
Armは、次世代スマートフォン向けの新しいCPU Armv9「Cortex-X3」および「Cortex-A715」を発表した。これまで同社が提供していた、GPU「Mali」とは別のラインとして、並行して展開されていくという。
アーキテクチャの刷新はないが、様々な改良により大幅な性能向上を実現
各コアの変更点の詳細について見ていく前に、全体を俯瞰してみよう。
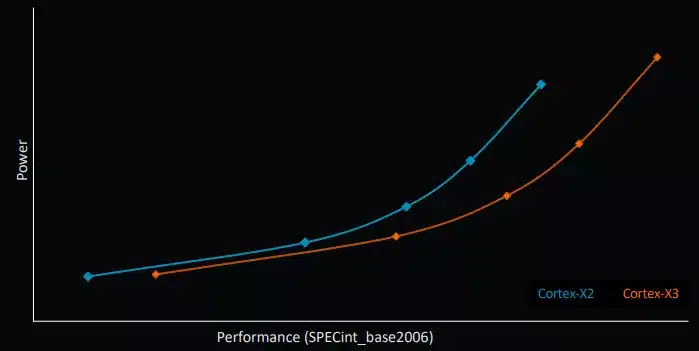
まず、今回発表されたCortex-X3は、Cortex-X2、X1に続く、Armの第3世代のXシリーズ高性能CPUコアだ。主にフラグシップモデルのスマートフォン向けチップ(例:Snapdragon 8 Gen 1や、Dimensity 9000などの後継モデル)となる。そのため、ピークパフォーマンスの向上に狙いを定めた開発が行われている。Cortex-X3は、同じプロセス、クロック速度、キャッシュ設定(ISOプロセスとも呼ばれる)の場合、Cortex-X2に対して11%の性能アップを実現しているとのことだ。ここで、「同じプロセス」と注意書きしたことより、今後の3nm製造プロセスへの移行により期待されるパフォーマンスの向上幅は、実に25%にまで拡大するという。さらに、Armは、このコアの性能はラップトップ市場で大きな存在感を放つことになる。例えば、ミドルクラスのIntel i7-1260Pに対して最大34%の性能面での優位が見られるとのこと。の性能向上が見込まれると予想している。Cortex-X3は、AppleのM1およびM2には及ばないものの、その差を縮めることができるだろう。

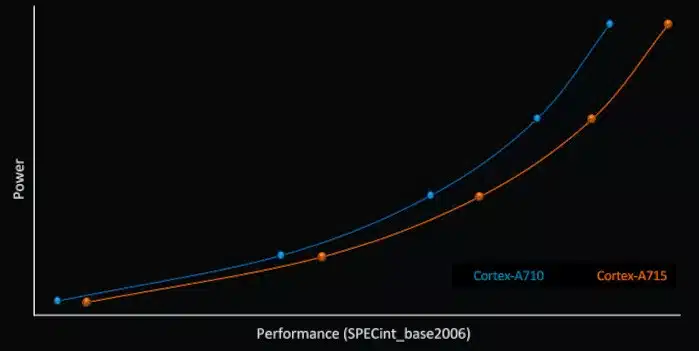
Cortex-A715の改良はやや控えめで効率の最適化に重点を置いている。Armは、キャッシュ設定の比較において、Cortex-A710よりも5%性能が向上していると計算している。より大きな改善点として、20%向上したとされる電力効率が挙げられる。これにより、バッテリー持続時間に顕著な向上をもたらすはずだ。TSMCによれば、5nmから3nmへの移行により、同じ性能でさらに20~30%の効率改善が見込まれることを考慮すれば、さらに良い結果がもたらされるだろう。Armは、さらに効率性を追求し、昨年の小さなCortex-A510を刷新し、こちらも5%電力を削減している
全体として、Armは、求める性能に応じて柔軟に切り替わるコアを用いることで、バックグラウンドタスクを実行するコアの電力効率を高めながら、より高いピーク性能とよりデバイスの利用時間の向上を期待している。今回各コアに行われた変更の詳細は以下の通りとなる。
Cortex-X3は最大25%のパフォーマンス向上

Cortex-X3は、前世代と同様にArmv9アーキテクチャを採用しているが、アーキテクチャの刷新を伴わずに今回大きな性能向上を達成している。これは、コアのフロントエンドに多くの改善を行ったことにより実現した。
フロントエンドの仕様としては、分岐予測精度の向上、間接分岐(ポインタを使った分岐)用の新しい専用構造による低レイテンシ化などが挙げられる。Armの分岐予測アルゴリズムの高い精度の恩恵を受けるため、BTB(Branch Target Buffer)が大幅に拡張された。さらに、L1 BTBキャッシュの容量が50%増加し、L0 BTBの容量が10倍になっている。後者は、BTBが頻繁にヒットするワークロードにおいて、コアが性能向上を実現することを可能にした。また、BTB のサイズが大きくなったため、Arm は 3 つ目の L2 キャッシュを搭載する必要があった。
