
AIが音楽を生成するというサービス自体は、Soundrawに代表されるように、既に一般的なものであるが、今回TechCrunchで紹介されていた「Riffusion」という音楽生成AIは、その奇抜なアプローチから、AIの利用に関する人々の想像力の素晴らしさを感じずにはいられない非常に興味深いものだ。
- Riffusion: Riffusion – About
- TechCrunch: Try ‘Riffusion,’ an AI model that composes music by visualizing it
今年リリースされた深層機械学習モデル「Stable Diffusion」は、テキストから高品質な画像を生成することで大きな話題を呼んだ。
このモデルが優れている点は、オープンソースであることから、この優れたAIを自身のアプリに実装させたりすることが出来ることだろう。既に、Lensa AIなどに実装され、開発者自身が、新たなAIの楽しみ方を提案することや、そもそも画像を生成するのではなく、画像の圧縮率を上げることに利用されるなど、有用性を示すことにも繋がっている。
そしてまた1つ、Seth ForsgrenとHayk Martirosという2人の研究者が、Stable Diffusionの大きな可能性を示した。彼らは、スペクトログラム(音の強さを時間と周波数の関数として表したグラフィック表現)の生成にStable Diffusionを用いたのだ。


そして、楽器を組み合わせて音楽の抜粋を生成し、興味深い結果を生み出すツール、Riffusionを作り出したのだ。
スペクトログラムは、サウンドクリップの周波数コンテンツを視覚的に表現する方法だ。X軸は時間、Y軸は周波数を表す。各ピクセルの色は、その行と列で与えられた周波数と時間におけるオーディオの振幅を表す。
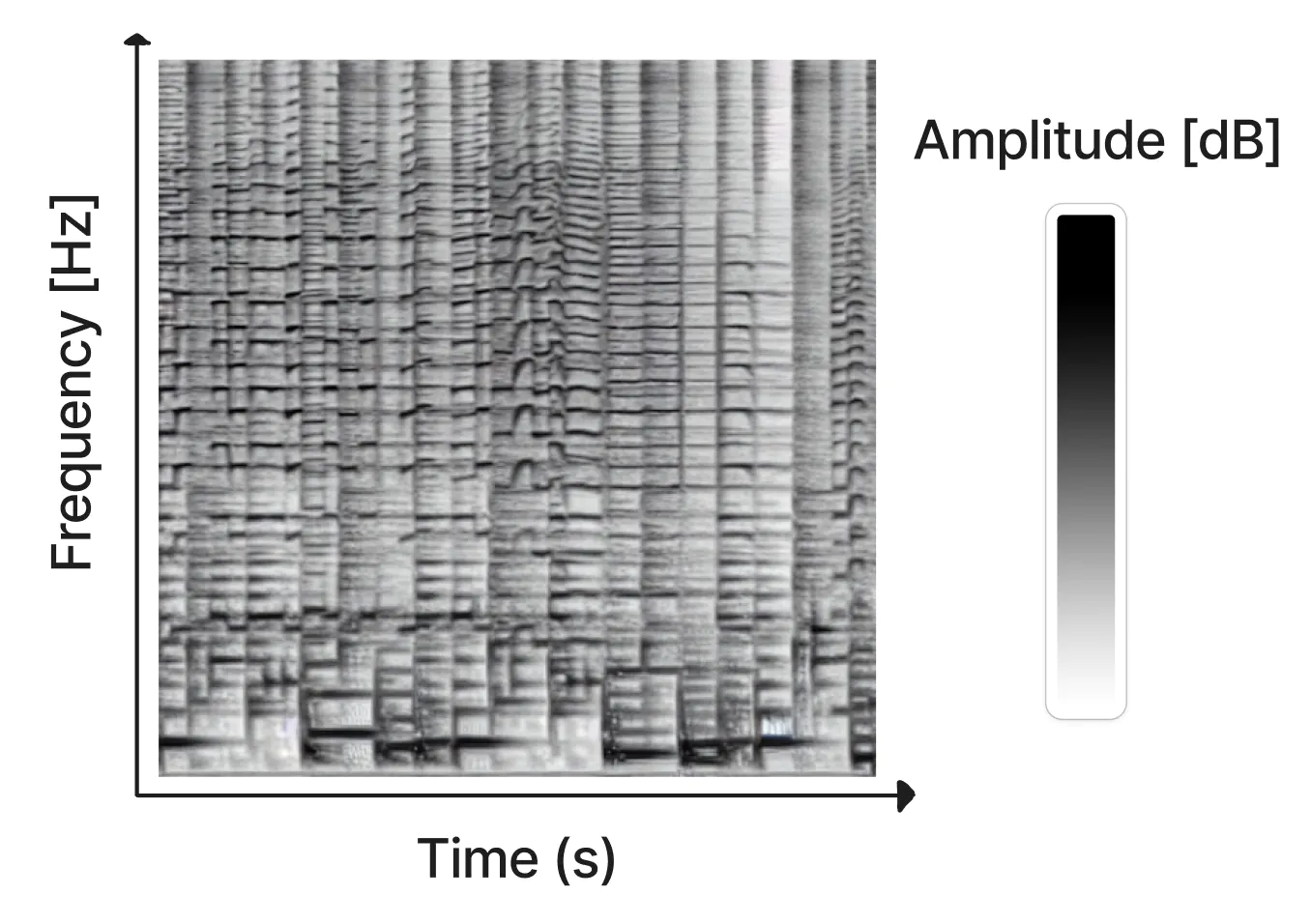
スペクトグラムは、短時間フーリエ変換(STFT)を用いて音声から計算することができる。STFTは、音声を振幅と位相の異なる正弦波の組み合わせとして近似するものだ。
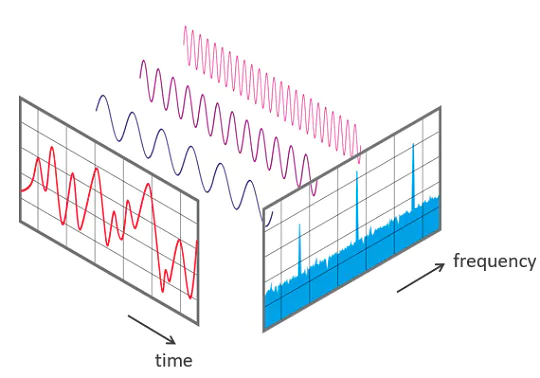
STFTは反転可能であるため、ForsgrenとMartirosはStable Diffusionで作られたスペクトログラムを使って音声を作成したようだ。この過程で、スペクトログラムにはそもそも正弦波の振幅しか含まれていなかったため、Griffin-Limアルゴリズムを用いて位相を近似し、オーディオクリップの再構成を行っている。
また、オーディオ処理の効率化のためにはGPUを用いているが、そのためにTorchaudioライブラリを使用している。
2人の研究者による成果は、RiffusionプロジェクトのWebサイトで聴くことができる。Text-to-ImageモデルであるStable Diffusionを用いているため、生成したい音楽の種類を文書で記述すれば、自分で音楽を生成することも可能だ。Riffusionの詳細な技術情報は、専用ページで解説されている。
GitHubリポジトリへのリンクは、同ページの下部に公開されている。興味がある場合は、コードをダウンロードして、自分のシステムでRiffusionを使用することも可能だ。





コメントを残す