
Stable DiffusionやMidjourneyなどのAI画像ジェネレーターに用いられているDiffusionモデルは何度も繰り返し、複数のステップを踏むことでしか高品質の画像を生成できなかった。だが、マサチューセッツ工科大学(MIT)の研究チームは、このプロセスを1ステップに圧縮することに成功したという。
MITのコンピュータ科学・人工知能研究所(CSAIL)の研究者らが開発し、「One-step Diffusion」と名付けられたプロジェクトは、従来のDiffusionモデルを使った画像生成を劇的に高速化できる画期的なものだ。
このOne-step Diffusionは、分布マッチング蒸留(Distribution Matching Distillation:DMD)と呼ばれる新手法に基づいている。これを用いることで、従来必要だった20以上の反復ステップの代わりに、たった1ステップで生成が完了するのだ。
同様の実験は、Stable Diffusionを開発したStability AI社が直接行ったものも含め、すでに実施されている。しかし、MITの手法で生成された画像の品質は、品質の面で、計算量の多い手法に匹敵するとのことだ。
「この進歩により、計算時間が大幅に短縮されただけでなく、生成されたビジュアルコンテンツの品質も維持されています」と、筆頭著者でMITの電気光学とコンピューターサイエンスの博士課程に所属するTianwei Yin氏は述べている。
Diffusionモデルは、鮮明な画像が現れるまで、ノイズの多い初期状態に徐々に構造を加えることで画像を生成する。このプロセスは通常、画像を完成させるために数百回の反復を必要とする。
MITの新しいアプローチは、「教師と生徒」モデルに基づいている:新しいAIモデルは、画像生成のために、より複雑な元のモデルの動作を模倣するように学習する。DMDは、Generative Adversarial Networks(GAN)のスコアリング原理(本物、偽物)とDiffusionモデルのそれを組み合わせたものである。
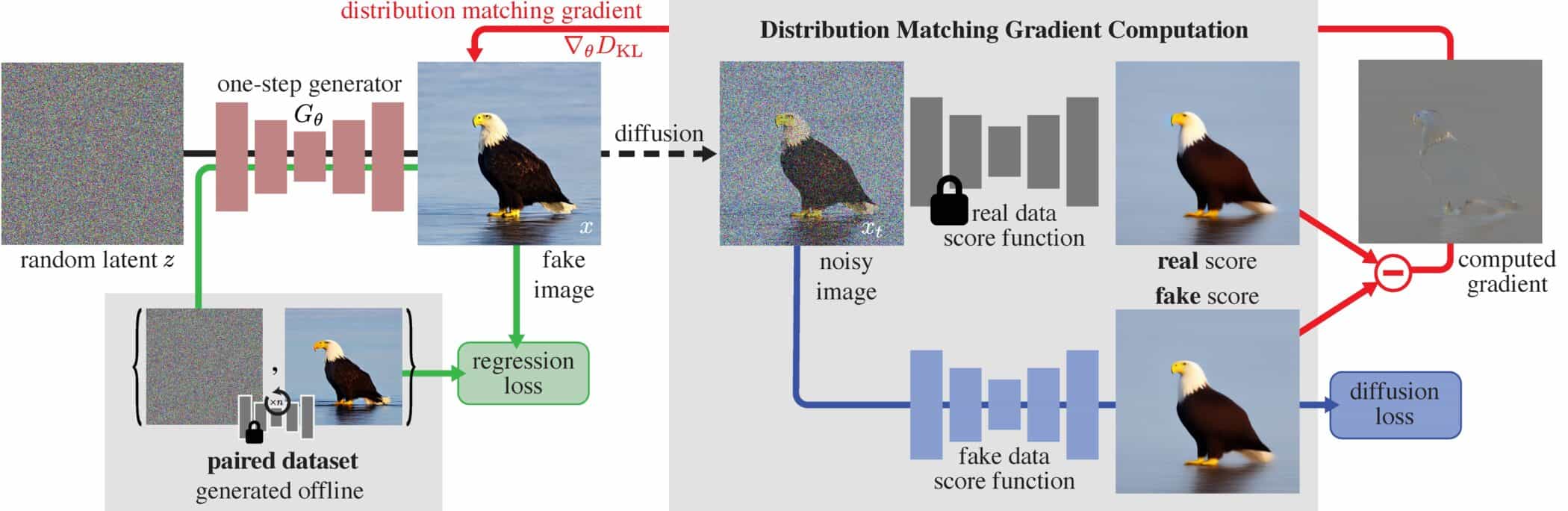
新しい生徒モデルには、研究者たちは事前に訓練されたネットワークを使用し、プロセスを簡素化した。元のモデルのパラメーターをコピーして改良することで、新しいモデルの高速な学習収束を実現した。アーキテクチャーの基礎は維持されている。
「これによって、元のアーキテクチャに基づく他のシステム最適化と組み合わせることで、作成プロセスをさらに加速させることができます」とYin氏は言う。
テストにおいて、DMDは一貫して良好な結果を示した。ImageNetデータセットの特定のクラスから画像を生成する場合、DMDは、より複雑なオリジナルモデルの画像とほぼ同等の画像を生成する最初の1ステップDiffusion技術である。
Fréchet Inception Distance (FID)はわずか0.3であった。これは、生成画像の色、テクスチャ、形状などの特徴の統計的分布に基づいて、生成画像の品質と多様性を実画像と比較して測定する。FIDの値が低いほど、生成画像の品質が高く、実画像との類似性が高いことを示す。


DMDはまた、1ステップ生成により、工業規模のテキスト画像生成における最先端技術を達成している。だが、より要求の厳しいテキスト画像生成アプリケーションには、まだわずかな品質格差と改善の余地がある、と研究者らは述べている。
DMDで生成される画像の性能は、蒸留プロセスで使用される教師モデルの能力にも依存する。Stable Diffusion v1.5を教師モデルとする現在の形態では、生徒は、詳細なテキストを生成できなかったり、「小さな顔」しか生成できなかったりといった制限を受け継いでいる。
論文
参考文献
- MIT:
研究の要旨
Diffusionモデルは高品質の画像を生成するが、何十回ものフォワードパスを必要とする。我々は分布マッチング蒸留(Distribution Matching Distillation: DMD)を導入する。DMDはDiffusionモデルを画質への影響を最小限に抑えながらワンステップ画像ジェネレータに変換する手順である。DMDは、2つのスコア関数(1つはターゲット分布のスコア関数、もう1つはDMDによって生成される合成分布のスコア関数)の差として勾配を表すことができる近似KLダイバージェンスを最小化することによって、1ステップ画像ジェネレータを分布レベルでDiffusionモデルと一致させる。スコア関数は、それぞれの分布に対して別々に訓練された2つのDiffusionモデルとしてパラメータ化されます。多段階拡散出力の大規模構造にマッチする単純な回帰損失と組み合わせることで、我々の手法は、公表されているすべての数段階拡散アプローチを凌駕し、ImageNet 64×64で2.62 FID、ゼロショットCOCO-30kで11.49 FIDを達成し、Stable Diffusionと同等であるが、桁違いに高速である。FP16推論を利用することで、我々のモデルは最新のハードウェアで20 FPSで画像を生成します。





コメントを残す