
近年の大規模言語モデル(Large Language Models: LLM)の爆発的な成長により、自然言語処理の様々なタスクにおいて、その卓越した性能が実証されているが、同時に課題も伴うものだ。その課題とは、LLMのサイズが大きくなることで、導入のハードルが高くなり、環境フットプリントやエネルギー需要の増大による経済的影響に関する懸念に繋がる点にある。
このような課題に対応するため、一般的な戦略のひとつに、学習後の量子化を活用して推論用の低ビットモデルを開発するというものがある。この手法では、重みと活性化の精度を下げることで、LLMのメモリと計算負荷を大幅に削減することを可能にする。さらに、BitNetに代表される1ビットモデルアーキテクチャの最近の研究は、従来の16ビットモデル(FP16またはBF16)と同等の性能を実現しながら、レイテンシ、メモリ要件、消費電力を大幅に削減するものだ。。
新しく発表された「The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits」と題された論文の中で、Microsoft Researchと中国科学院大学、清華大学の研究チームは、「BitNet b1.58」と呼ばれる1ビットLLMの新しい変種を紹介している。この新たな1ビットモデルは、オリジナルのBitNetを進化させた、値{-1、0、1}を取ることができる3値のパラメータで動作するBitNet b1.58で研究に導入された。ここでのハイライトは、パラメータが-1と1の2つの値に限定されなくなり、0も含まれるようになったことだ。その結果、平均1.58ビットの表現となり、より高いモデル化能力を提供することで、古典的な言語モデルの性能をよりよく反映している。
BitNet b1.58はその前身と比べ、いくつかの改良が加えられている:
- 量子化関数:研究チームはabsmean量子化関数を採用し、実装とシステムレベルの最適化の両方において、より便利で簡単であることを証明している。
- LLaMA類似コンポーネント:BitNet b1.58はLLaMAに似たコンポーネントを統合し、RMSNorm、SwiGLU、ロータリー埋め込みを採用し、すべてのバイアスを排除している。この設計により、一般的なオープンソースソフトウェアに最小限の労力でシームレスに統合できる。

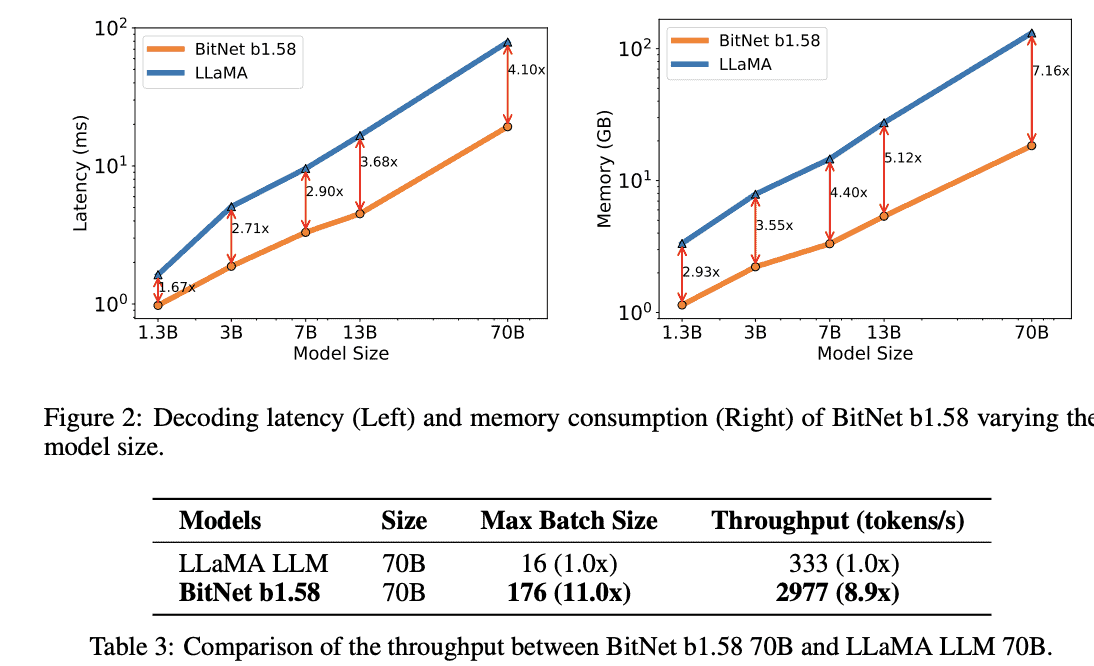
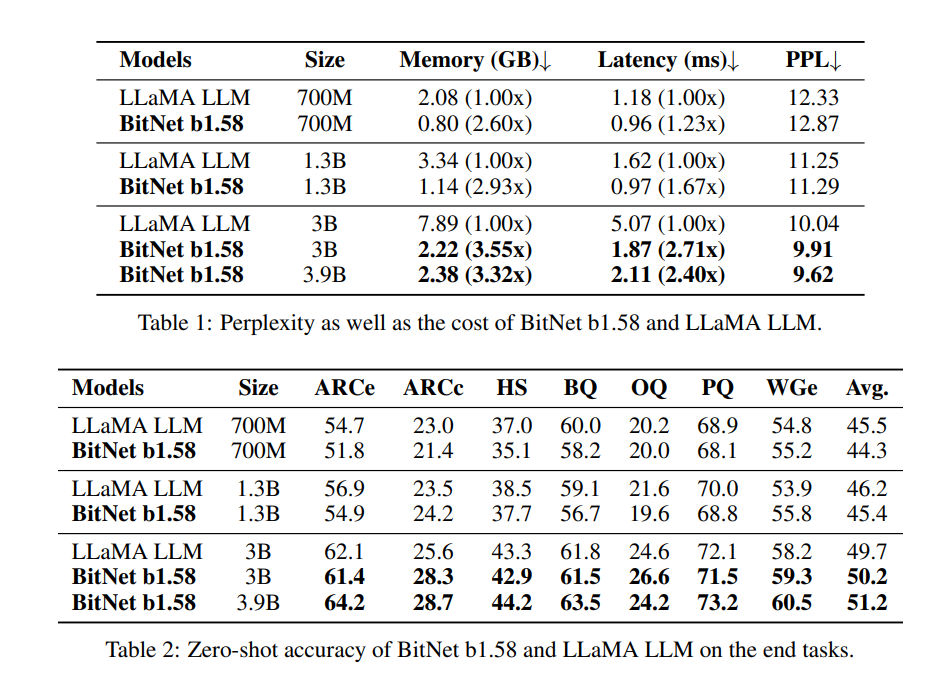
