
スマートフォンやPCからデータセンター・サーバーに至るまで、最新のコンピューターのほとんどには、AIや機械学習用のグラフィック・プロセッシング・ユニット(GPU)やハードウェア・アクセラレータが搭載されている。よく知られた商用例としては、NVIDIA GPUのTensorコア、Google CloudサーバーのTensor Processing Unit(TPU)、Apple iPhoneのニューラルエンジン、Google PixelスマートフォンのTensorチップのTPUなどがある。
これらのコンポーネントはそれぞれ別々に情報を処理し、1つの処理ユニットから次の処理ユニットへと情報をシャッフルするため、データの流れにボトルネックが生じることが多い。カリフォルニア大学リバーサイド校(UCR)の研究者らは新しい研究で、既存の多様なコンポーネントを同時に動作させることで、処理速度を大幅に向上させ、エネルギー消費量を削減する方法を実証した。
同時異種マルチスレッディング(simultaneous and heterogeneous multithreading: SHMT)と呼ばれる研究者たちのフレームワークは、コードのある領域を1種類のプロセッサに独占的に委譲することしかできず、他のリソースはアイドリング状態で現在の機能には貢献しないという従来のプログラミングモデルから脱却したものだ。
その代わりに、SHMTは複数のコンポーネントの多様性(異種性)を利用し、計算機能を分割してコンポーネント間で共有する。つまり、並列処理の一種である。
SHMTの仕組み
SHMTでは、一連の仮想オペレーション(VOP)により、CPUプログラムは仮想ハードウェアデバイスに機能を「オフロード」することができる。プログラム実行中、ランタイムシステムがSHMTの仮想ハードウェアを駆動し、ハードウェアリソースのスケジューリング決定能力を測定する。
SHMTでは、QAWS(Quality-aware work-stealing)というスケジューリングポリシーを採用しており、リソースを占有することなく、品質管理とワークロードバランスの維持に役立っている。ランタイムシステムは、複数のハードウェアリソースを同時に使用するために、VOPを1つ以上の高レベルオペレーション(HLOP)に分割する。
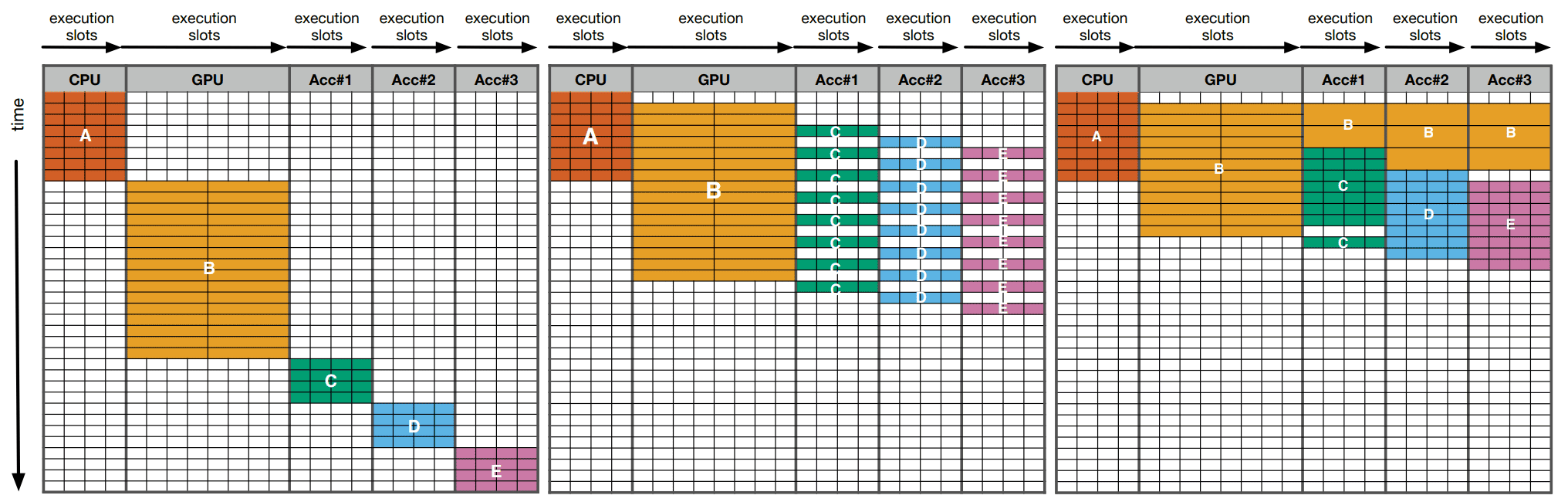
そして、SHMTのランタイムシステムは、これらのHLOPをターゲットハードウェアのタスクキューに割り当てる。HLOPはハードウェアに依存しないため、ランタイムシステムは必要に応じてタスク割り当てを調整できる。
プロトタイプのテストと結果
このコンセプトをテストするため、研究者たちは、一般的なスマートフォンに搭載されているようなチップと処理能力を備えたシステムを構築した。
具体的には、クアッドコアのArm Cortex-A57プロセッサ(CPU)と128個のMaxwellアーキテクチャGPUコアを搭載したNVIDIAのJetson Nanoモジュールを使用して、組み込みシステムプラットフォームをカスタム構築した。Google Edge TPUは、M.2 Key Eスロット経由でシステムに接続された。
CPU、GPU、TPUは、オンボードのPCIeインターフェイス(グラフィックカード、メモリ、ストレージデバイスなどのマザーボードコンポーネントのための標準化されたインターフェイス)を介してデータを交換した。システムのメイン・メモリ(4 GB 64-bit LPDDR4、1,600 MHz、25.6 GB/秒)は、共有データをホストした。Edge TPUにはさらに8MBのデバイスメモリが搭載され、オペレーティングシステムにはUbuntu Linux 18.04が使用された。