CPUの分岐予測器は、CPUの実行ユニット数を最大化し、高い性能と効率を実現することを目的として、コードのループやif(分岐)において、次の命令を予測するために構築されている。ループ分岐はプログラム内で繰り返し行われることが多く、特にアウトオブオーダーのCPUコアでは、オンデマンドでメモリから命令を取得するよりも、事前に予測する方が高速に処理できる。
BTB(Branch Target Buffer)は、分岐先アドレスや予測される分岐命令を格納する予測器のキャッシュのようなテーブルである。BTBが大きければ大きいほど、将来の分岐で使用する命令を多く保持することができるが、その分シリコン面積が必要となる。
この変更を理解するには、Armのブランチプレディクタが分離された命令プリフェッチとして動作し、パイプラインストール(バブル)を最小限に抑えるためにコアの残りの部分よりも先に実行されることに注意する必要がある。これは、コードベースが大きいワークロードではボトルネックになることがあり、Armはそのエリアフットプリントの性能を最大化したいと考えている。BTB のサイズを大きくすると、特に L0 では、命令キューを埋めるためにより多くの正しい命令がキューに並び、その結果、テイクブランチバブルを減らし、CPU 性能を最大化することができる。
Cortex-X3は、実行コアの下流で利益をもたらすフロントエンドの最適化に重点を置いている
そのために、Armはフェッチの深さも拡張し、プレディクタがより多くの命令をさらに先読みして、大きなBTBを活用できるようにした。これも、CPUが何もしない命令パイプでのストール回数を減らすという目的に合致している。Armは、全体として、予測された分岐の平均レイテンシを12.2%削減し、フロントエンドのストールを3%削減し、1000分岐あたりのミスプリディクションを6%削減することができたとしている。
また、より小さく、より効率的なmicro-op(デコードされた命令)キャッシュも搭載された。これは、スラッシングを低減するフィルアルゴリズムの改善により、X2よりも50%小さくなり、X1と同じ1.5Kエントリに戻っている。このmicro-opキャッシュの小型化により、Armはパイプラインの合計深度を10サイクルから9サイクルに減らし、分岐予測ミスが発生してパイプラインがフラッシュされるときのペナルティを減らすことが出来たのだ。
つまり、より正確な分岐予測、より大きなキャッシュ、そしてミスプリディクトによるペナルティの低減が、命令が実行エンジンに到達するまでに、より高いパフォーマンスとより良い効率をもたらすということに繋がった。
命令は、フェッチ、デコード、実行、ライトバックと、「パイプライン」を通ってCPUの中を進んでいく。パイプラインに命令がない場合、ストールやバブルが発生し、何も実行されず、CPUのクロックサイクルが無駄になってしまう。
これは、NOP命令など意図的な場合もあるが、分岐予測ミスの後にパイプラインをフラッシュさせた結果であることが多い。不正なプリフェッチ命令はパイプラインから削除し、正しい命令をフェッチして最初から投入しなければならない。パイプラインが長いと、ミスプリディクトによって多くのサイクルが停止してしまうが、短いパイプラインであれば、命令を再充填してより速く実行することができる。
Armはコアのフロントエンド意外にももちろん改良を加えている。
命令キャッシュからのフェッチが5ワイドから6ワイドに強化され、モップキャッシュがしばしばミスするときのプレッシャーが軽減されている。実行エンジンのALUは、従来の4個から6個に増え、基本演算用のシングルサイクルALUが2個追加されている。アウトオブオーダーのウィンドウも大きくなり、一度に実行できる命令数は576から最大640に増えた。全体的にパイプラインが若干広くなり、より良い命令レベルの並列性を実現するのに役立っている。
