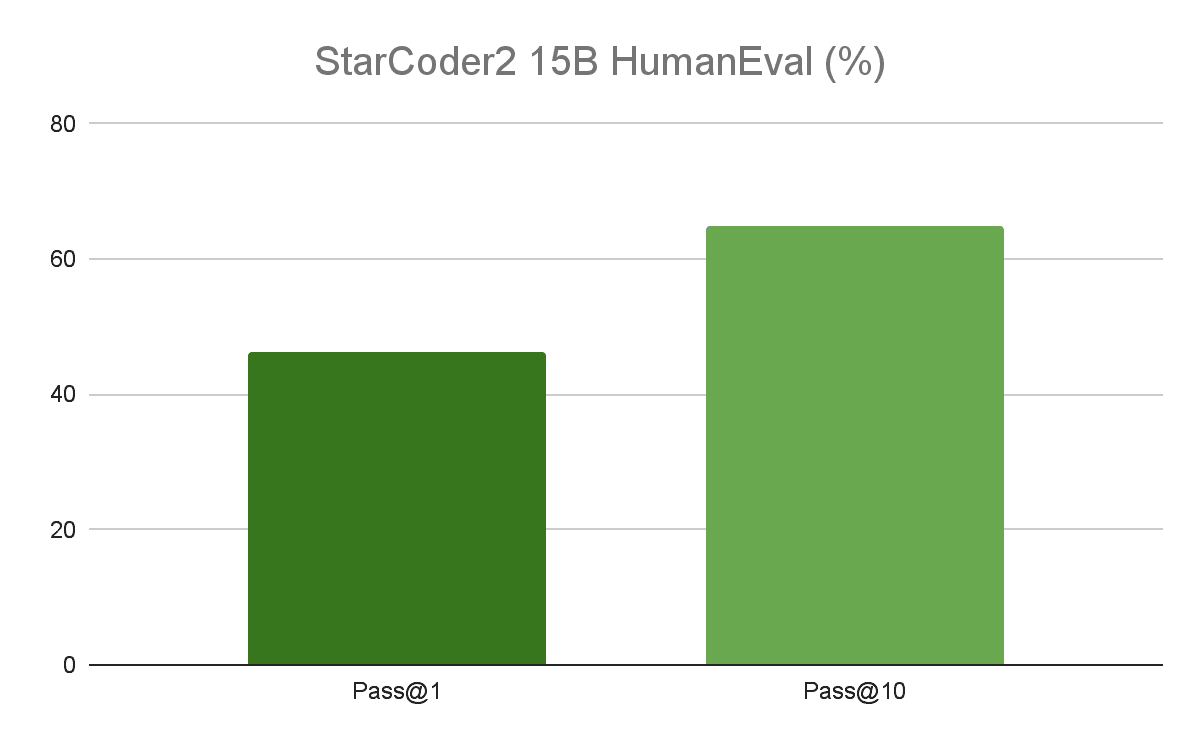
StarCoder2のコンテキストウィンドウは16,000トークンで、小規模から中規模のコードベースに最適となっている。また、150億パラメータモデルは、HumanEvalベンチマークで46.3%のスコアを達成した。競争力を維持するため、StarCoder2の150億パラメータはDeepSeekCoder-33B(最高のコーディングモデルと広く評価されている)を上回ることはできないが、半分のサイズのモデルとしてはかなり近いものだ。
研究論文の中で、StarCoder2の開発チームは、「モデルの重みを公開するだけでなく、トレーニングデータに関する完全な透明性を確保することで、開発したモデルに対する信頼を高め、他のエンジニアリングチームや科学者が我々の取り組みを基に構築できるようにしたいと考えています」と述べている。
StarCoder2の使い方
StarCoder2はHugging Faceで見ることができ、NVIDIAは自分でモデルをカスタマイズして展開する方法についても説明している。CPU上でもNVIDIAのグラフィックカード上でも実行可能で、RAMの少ないプラットフォームでも実行できるように、より小さなバリエーションが用意されている。これらはすべてPythonを使用してデプロイすることができ、Hugging Faceには各モデルの説明と、自宅のコンピュータで使用する方法が掲載されている。
論文
参考文献
- ServiceNow: ServiceNow, Hugging Face, and NVIDIA Release New Open-Access LLMs to Help Developers Tap Generative AI to Build Enterprise Applications
- Hugging Face: StarCoder2 and The Stack v2
- NVIDIA: Unlock Your LLM Coding Potential with StarCoder2
研究の要旨
BigCodeプロジェクトは、コードのための大規模言語モデル(Code LLMs)の責任ある開発に焦点を当てたオープンサイエンス共同研究であり、StarCoder2を紹介する。Software Heritage (SWH)とのパートナーシップにより、私たちはThe Stack v2をSWHのソースコードアーカイブのデジタルコモンズ上に構築する。619のプログラミング言語にまたがるSWHのリポジトリに加え、GitHubのプルリクエスト、Kaggleのノートブック、コードドキュメントなど、その他の高品質なデータソースも厳選している。この結果、最初のStarCoderデータセットよりも4倍大きい学習セットが得られた。3.3兆から4.3兆のトークンに対して3B、7B、15BのパラメータでStarCoder2モデルを学習し、包括的なCode LLMベンチマークセットで徹底的に評価する。我々の小型モデルであるStarCoder2-3Bは、ほとんどのベンチマークで同規模の他のCode LLMを凌駕し、StarCoderBase-15Bも凌駕することがわかった。我々の大型モデルであるStarCoder2- 15Bは、同規模の他のモデルを大幅に上回っている。さらに、このモデルの2倍以上のサイズのCodeLlama-34Bに匹敵するか、上回っています。DeepSeekCoder-33Bは、高リソース言語のコード補完で最高のパフォーマンスを発揮するモデルだが、StarCoder2-15Bは、数学とコード推論のベンチマーク、およびいくつかの低リソース言語で、これを上回ることがわかる。我々は、OpenRAILライセンスの下でモデルの重みを利用可能にし、ソースコードデータのSoftWare Heritage persistent IDentifier (SWHID)を公開することで、学習データに関する完全な透明性を確保している。




コメントを残す