ベンチマーク・アプリケーションを使用してSHMTコンセプトをテストしたところ、最もパフォーマンスの高いQAWSポリシーを採用したフレームワークが、ベースライン方式と比較して速度を1.96倍向上させ、エネルギー消費を51%削減するという驚くべき結果を叩き出した。
UCRの電気・コンピューター工学准教授で、本研究の共同筆者であるHung-Wei Tseng氏は、「すでにプロセッサーがあるので、新たにプロセッサーを追加する必要はありません」と語った。
研究者によれば、SHMTの意味は非常に大きいという。既存のスマートフォン、タブレット、デスクトップ、ラップトップ上のソフトウェア・アプリは、この新しいソフトウェア・ライブラリを使用することで、かなり大きな性能向上を達成できるだろう。しかし、高価で高性能なコンポーネントの必要性を減らし、より安価で効率的なデバイスを実現する可能性もある。
エネルギー使用量が削減され、ひいては冷却要件も削減されるため、このアプローチはデータセンターを運営している場合、2つの重要な項目を最適化し、同時に二酸化炭素排出量と水の使用量を削減することができる。
いつものように、システムの実装、ハードウェアのサポート、そしてどのようなアプリケーションが最も恩恵を受けるかについては、さらなる研究が必要だが、このような結果が期待出来るのならば、そのためのリソースは容易に集められるかも知れない。
この論文は、10月にカナダのトロントで開催された第56回IEEE/ACMマイクロアーキテクチャ国際シンポジウムで発表された。この論文は、IEEE(Institute of Electrical and Electronics Engineers:米国電気電子学会)の同業者からも高く評価され、同学会が今夏発行予定の「Top Picks from the Computer Architecture Conferences」号に掲載される12本の論文のひとつに選ばれた。
論文
- Micro ’23: Simultaneous and Heterogenous Multithreading
参考文献
- UNIVERSITY OF CALIFORNIA, RIVERSIDE: Method identified to double computer processing speeds
研究の要旨
すべてのコンピューティング・プラットフォームが複数の種類のプロセッシング・ユニットとハードウェア・アクセラレータを統合しているため、現代のコンピュータの状況は間違いなくヘテロジニアスである。しかし、定着したプログラミング・モデルは、各コード領域で最も効率的な処理ユニットのみを使用することに重点を置いており、ヘテロジニアス・コンピュータ内の処理能力を十分に活用していない。
本稿では、ヘテロジニアス処理ユニットを使用した「真の」並列処理の機会を可能にするプログラミングと実行モデルである同時ヘテロジニアスマルチスレッディング(SHMT)を紹介する。従来のモデルとは対照的に、SHMTは同じコード領域に対して異種の処理ユニットを同時に利用することができる。さらに、SHMTは、並列実行を容易にする抽象化とランタイムシステムを提示する。さらに重要なことは、SHMTは、結果の品質を保証するために、様々な処理ユニットがサポートするデータ精度の不均一性にも対処する必要があるということである。
本稿では、GPUとEdge TPUを備えた組み込みシステムプラットフォーム上でSHMTを実装し、評価した。SHMTはGPUベースラインと比較して、最大1.95倍の高速化と51.0%のエネルギー削減を達成した。





コメントを残す