
バイオメディカル分野の豊富なデータを扱うために、事前に学習させた言語モデルが注目されている。現在の研究の大部分はBERTモデルを使用しているが、Microsoft Researchは、OpenAIの大規模言語モデル「GPT-2」をベースにし、バイオメディカルテキスト生成およびマイニングのための事前学習済み生成トランスフォーマー言語モデルである「BioGPT」を開発した。

自然言語処理(NLP)により、生物医学文献からのテキストマイニングや知識抽出は、新薬の開発、臨床治療、病理学的研究などにおいて非常に重要な役割を担っている。
一般言語領域における事前学習済み言語モデルの2つの主要なブランチ、すなわちBERT、GPTおよびそれらの変種のうち、最初のものは、特にBioBERTおよびPubMedBERTとともに、生物医学領域で広く研究されている。これらは、下流の様々な生物医学的課題において大きな成功を収めているが、生成能力を持たないため、適用範囲が限定されている。
Microsoft Researchのチームは、バイオメディカル分野でまだ本格的に研究されていなかったGPTに頼ることにした。本研究では、GPT-2をベースに、1,500万件のPubMedのタイトルと抄録を対象とした大規模な生物医学テキスト生成とテキストマイニングのために事前学習したBioGPT言語モデルを提案している。
研究者は、現場のボキャブラリーが重要であると指摘している。GPT-2の語彙ではなく、収集したコーパスの語彙を選択し、バイトペアコーディングを用いてコーパスの単語を単語チャンクに分割し、語彙を学習した。
その後、下流のタスクに適合するようにモデルを改良していった。そして、研究者はより良いタスクモデリングのために、ターゲットシークエンスのフォーマットとプロンプトを設計し、分析した。
そして、BioGPTをエンドツーエンド関係抽出、質問応答、文書分類を含む6つのバイオメディカルNLPタスクに適用し、3つのエンドツーエンド関係抽出タスクと1つの質問応答タスクを含むほとんどのタスクで、そのモデルが以前のモデルを上回ることを示したのだ。
BioGPTは、BC5CDR、KD-DTI、DDIエンドツーエンド関係抽出タスクにおいてそれぞれ98.38%、42.40%、76.1%のF44スコアを達成し、PubMed抄録から収集した生物医学質問応答データセットPubMedQAでは78.2%の精度を達成しました。
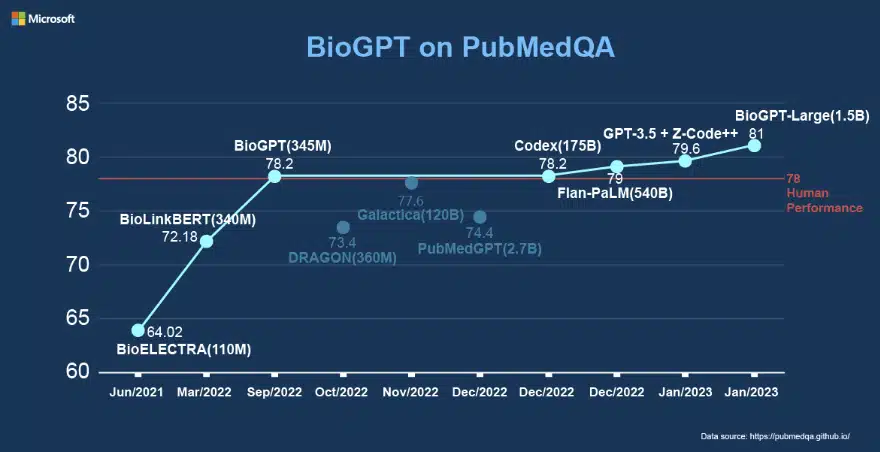
PubMedQAでは、より大きなモデル「BioGPT-Large」が81.0%の精度を獲得してい。テキスト生成に関する彼らのケーススタディは、生物学用語の定義を簡単に作成できるBioGPTの利点をさらに際立たせている。
MicrosoftはOpenAIチームと密接に連携し、従業員と臨床医のコラボレーションを促進し、医療チームの効率を向上させるためにGPT-3を採用する予定だという。
論文
参考文献
- GitHub: microsoft/BioGPT
- via Analytics India Mag: Microsoft Launches BioGPT, the ChatGPT of Lifescience
研究の要旨
自然言語分野での大きな成功に触発され,バイオメディカル分野でも事前学習済み言語モデルが注目されつつある.一般言語領域における事前学習済み言語モデルの2つの主要な枝、すなわち、BERT(およびその亜種)とGPT(およびその亜種)のうち、最初のものはBioBERTやPubMedBERTなど、生物医学領域で広く研究されてきた。これらは様々な下流バイオメディカルタスクにおいて大きな成功を収めているが、生成能力の欠如がその適用範囲を制約している。本論文では、大規模な生物医学文献で事前学習されたドメイン特化型生成Transformer言語モデルであるBioGPTを提案する。BioGPTを6つの生物医学分野の自然言語処理タスクで評価した結果、ほとんどのタスクで従来のモデルを上回る性能を示すことができた。特に、BC5CDR、KD-DTI、DDIエンドツーエンド関係抽出タスクではそれぞれ44.98%、38.42%、40.76%のF1スコアを獲得し、PubMedQAでは新記録となる78.2%の精度を達成しました。また、我々の大型モデルBioGPT-LargeはPubMedQAで81.0%の精度を達成しています。さらに、テキスト生成のケーススタディにより、生物医学用語に対して流暢な記述を生成するBioGPTの生物医学文献に対する優位性を実証しています。コードはこのhttpsのURLから入手可能です。






コメントを残す