
Google DeepMindが、言語モデルを使用して、数学的な問題を解決する新たな手法「FunSearch」を開発し、純粋数学で有名な未解決の難問であった「Cap set問題」を解決したことを、科学誌『Nature』に発表している。
同社によれば、これは「大規模言語モデル(LLM)の創造性と幻覚や誤ったアイデアを防ぐための自動評価機能とを組み合わせたもの」とのことだ。
大規模言語モデル(LLM)を使って長年の科学的な未解決問題が解かれたのは今回が初めてである。
FunSearchの「Fun」は「楽しい」ではなく、「機能」を意味する。このメソッドの核心は、コンピューター言語でコード化された「関数」の探求である。
「我々の知る限り、これはLLMを使用した最初の科学的発見、つまり悪名高い科学的問題についての検証可能な知識の新しい部分を示しています」と研究者たちは論文の中で述べている。
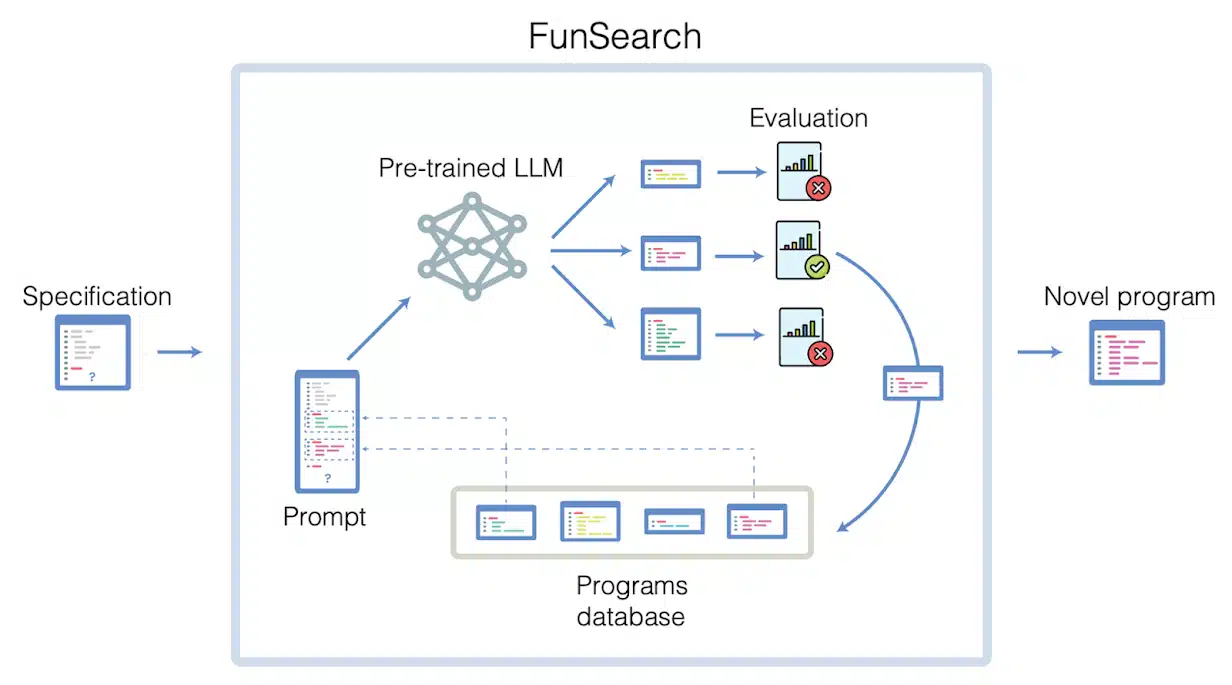
事前に訓練されたLLMと「評価者」の組み合わせ
GPT-4のような大規模言語モデル(LLM)は、定量的推論を含む複雑な問題を解決し、予測的なテキストを生成することにおいて、驚くべき能力を発揮してきた。これらのモデルは、膨大な量の情報を処理し、様々な領域に対する深い理解を示す応答を生成することができる。
無限の猿定理によれば、「タイプライターと無限の時間を持った猿は、最終的にシェイクスピアの戯曲を書き上げることができるという例えで表現される」ように、十分長い時間をかけてランダムに文字列を作り続ければ、どんな文字列もほとんど確実にできあがると考えられている。FunSearchによって、Google DeepMindはタイプライターの前に猿を置いたのではなく、批評家たちが「確率的オウム」と呼んでいる大規模言語モデルを置き、フィードバック ループを介して体系的により良い結果を生み出すのだ。 FunSearch は、関数空間での検索を表す。
論文の著者であるGoogle DeepMindの研究科学者、Alhussein Fawzi氏とBernardino Romera-Paredes氏はブログで、FunSearchは事前に訓練されたLLMと自動化された “評価者”を組み合わせることで作成されたと説明している。
目標は、既存のLLMベースのアプローチの能力を超えることだ。この組み合わせの目的は、幻覚や誤ったアイデアを抑えながら、創造的な解決策をコンピューターコードの形で提供することだと、Google DeepMindは述べている。
LLMと進化的アルゴリズムを組み合わせたFunSearch
FunSearchは、GoogleのPaLM 2のコードに特化した変種であるCodeyを使用し、特定の数学的問題の解を生成できる既存のコードフレームワークの新しいコードスニペットを生成する。システムは、生成された解が既知のものよりも優れているかどうかをチェックする。最適な提案はフィードバックとともにCodeyに返され、このプロセスが繰り返し行われる。FunSearchはこのように、進化的アルゴリズムと言語モデルを組み合わせている。「私たちが LLM を使用する方法は、創造性のエンジンとしてです」と、Romera-Paredes氏は言う。
