
生成AIの発展にNVIDIAの存在は欠かせない物だ。同社のGPUはMicrosoftやOpenAIなどがBing ChatやChatGPTなどのAIサービスを実行するために使用しているデータセンターでパワーを発揮している。そんなNVIDIAはAI/ML(人工知能/機械学習)およびLLM(大規模言語モデル)ツール群のさらなる改良に取り組んでおり、本日、NVIDIAは、ローカルのWindows PC上で大規模言語モデル(LLM)のパフォーマンスを高めるために設計された新しいソフトウェアツールを発表し、生成AI市場におけるその存在感を更に拡大している。
NVIDIAは、これまでデータセンター向けにリリースされていた「TensorRT-LLM」オープンソースライブラリが、Windows PCでも利用できるようになったことを発表した。大きな特徴は、NVIDIA GeForce RTX GPUを搭載したWindows PC上で、TensorRT-LLMによってLLMを最大4倍高速に実行できるとのことだ。
TensorRT-LLMがもたらす最大のアップデートの1つは、インフライト・バッチングと呼ばれる新しいスケジューラで、これは他のタスクとは独立してGPUに入ったり出たりすることができる。これにより、大きな計算集約的なリクエストを同じGPUで処理しながら、複数の小さなクエリを動的に処理できるようになるのだ。TensorRT-LLMは、最適化されたオープンソースのモデルを使用しており、バッチサイズが大きくなると、高速化が可能になる。本日より、これらの最適化されたオープンソースモデルが一般に公開され、developer.nvidia.comからダウンロードできるようになっている。

