
AppleはOpenAI(Microsoft)やGoogle、Metaが起こした大規模言語モデルの流行の波に乗り遅れたかも知れないが、密かに進めている研究の一端からは、彼らがこれに追いつき追い越そうと着実な研究を進めていることが垣間見える。今回同社の研究者らが、画像のキャプション付け、視覚的な質問への回答、自然言語推論用に設計されたマルチモーダルLLM(大規模言語モデル)のセットである「MM1」に関する同社の研究を説明する論文をひっそりと発表した。これは、これまで沈黙を守ってきたAppleが、いくつかの進歩を遂げ、近いうちに主要な役割を果たす可能性があることを示すものだ。
Apple MM1は、そのインテリジェントなアーキテクチャと洗練されたトレーニングにより、視覚タスクにおいてOpenAIの「GPT-4V」やGoogleの「Gemini」に対抗できる有能なマルチモーダルAIモデルである。以下はその概要だ:
- MM1の能力:様々な種類の情報を解釈し、生成するように設計されており、テクノロジーをより直感的でユーザーフレンドリーにする。
- マルチモーダルAIの背景:テキスト、画像、音声、動画のデータを組み合わせ、人間の情報処理を模倣する技術。
- 主な特徴
- ディープラーニングに300億のパラメータを利用。
- 10億以上の画像と30兆以上の単語を含む多様なデータで学習。
- 他のAIモデルとのベンチマークでトップクラスのパフォーマンスを達成。
GPT-4VやGemini同様、MM1はLarge Language Model(LLM)アーキテクチャをベースにしており、画像とテキストのペア、インターリーブされた画像とテキストのドキュメント、テキストのみのデータ(画像とテキストのペア45%、インターリーブされた画像とテキストのドキュメント45%、テキストのみのデータ10%)を混合して学習させた。
この学習方法によって、MM1は、画像記述、質問応答、さらには基本的な数学的問題解決など、ライバルと同様の能力を開発することができたという。
Appleの研究者は、MM1の性能に最も大きな影響を与える要因(アーキテクチャの構成要素やトレーニングデータなど)を特定するため、綿密な調査を行った。