バックエンドの改良は、1サイクルあたりの整数ロードが24バイトから32バイトになったこと、ロードストア構造のウィンドウサイズが25%大きくなったこと、空間データアクセスとポインタ/間接データアクセスのパターンに対応するためにデータプリフェッチエンジンが2つ追加されたこと、などだ。つまり、バックエンドもより広く、より高速になったというわけだ。
| Arm Cortex-X Evolution | Cortex-X3 | Cortex-X2 | Cortex-X1 |
|---|---|---|---|
| 予想されるクロック周波数 | ~3.3GHz | ~3.0GHz | ~3.0GHz |
| 命令ディスパッチ幅 | 6 | 5 | 5 |
| 命令パイプラインの長さ | 9 | 10 | 11 |
| OoO 実行ウィンドウ | 640 (2x 320) | 576 (2x 288) | 448 (2x 224) |
| 実行ユニット | 6x ALU (4 SX + 2 MX) | 4x ALU (2 SX + 2 MX) | 4x ALU (2 SX + 2 MX) |
| L1 キャッシュ | 64KB | 64KB | 64KB |
| L2 キャッシュ | 512KB / 1MB | 512KB / 1MB | 512KB / 1MB |
上の表を見ると、Cortex-X1からX3にかけて、Armは命令ディスパッチ幅、OoOウィンドウサイズ、実行ユニット数を増やして並列性を高めただけでなく、パイプラインの深さを継続的に短くして予測ミスマッチによる性能ペナルティを減らしてきている。この世代では、フロントエンドの改良に重点を置いており、Arm は、より強力な CPU 設計だけでなく、より効率的な設計も推進し続けていることが分かる。
消費電力が20%削減されたArm Cortex-A715について
ArmのCortex-A715は、前世代のCortex-A710に取って代わり、Xシリーズよりも性能とエネルギー消費のバランスが取れたアプローチをとっている。しかし、Armは、A715が同じクロックとキャッシュを装備した場合、パフォーマンスとしては、旧ハイパフォーマンスコアのCortex-X1コアと同じパフォーマンスを提供すると述べており、これが依然として重量級コアであることに変わりはない。あくまでも、Cortex-X3に比べて控えめな性能になっていると言うだけだ。Cortex-X3と同様に、A715の改良点の大部分もフロントエンドに見られる。
A710と比較して注目すべき変更点は、新コアが64ビットのみの対応になったということだ。AArch32命令がないことで、Armは命令デコーダのサイズを先代比で4倍に縮小し、そのすべてのデコードでNEON、SVE2などの命令を扱えるようになった。全体として、面積、電力、実行の面で効率が良くなっている。
Cortex-A715は、Arm初の64bit専用ミドルコアとなった
Armはデコーダを刷新する一方で、iキャッシュを4レーンから5命令/サイクルに変更し、mopキャッシュからiキャッシュに命令融合を行い、いずれも命令フットプリントの大きいコードに最適化した。mopキャッシュは、これで完全になくなった。Armは、実際のワークロードではそれほど頻繁にヒットしないため、特に5ワイドデコードに移行している間はエネルギー効率は高くなかったと指摘する。mopキャッシュを削除することで、全体の消費電力が下がり、コアの電力効率20%向上に寄与している。
