
Googleの研究者は、入力されたテキストの内容を判断し、そこから内容に即した数分の楽曲を生成できるAIを開発した。DALL-Eのようなシステムが、書かれたテキストから画像を生成するのと同様に、口笛や鼻歌のメロディーを他の楽器に変換することさえできると言う。このモデルは「MusicLM」と呼ばれ、一般公開はされていないが、Googleはこのモデルを使って生成したサンプルを多数アップロードしている。
Text-to-Musicモデルは新しいものではないが、論文によると、MusicLMは、28万時間に及ぶ音楽のデータセットで学習し、制作者が言うところの「非常に複雑」な記述(例えば、「印象的なサックスソロとソロシンガーによる魅惑のジャズソング」、「低いベースと強いキックによるベルリン90年代テクノ」)に対して一貫した曲を生成するようになったそうだ。Googleによると「MusicLMは音質とテキスト記述の順守の両方で以前のシステムを凌駕している」とのこと。
MusicLMは、様々なジャンルを生成することができ、さらに「ミュージシャンの経験レベル」(例:初心者、中級者、プロフェッショナル)も再現することができるという。今後、Googleは歌詞の生成、ボーカルの品質向上、より高いサンプルレートなどを検討する可能性がある。
実際に以下のようなテキストとそこから生成された音楽がサンプルとして公開してされているので転載しよう。
- アーケードゲームのメインサウンドトラック。テンポが良く、アップビートで、キャッチーなエレキギターのリフが特徴。繰り返しの多い音楽で覚えやすいが、シンバルのクラッシュやドラムロールなど、意外性のある音も入っている。
- スローテンポで、ベースとドラムがリードするレゲエ曲。エレキギターのサステイン。高音で鳴るボンゴ。ヴォーカルはレイドバックした感じでリラックスしており、非常に表現力が豊か。
また、面白い試みが絵画の説明から音楽を生成するものだ。ゴッホの星月夜や、クリムトの接吻などのWikipediaからの説明を入力し、音楽を出力したサンプルも掲載されている。

『星月夜』(オランダ語:De sterrennacht)は、オランダのポスト印象派画家フィンセント・ファン・ゴッホが描いたキャンバスの油絵である。1889年6月に描かれたこの作品は、サン=レミ=ド=プロヴァンスにある彼の亡命先の部屋の東向きの窓から見た日の出直前の風景に、架空の村を加えて描かれている。 wikipedia

『接吻』この絵は、現代のアール・ヌーヴォー様式とそれ以前のアーツ・アンド・クラフツ運動の有機的なフォルムに影響を受けたスタイルで装飾された精巧で美しいローブをまとい、体を寄せ合うカップルを描いている。wikipedia
AIが生成する音楽自体は以前からあり、それこそポップスの作曲などにも用いられてきた。最近では、AI画像生成エンジンStableDiffusionを使い、テキストプロンプトをスペクトログラムに変換し、それを音楽に変換する「Riffusion」なるものも登場していた。論文では、MusicLMは「品質とキャプションへの忠実さ」の点で、また音声を取り込んでメロディーをコピーできる点で、他のシステムを凌駕することができるとしている。
その他のAI製品と同様に、GoogleはMusicLMに対して、同様の技術を持つ同業他社よりもかなり慎重な姿勢を見せている。「現時点ではモデルを公開する予定はありません」と論文は結んでおり、「クリエイティブなコンテンツの潜在的な不正流用」(盗作と読む)、「文化の流用や虚偽表示」の可能性をリスクとして挙げている。
この技術が、いずれGoogleの製品に登場する可能性もあるが、今のところ、この研究を利用できるのは、音楽AIシステムを構築している他の人たちだけだ。Googleによると、約5,500の音楽とテキストのペアを含むデータセットを一般に公開しており、他の音楽AIを訓練・評価する際に役立つ可能性があるという。
論文
- arXiv.org: MusicLM: Generating Music From Text
参考文献
- Google Research: MusicLM: Generating Music From Text
- via TechCrunch: Google created an AI that can generate music from text descriptions, but won’t release it
研究の要旨
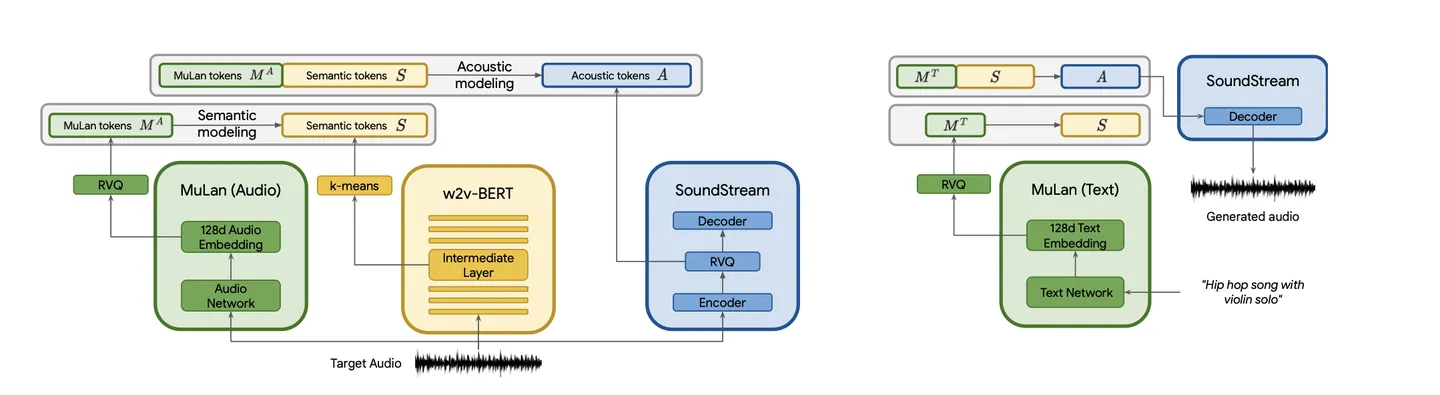
「歪んだギターリフに支えられた落ち着いたバイオリンの旋律」といったテキスト記述から、高忠実度の音楽を生成するモデル、MusicLMを紹介する。MusicLMは、条件付き音楽生成プロセスを階層的な配列間モデリングタスクとして捉え、24kHzで数分間に渡って一貫性のある音楽を生成する。実験により、MusicLMは音質とテキスト記述の遵守の両方において、従来のシステムを凌駕することが示された。さらに、MusicLMはテキストとメロディの両方を条件とすることができ、テキストのキャプションに記述されたスタイルに従って口笛や鼻歌のメロディを変換することができることを実証している。今後の研究を支援するため、我々は5.5kの音楽とテキストのペアからなるデータセット、MusicCapsを一般に公開する。





コメントを残す