
ベンチマーク・プラットフォーム「チャットボット・アリーナ」のリーダーボードにおいて、これまで長い間王座を守ってきたOpenAIのGPT-4が、ついにその座を明け渡したようだ。先日Anthropicが発表した「Claude 3」シリーズの高性能モデル「Claude 3 Opus」がGPT-4を抑えて1位に輝くと言う快挙を成し遂げたことが報告されている。
GPT-4に代表される大規模言語モデルとそれを使用するChatGPTなどのチャットボットの客観的な評価は難しい。事実誤認や文法エラー、処理速度を数える以外に、世界的に認められた客観的な評価基準はない。そこで、カリフォルニア大学バークリー校、カリフォルニア大学サンディエゴ校、カーネギーメロン大学の研究者らは、大規模言語モデルの相対的な能力を測定するための組織、LMSYS Organg(または単にLMSYSと呼ばれる)を結成した。
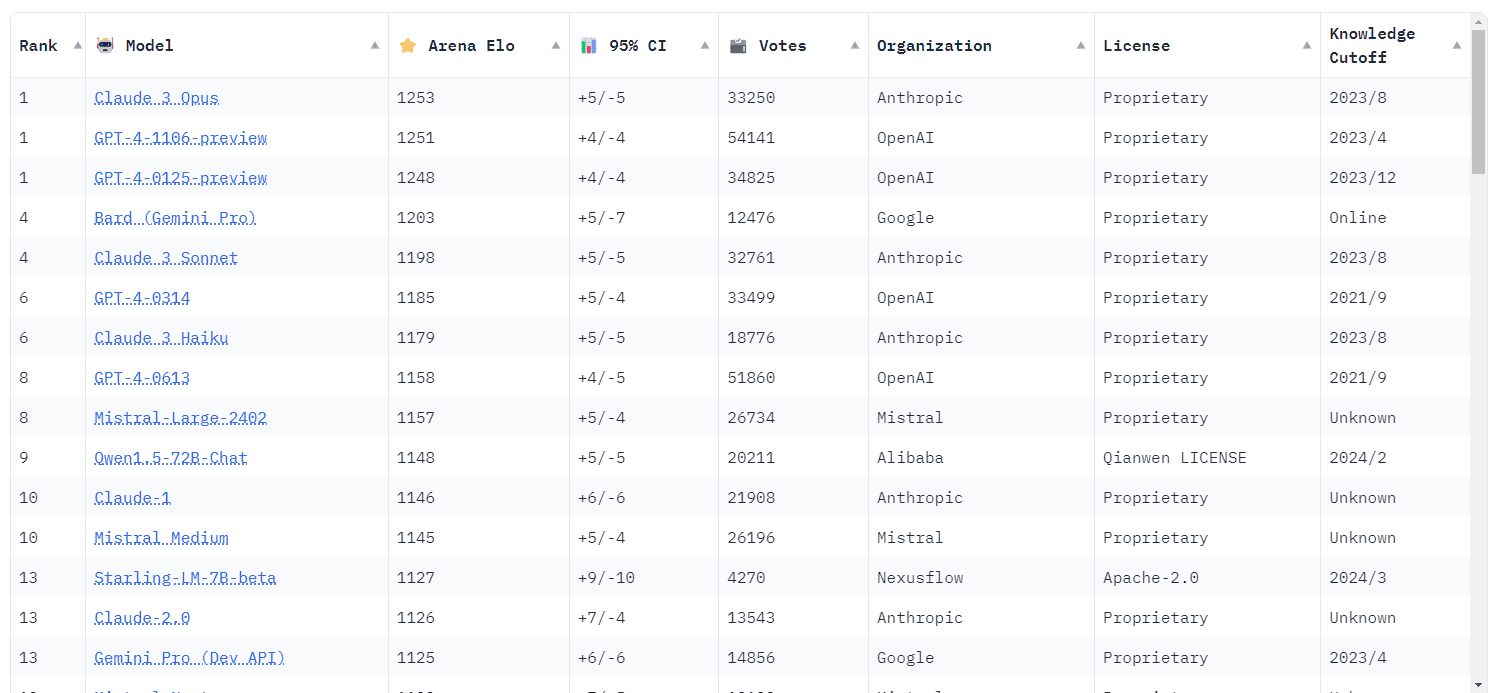
チャットボット・アリーナ(Chatbot Arena)は、大規模言語モデルのパフォーマンスを比較するために、LMSYSによって作成されたベンチマーク・プラットフォームだ。チェスのようなゼロサムゲームでプレイヤーをランク付けするために広く使われているEloレーティングシステムを採用し、アリーナでは、さまざまなモデルが無作為に秘密裏に対戦する。ユーザーはモデルを評価し、最も気に入った答えに投票する。このため、ランキングはユーザーの好みに基づいているため、非常に有用と判断される。
GPT-4は昨年のリリース以来、チャットボット・アリーナで1位の座を守り続けていた。その後に登場したLLMについて評価する際も、「GPT-4」並みと表現されるなど、業界のゴールドスタンダードにさえなっている。しかし先日、AnthropicのClaude 3 Opusが1253対1251という僅差でGPT-4を破ったことで、OpenAIのLLMがついにトップの座を追われた。この勝敗は非常に僅差だったため、誤差の範囲では、GPT-4の別のプレビュービルドと、Claude 3とGPT-4が三つ巴の1位タイとなっている。
さらに印象的なのは、Claude 3 Haikuのトップ10入りだろう。HaikuはAnthropicの「ローカルサイズ」モデルで、GoogleのGemini Nanoに匹敵する。何兆ものパラメータを持つOpusよりも指数関数的に小さく、その性能とコストを考えればGPT-4よりはるかに優れており、コストはGPT-4の約10倍安く比較するとはるかに高速だ。LMSYSによると、Haikuはリーダーボードの7位に入り、GPT-4クラスに昇格した。
Anthropicはおそらく長くトップの座を維持することはないだろう。リークによれば、OpenAIは早ければ今夏にもGPT-4.5もしくはGPT-5となる「よりスマートな」モデルを発表する可能性があるという。新しいLLMモデルはGPT-4より飛躍的に優れており、特定のタスクを実行するために複数の「外部AIエージェント」を採用しており、複雑な問題をより速く確実に解決できるはずとのことだ。
Sources





コメントを残す