彼らは、画像の解像度の高さ、画像処理コンポーネント(「ビジュアル・エンコーダ」として知られる)の性能、学習データの量が特に重要であることを発見した。興味深いことに、画像と言語の関連性はそれほど重要ではないことが判明した。
ビジュアル・エンコーダは、画像情報をAIシステムが処理できる形式に変換する役割を担っている。このエンコーダーが高度であればあるほど、MM1は画像の内容をよりよく理解し、解釈することができる。
この研究では、学習データの適切な組み合わせの重要性も強調されている。画像とテキストのペア、画像とテキストのインターリーブデータ、テキストのみのデータは、入力プロンプトの限られた例で強力な結果を得るために不可欠であった。しかし、MM1がプロンプトに例がない状態で出力を生成しなければならない場合、学習データ中の画像とテキストのペアがより重要な役割を果たした。
画像-テキストペアまたは画像-キャプションペアとは、各画像が関連するテキストと直接ペアになっているデータである。このテキストは通常、画像の内容の説明や解説である。
例えば、犬の画像に「公園でボールと遊ぶ茶色い犬」というキャプションがあるようなものだ。このようなペアデータは、自動画像ラベリングなどのタスクのモデル学習によく使われる。
一方、インターリーブ画像テキストデータとは、画像とテキストが混在した順序で表示されるデータのことで、各画像は必ずしも特定のテキストと直接関連付けられている必要はない。
例えば、同じトピックに関連する画像とテキストのセクションが混在しているニュース記事などであるが、必ずしも1対1の関係にはない。このようなデータは、視覚情報とテキスト情報が自然な文脈でしばしば一緒に出現する方法を反映する傾向がある。
この論文では、両方のタイプのデータ、つまり画像とテキストのペアと画像とテキストの混合データの両方と、テキストのみのデータの混合が、マルチモーダルAIモデルの学習に有益であること、特に少ない例で良好な結果を得る(Few-Shot Learning)ことが示されている。
300億パラメータまでスケールアップし、MoE(Mixture-of-Experts)モデルを使用することで、MM1は画像キャプションや視覚的な質問に対する回答のための数ショット学習において、ほとんどの公開モデルを凌駕する最先端の結果を達成している。
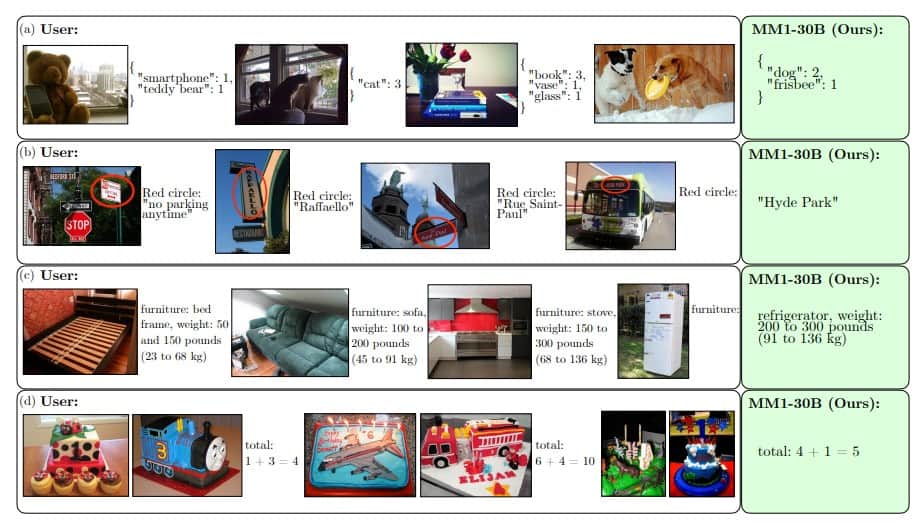