数日後、数百万もの提案の末、FunSearchは「Cap set問題」に対するこれまで知られていなかった正しい解を含むコードを発見した。数学におけるCap set問題とは、ある範囲内にある整数の集合の最大サイズを求める問題である。
AlphaZeroにインスパイアされた手法に基づくGoogle DeepmindのAlphaTensorとは異なり、言語モデルを使用することで、この手法を他の問題領域に拡張することができる。これをテストするために、研究チームはFunSearchをビンパッキング問題にも適用した。この問題に対する解決策は、現実世界とデジタル空間の両方で意味を持つが、Google DeepMindは後者に焦点を当てた。このシステムは、これまで人間が開発したどの問題よりも早く解決策を発見した。
FunSearchは自動的に適応されるアルゴリズムの出発点
もう一つの利点は、FunSearchによって発見された解決策がコードの形で利用できることである。しかし、この方法には良好なフィードバック信号が必要であり、例えばエビデンスを生成するときには利用できない。しかし研究チームは、FunSearchの性能は言語モデルの能力に応じてスケールアップすると期待している:
「LLMの急速な発展により、わずかなコストではるかに優れた品質のサンプルが得られる可能性が高く、FunSearchは広範な問題に取り組む上でより効果的になります。我々は、自動的に調整されたアルゴリズムがすぐに一般的になり、実世界のアプリケーションに導入されることを想定している」と、研究者らは述べている。
論文
参考文献
- Google DeepMind: FunSearch: Making new discoveries in mathematical sciences using Large Language Models
研究の要旨
大規模言語モデル(LLM)は、定量的推論から自然言語の理解まで、複雑なタスクを解決する上で非常に優れた能力を発揮している。しかし、LLMは時に錯覚(または幻覚)に悩まされることがあり、その結果、もっともらしいが正しくない発言をしてしまうことがある。これは、科学的発見における現在の大規模モデルの使用を妨げている。ここでは、事前に訓練されたLLMと系統的な評価器との組み合わせに基づく進化的手順であるFunSearch(関数空間での探索の略)を紹介する。我々は、既存のLLMベースのアプローチの限界を押し広げ、重要な問題において既知の最良の結果を上回るこのアプローチの有効性を実証する。FunSearchを極限組合せ論の中心的な問題であるキャップ集合問題に適用することで、有限次元と漸近ケースの両方において、既知のものを超える大きなキャップ集合の新しい構成を発見した。これは、LLMを用いた未解決問題に対する最初の発見である。FunSearchをアルゴリズム問題であるオンラインビンパッキングに適用し、広く使われているベースラインを改善する新しい発見をすることで、FunSearchの一般性を示す。ほとんどのコンピュータ検索アプローチとは対照的に、FunSearchは、解が何であるかではなく、どのように問題を解くかを記述したプログラムを検索する。効果的でスケーラブルな戦略であるだけでなく、発見されたプログラムは生の解よりも解釈しやすい傾向があり、ドメインエキスパートとFunSearchの間のフィードバックループを可能にし、実世界のアプリケーションにそのようなプログラムを展開することを可能にする。





コメントを残す