分岐予測も精度が向上し、方向予測能力が2倍になり、分岐履歴のアルゴリズムも改善された。その結果、予測ミスを5%削減し、実行コアの性能と効率の向上に寄与している。また、条件分岐のために1サイクルあたり2分岐をサポートし、3ステージの予測パイプラインでレイテンシを低減するなど、バンド幅も拡大した。
レガシー32ビットのサポートをやめたことで、Armはフロントエンドを刷新し、よりエネルギー効率を高めている。
性能向上が5%と小幅に留まったのは、実行コアがA710から変更されていないためだろう。また残りの変更はバックエンドにあり、データキャッシュの数が 2 倍になったことで、CPU の並列読み取り/書き込みの能力が向上し、キャッシュの競合が少なくなって電力効率が改善された。A715 L2 Translation Lookaside Buffer (TLB)は、より多くのエントリと連続ページ用の特別な最適化により、ページファイルの到達範囲が3倍になり、エントリあたりの変換数が2倍になって性能が向上している。また、Armは既存のデータ・プリフェッチ・エンジンの精度を高め、DRAMトラフィックを低減し、全体の省電力化に貢献した。
全体として、ArmのCortex-A715は、A710をより最適化したバージョンと言える。レガシーAArch32の必需品を捨て、フロントエンドとバックエンドを最適化することで、性能はわずかに向上するが、それ以上に大きな省電力性能を手に入れた。ほとんどのモバイル製品で用いられるCortex-A715 は、これまで以上に効率的で、バッテリ寿命に恩恵をもたらすだろう。ただし、この設計はもう限界が近いようで、Armは次にミドルコアの性能を押し上げるために、より大きな設計の見直しを考えている用だ。
Cortex-A510がリフレッシュ
今回Armは、新しい省電力コアを発表しなかった。代わりにCortex-A510とそれに付随するDSU-110をリフレッシュした。
改良されたA510は、最大5%の消費電力が削減されている。合わせて、周波数の最適化をもたらすタイミングの改善も行われた。このため、来年のスマートフォンでは、低消費電力タスクの効率が大幅に改善されるだろう。また、刷新されたA510は、レガシーモバイルやIoTなどの市場にコアを投入するために、AArch32サポートの構成が可能になっている。つまり、Armのパートナーがこのコアをどう使うかという点で、柔軟性にも恵まれている。
Armの最新のDynamic Shared Unit(DSU)は、1つのクラスタで最大12コアと16MB L3キャッシュをサポートするようになり、DSUをより大きく、より要求の厳しいユースケースにスケールアップできるようになった。Armは、ラップトップ/PC製品で12コアのセットアップが見られるかもしれないと予想しており、おそらく8つのビッグコアと4つのミディアムコアのセットアップになるのではないだろうか。モバイルでも8コア以上のものが出てくるかもしれないが、それはArmのパートナー次第だ。また、DSU-110は、ソフトウェアのオーバーヒートを抑えることで、DSUに接続されたCPUコアとアクセラレータの間の通信を向上させる。これは、モバイルにはあまり適用できないが、サーバー市場では勝算がありそうだ。
ArmのCPUコアとDSUファブリックの柔軟な性質は、SoCベンダーに多くの可能性を提示している。キャッシュサイズ、クロックスピード、コア数は、過去数年よりもさらに大きく変化する可能性がある。これは、Armのポートフォリオが、増え続ける需要に対応するために、ますます幅広いオプションを提供しているためだ。Armの最新CPUコアを搭載した最初のチップセットは、2022年後半に発表され、2023年にはコンシューマ製品に搭載されると見られている。






コメントを残す