MM1はまた、複数の画像からの情報を組み合わせて複雑な質問に答えたり、1枚の画像からは推測できない結論を導き出したりする、複数画像による推論など、より複雑なシナリオにおいても優れている。これは、MM1が人間の知覚や推論に近い方法で現実世界を理解し、解釈するのに役立つ可能性がある。
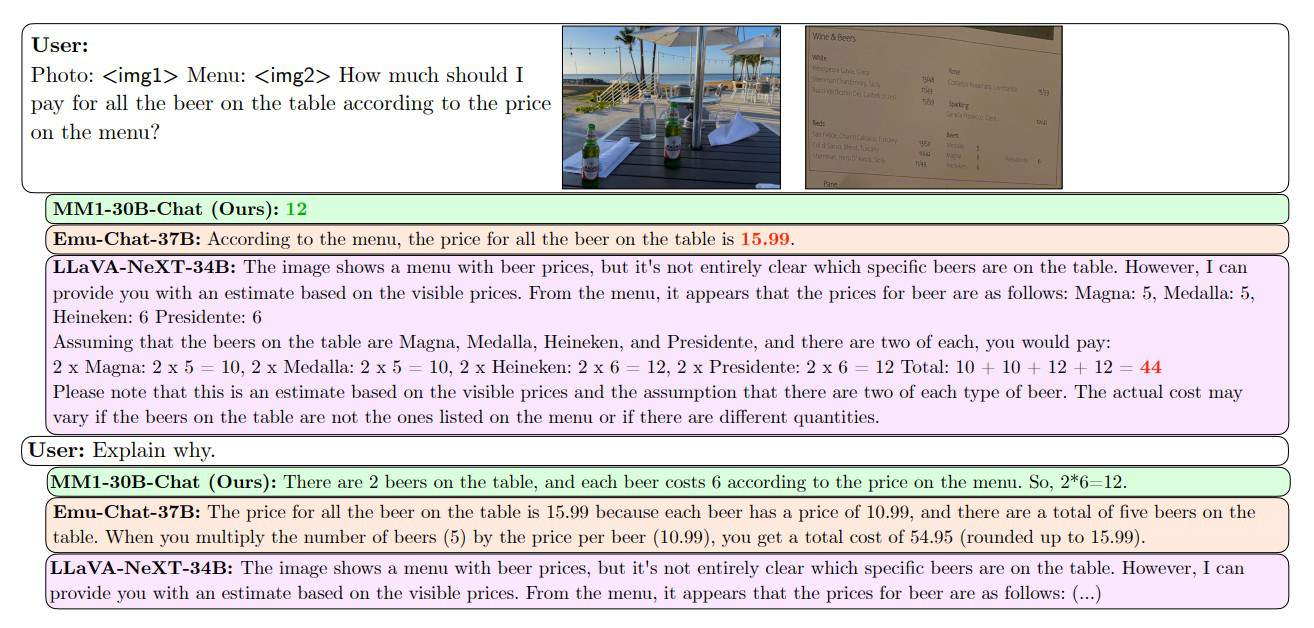
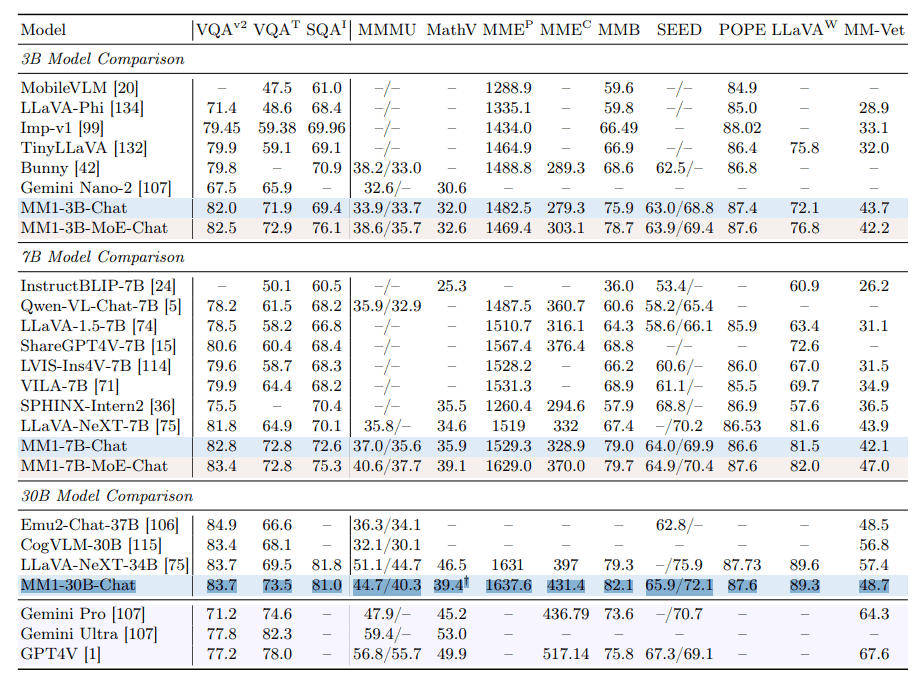
選択されたデータを用いた教師付き微調整(SFT)を通じてモデルをさらに改良した後、MM1は12の確立されたベンチマークで競争力のある結果を達成した。この結果、MM1、またはそのスケールアップ版は、近い将来GPT-4VやGoogle Geminiといった他の主要なAIシステムと本格的な競合となる可能性があるという。
論文
参考文献
- Daily.dev: MM1: The Advanced 30B Parameters Multimodal LLM from Apple
研究の要旨
本研究では、高性能なマルチモーダル大規模言語モデル(MLLM)の構築について議論する。特に、様々なアーキテクチャ構成要素とデータ選択の重要性を研究する。画像エンコーダ、視覚言語コネクタ、および様々な事前学習データの選択に関する慎重かつ包括的なアブレーションを通じて、我々はいくつかの重要な設計上の教訓を明らかにした。例えば、大規模なマルチモーダル事前学習において、画像-キャプション、画像-テキスト、テキストのみのデータを注意深く組み合わせることが、他の事前学習結果と比較して、複数のベンチマークで最先端の(SOTA)数ショットの結果を達成するために重要であることを実証します。さらに、画像エンコーダと画像解像度、画像トークン数が大きな影響を与える一方、視覚言語コネクタの設計は比較的無視できる程度であることを示す。MM1は、密なモデルとMoE(Mixture-of-Experts)の変種から構成され、事前学習指標においてSOTAであり、様々な確立されたマルチモーダルベンチマークにおいて、教師ありの微調整後に競争力のある性能を達成する。大規模な事前学習のおかげで、MM1は、強化された文脈内学習や、数ショットの思考連鎖プロンプトを可能にする複数画像推論などの魅力的な特性を享受している。







コメントを残す