
生成AIは、それを用いるメリットと共に、著作権や倫理の面、誤情報の拡散などの多くの問題が取り沙汰されているが、そうした人々が更なる懸念を抱きそうな話題として、今回、韓国の研究者らは“ダークウェブのデータだけで訓練された大規模言語モデル”である、「DarkBERT」を開発した事を発表した。
犯罪に対抗するための大規模言語モデル
「ダークウェブ上の、ハッカーやサイバー犯罪者、その他の詐欺師からのデータを使って訓練された」と聞くと、AIを悪用するために開発された、それこそ“人類を滅ぼすAI”のように思われるかもしれないが、その目的は、ダークウェブをデータセットとして使用することで、そこで使用される言語についてAIがより良いコンテキストを得られるかどうかを理解し、研究のためにダークウェブを探索しようとする人々やサイバー犯罪と戦う法執行者にとってより価値のあるものにすることにある。
ダークウェブは、Googleや他の検索エンジンによるクロールを意図的に回避しているインターネットの領域で、大多数の人はそこに行くことがない。Tor(またはそれに類するもの)と呼ばれる特殊なソフトウェアを使用しなければアクセスできないため、そこで何が行われているかはあまり知られていない。半ば都市伝説のように、「拷問や殺人の依頼が行われている」など、さまざまな恐ろしい犯罪が存在するように語られているが、実際には、そのほとんどが詐欺や、私たちが当たり前のように使っているブラウザセキュリティを使わずにデータを盗み出す方法だ。それでも、ダークウェブはサイバー犯罪ネットワークが匿名での会話に使用しているとされ、法執行機関にとって極めて重要なターゲットとなっている。
DarkBERTは新しいAIモデルだが、Tom’s Hardwareによると、Facebookの研究者が2019年に開発したAIアプローチであるRoBERTaアーキテクチャをベースにしているようだ。
しかし、RoBERTaはリリース当初は訓練不足であったため、研究者らは、DarkBERTがダークウェブで使用される言語にうまく適応できるように、Torネットワークをクロールして収集した大規模なダークウェブコーパスでモデルを事前訓練した。さらに、ダークウェブのテキストに潜在する機密情報に関する倫理的な懸念に対処するためのデータ前処理と並行して、データフィルタリングと重複排除によって事前学習用コーパスを磨き上げた。
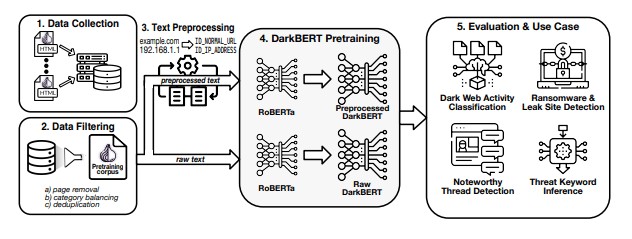
このDarkBERTについて、研究チームは、ダークウェブでサイバーセキュリティの脅威をスキャンしたり、フォーラムを監視して不正な活動を特定するための強力なツールになることを期待している。
ちなみに、研究者たちはDarkBERTを一般に公開する予定はないそうだ。しかし、学術目的でのリクエストは受け付けているとのこと。
今後数ヶ月の間に、研究者は、より最新のアーキテクチャを使用してダークウェブドメイン固有の事前学習済み言語モデルのパフォーマンスを向上させ、多言語言語モデルの構築を可能にするために追加のデータをクロールする予定だと述べている。
論文
参考文献
- Tom’s Hardware: Dark Web ChatGPT Unleashed: Meet DarkBERT
研究の要旨
最近の研究では、ダークウェブで使用される言語には、サーフェスウェブのそれと比較して明確な違いがあることが示唆されている。ダークウェブに関する研究では、一般的にドメインのテキスト分析が必要となるため、ダークウェブに特化した言語モデルは、研究者に貴重な洞察を与える可能性がある。この研究では、ダークウェブデータで事前学習された言語モデルであるDarkBERTを紹介する。DarkBERTを訓練するために使用されるテキストデータをフィルタリングし、コンパイルするために取られた手順について説明する。これは、ダークウェブの極端な語彙と構造の多様性に対抗するためで、ドメインの適切な表現を構築する上で不利になる場合がある。我々は、DarkBERTとそのバニラモデルを、他の広く使用されている言語モデルとともに評価し、ダークウェブのドメインに特化したモデルがさまざまな使用ケースで提供する利点を検証している。我々の評価は、DarkBERTが現在の言語モデルを凌駕することを示し、ダークウェブに関する将来の研究のための貴重なリソースとして機能する可能性があることを示している。






コメントを残す