研究者らは、BitNet b1.58とFP16 LLaMA LLMをさまざまなサイズで比較評価した。その結果、BitNet b1.58は、モデルサイズが3Bのときに、完全精度LLaMA LLMのパープレキシティに匹敵する性能を示し始め、同時に2.71倍高速で、GPUメモリの使用量が3.55倍少なかった。
さらに、BitNet b1.58は、行列乗算に必要な乗算演算を最小化する革新的な計算パラダイムを含む、オリジナルの1ビットBitNetの主要な利点を維持し、高い最適化を可能にしている。また、オリジナルの1ビットBitNetと同等のエネルギー消費量を維持しながら、メモリ消費量、スループット、レイテンシの面で効率を大幅に改善しているとのことだ。
さらに、BitNet b1.58には2つの利点がある。第一に、モデルの重みに0を含めることで容易になった特徴フィルタリングの明示的なサポートにより、モデリング能力が強化され、1ビットLLMの性能が大幅に向上している。第二に、実験結果は、BitNet b1.58が、3Bモデルサイズから開始し、同一の構成を使用することで、完全精度(すなわちFP16)ベースラインとプレプレキシティとエンドタスク性能の両方で一致することを実証している。
研究者らはまた、1ビット言語モデルの可能性を十分に引き出すためには、これらのモデルに特化したハードウェアを開発する必要があることも指摘している。研究者らは、この新しいモデルを最大限に活用するために、この方向でのさらなる研究開発を呼びかけている。
論文
参考文献
- Analytics India Magazine: Microsoft Introduces 1-Bit LLM
研究の要旨
BitNetのような最近の研究は、1ビット大規模言語モデル(LLM)の新しい時代への道を開いている。この研究では、1ビットLLMのバリエーションであるBitNet b1.58を紹介する。BitNet b1.58では、LLMのすべてのパラメータ(重み)が3値{-1, 0, 1}である。このLLMは、同じモデルサイズと同じ学習トークンを持つ全精度(FP16またはBF16)Transformer LLMとパープレキシティとエンドタスクパフォーマンスの両面で一致し、レイテンシ、メモリ、スループット、エネルギー消費の点で大幅にコスト効率が高い。さらに深いことに、1.58ビットLLMは、高性能でコスト効率に優れた新世代のLLMを訓練するための新しいスケーリング則とレシピを定義している。さらに、新しい計算パラダイムを可能にし、1ビットLLMに最適化された特定のハードウェアを設計するための扉を開く。






コメントを残す