Googleは、スマートフォン上で動作し、テキスト入力から1秒以内に高品質の画像を生成する新たな画像生成モデル「MobileDiffusion」を発表した。
モデルサイズはわずか5億2,000万パラメータで、Stable DiffusionやSDXLのような数十億パラメータを持つモデルよりも大幅に小さく、モバイル機器での使用に適しているのが特徴だ。
研究者たちのテストによると、MobileDiffusionはAndroidスマートフォンとiPhoneの両方で、解像度512×512ピクセルの画像を約0.5秒で生成できるという。Googleのデモビデオが示すように、出力は入力と同時に連続的に更新されているのが見て取れるだろう。
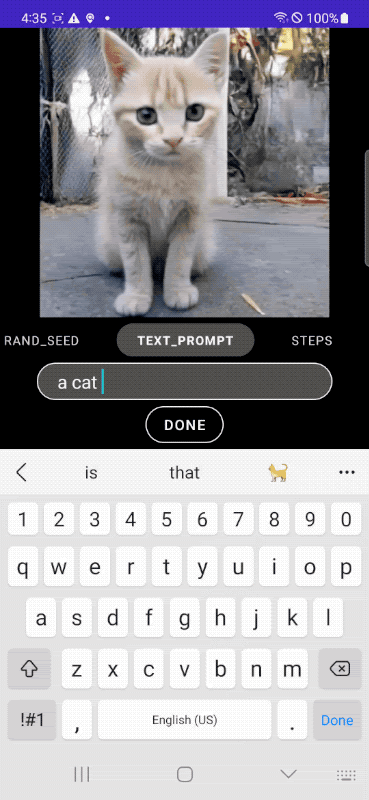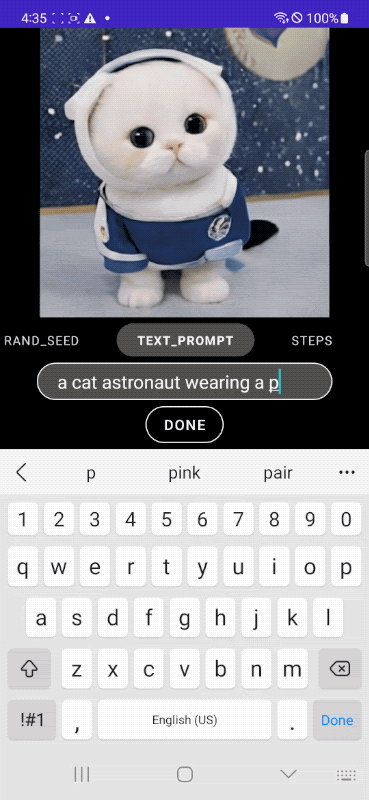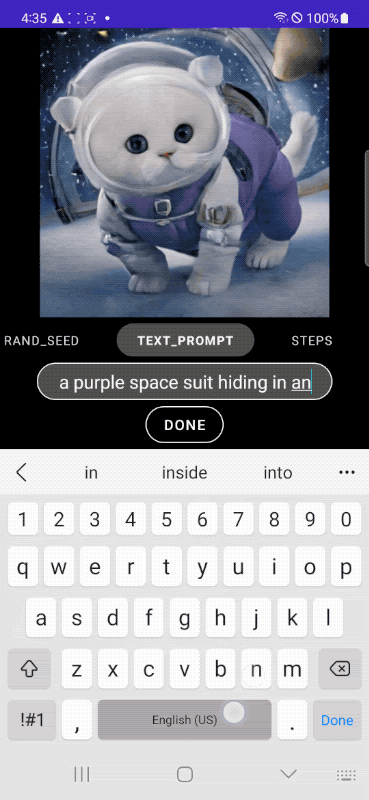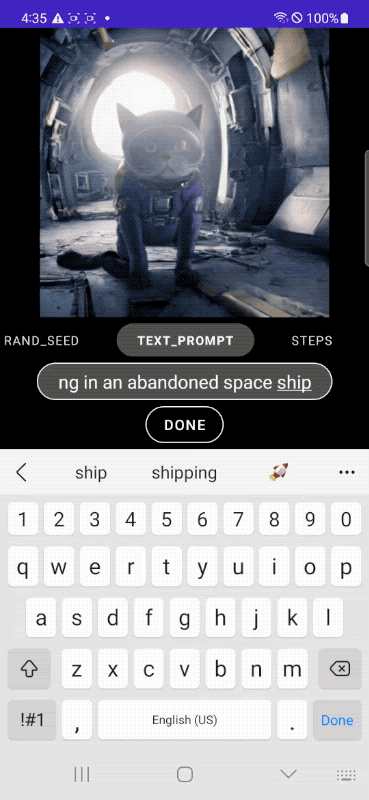
MobileDiffusionは、テキストエンコーダ、拡散ネットワーク、画像デコーダの3つの主要コンポーネントで構成されている。
UNetには自己注意層、相互注意層、フィードフォワード層があり、これらは拡散モデルにおけるテキスト理解に重要である。
しかし、このレイヤーアーキテクチャは計算が複雑で、リソースを大量に消費する。GoogleはいわゆるUViTアーキテクチャを採用し、UNetの低次元領域に多くの変換ブロックを配置することで、必要なリソースを削減している。
さらに、蒸留と生成逆数ネットワーク(Generative Adversarial Network:GAN)のハイブリッドが1~8レベルのサンプリングに使用されている。

Googleはまだこのモデルを一般に公開はしておらず、その計画も発表していない。むしろ、この研究は、モバイル機器でのテキストから画像への生成の民主化という目標に向けた一歩と考えるべきだろう。
GoogleにはPixelシリーズという独自のスマートフォン・シリーズがあり、ハードウェアとソフトウェアの両方において、生成AIはますます重要なトピックになりつつある。
画像生成はますます高速化
昨年、Qualcommは、スマートフォンがStable Diffusionに基づく素早い画像生成が出来る事を実証した。
QualcommのAIスタックを最適化することで、同社は当時ハイエンドのAndroidスマートフォンで画像ジェネレーターを動作させることができた。これは2023年2月当時としては驚くべき技術的進歩だったが、512×512ピクセルの画像を20の推論ステップで生成するには、それでも約15秒かかった。

今回のGoogleのMobileDiffusionにおける進化は圧倒的だ。このアプローチの利点は、OSに関係なく、すべてのシステムで高速な結果が得られることだ。GoogleのAndroidを搭載したSamsungの最新フラッグシップモデル、Galaxy S24よりも、iPhone 15 Proの方がさらに優れているのがその証拠だ。

最近では、SDXL TurboやPixArt-δも、より強力なシステム上ではあるが、準リアルタイムの画像生成において大きな進歩を遂げている。
論文
参考文献
研究の要旨
大規模なテキスト画像拡散モデルをモバイル機器に導入する場合、モデルサイズが大きく、推論速度が遅いという問題があります。本論文では、アーキテクチャとサンプリング手法の両面における徹底的な最適化によって得られた、高効率なテキスト画像拡散モデルである\textbf{MobileDiffusion} を提案します。画像生成の品質を維持しながら、計算効率を高め、画像生成の品質を保ちながらモデルのパラメータ数を最小化するために、モデルのアーキテクチャ設計を包括的に検討します。さらに、MobileDiffusion上で蒸留と拡散-GANの微調整技術を採用し、それぞれ8ステップと1ステップの推論を実現する。定量的にも定性的にも行われた実証研究により、我々の提案技術の有効性が実証された。MobileDiffusionは、モバイルデバイス上で512×512の画像を生成するために顕著な推論速度を達成し、新しい技術の状態を確立しました。






コメントを残す