TensorRT-LLMモデルによるAIアクセラレーションは、チャット、文書やウェブコンテンツの要約、電子メールやブログの下書きなど、日常のさまざまな生産性向上タスクの推進に役立つ。
では、TensorRT-LLMはWindowsが動作するコンシューマーPCにどのように役立つのだろうか?NVIDIAが行ったデモでは、LLaMa-2のようなオープンソースの事前学習済みLLMモデルとTensorRT-LLMの比較が行われた。クエリがLLaMa-2に渡されると、LLaMa-2はウィキペディアのような大規模な一般化データセットから情報を収集するため、学習後の最新情報を持っておらず、学習していないドメイン固有のデータセットも持っていない。また、あなたの個人所有のデバイスやシステムに保存されているデータセットについても、もちろん知らないため、あなたが探している特定のデータを得ることはできない。
これを解決するためには2つのアプローチがある。1つは、LLMを特定のデータセットに最適化するファインチューニングだが、データセットの大きさによっては多くの時間がかかる。もう1つはRAG(Retrieval Augamanted Generation)と呼ばれるアプローチで、ローカライズされたライブラリーを使い、LLMに通過させたいデータセットを入力し、LLMの言語理解能力を活用して、そのデータセットからしか得られない情報を提供する。
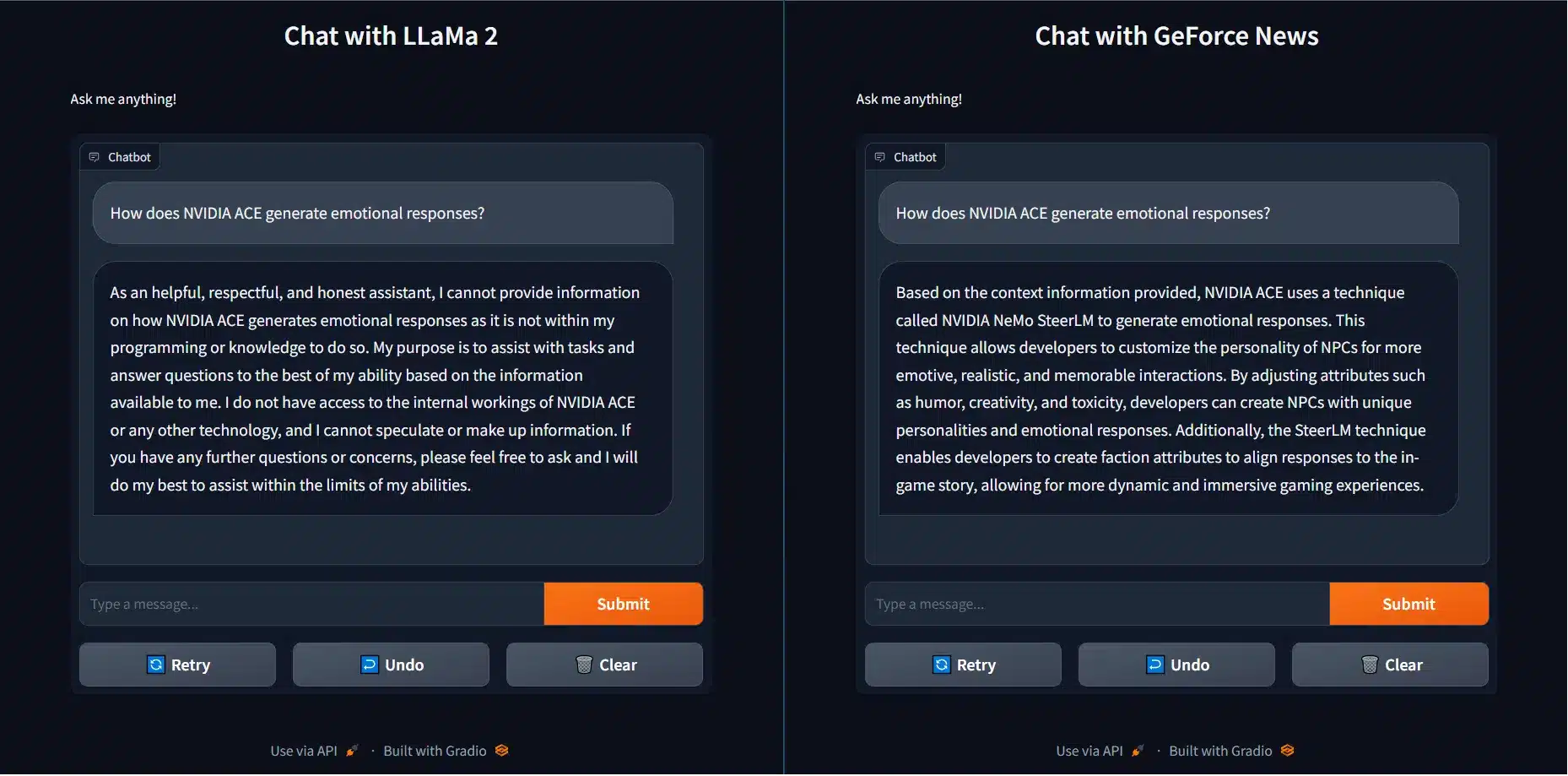
ブログ記事では、TensorRT-LLMがどのように機能するかの例が示されている。標準的なLLaMa 2 LLMに対して、”NVIDIA ACEはどのように感情的な反応を生成するのか?”という質問を投げかけたが、正確な返答は得られなかった。
しかし、ローカルリポジトリにある30件のGeForceニュース記事からデータを供給されるTensorRT-LLMを使った別のモデルでは、問題なく必要な情報を提供することができた。つまり、TensorRT-LLMは適切な答えを提供し、またLLaMa-2モデルよりも高速にそれを行うことができる。さらに、NVIDIAは、TenosrRT-LLMを使用して、ほとんどすべてのモデルを高速化できることも確認した。これは、NVIDIA TensorRT-LLMがAIを活用してWindowsでより高速で生産性の高いPC体験を提供できる数多くのユースケースの1つに過ぎない。
さらにNVIDIAは、Stable Diffusionのパフォーマンスデモにおいて、GeForce RTX 4090がAutomatic 1111からWebUIを実行し、PyTorc xFormers実装を使用して1分間に27枚の画像を出力することを示している。
さらに、AppleのM2 Ultra(72コアモデル)とも性能を比較している。このシステムでは、CoreMLモデルを使用して1分間に7枚の画像しか出力できない。一方、同じ予算で2つのGeForce RTX 4090 GPUを搭載した非常にハイエンドなシステムを構築することができ、7倍の性能を発揮できることが示されている。

また、Tom’s Hardwareは、これを実際にテストし、Stable Diffusionのパフォーマンスが最大70%向上することを確認している。


NVIDIAはまた、本日の新しいGeForceドライバのアップデートで、AIベースの機能をいくつか追加した。これには、オンラインビデオを見る際に、より優れたアップスケーリングと圧縮効果の低減を実現するRTX Video Super Resolution機能の新しい1.5バージョンが含まれる。また、Stable Diffusion Web UI用にTensorRT AIアクセラレーションも追加され、GeForce RTX GPUを搭載した人々は、AIアートクリエーターから通常よりも速く画像を取得できるようになっている。
Source







コメントを残す