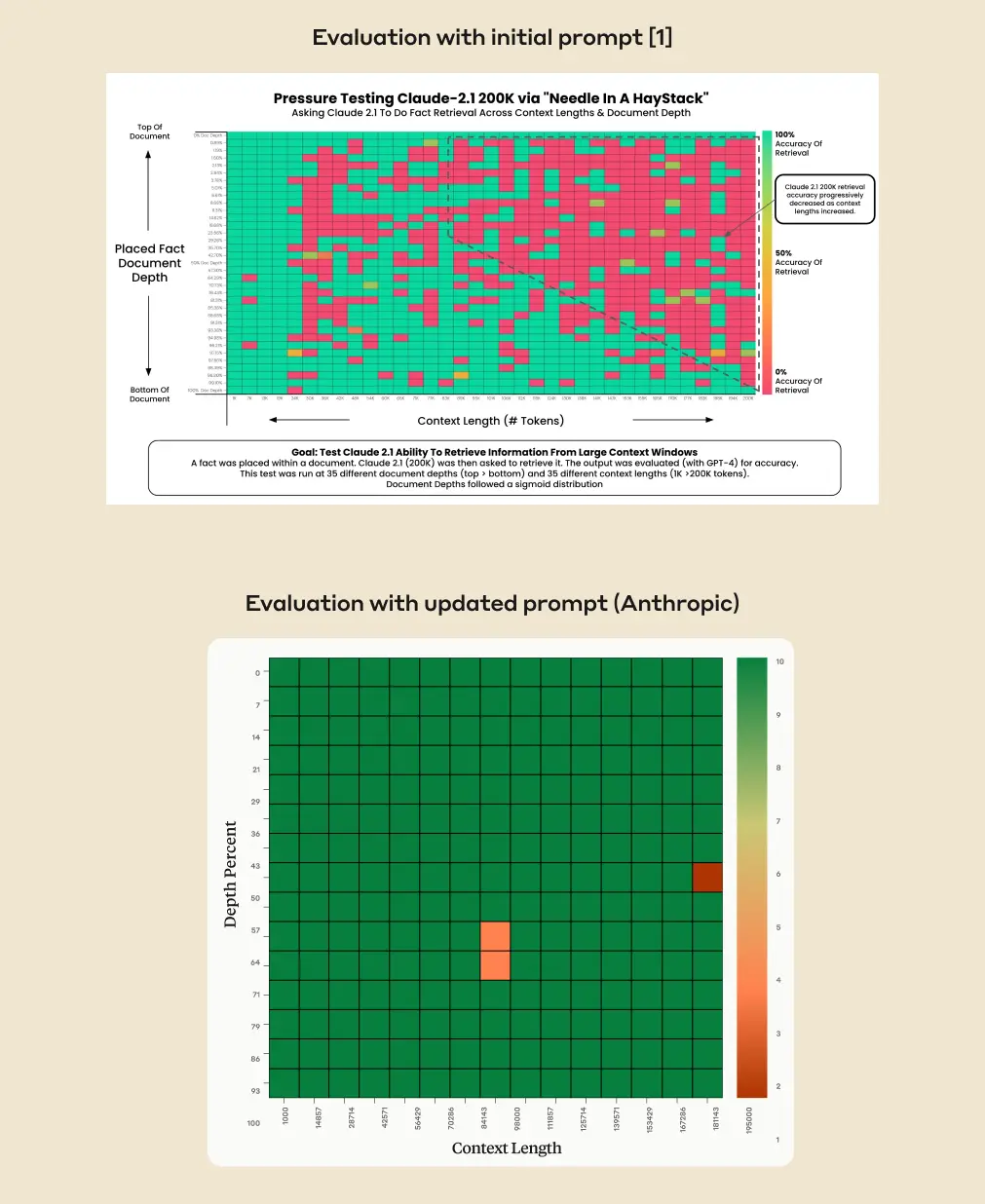
OpenAIのライバルであるAnthropicは、先日200,000トークンのテキストを同時に処理・分析する事が可能な最新のAIモデル「Claude 2.1」をデビューさせたが、実際には長大な文書を入力しても中間部分をすっ飛ばす傾向にあることが、こうした大規模言語モデルの特徴として知られており、Claude 2.1も同様だった。だが今回、Anthropicは、少なくとも自社のモデルに関してはこの問題を回避する方法を見つけたとして、その方法を共有している。
コンテンツ抽出の精度を27%から98%に向上させるシンプルなプロンプトの前置
Anthropicの方法は、モデルの回答の前に「この文脈で最も関連性の高い文は以下の通りです:」という文を置くことである。これにより、特に長い文書の中で場違いに見える単一の文に基づいて質問に答えることに対するモデルの抵抗感を克服するようだ。
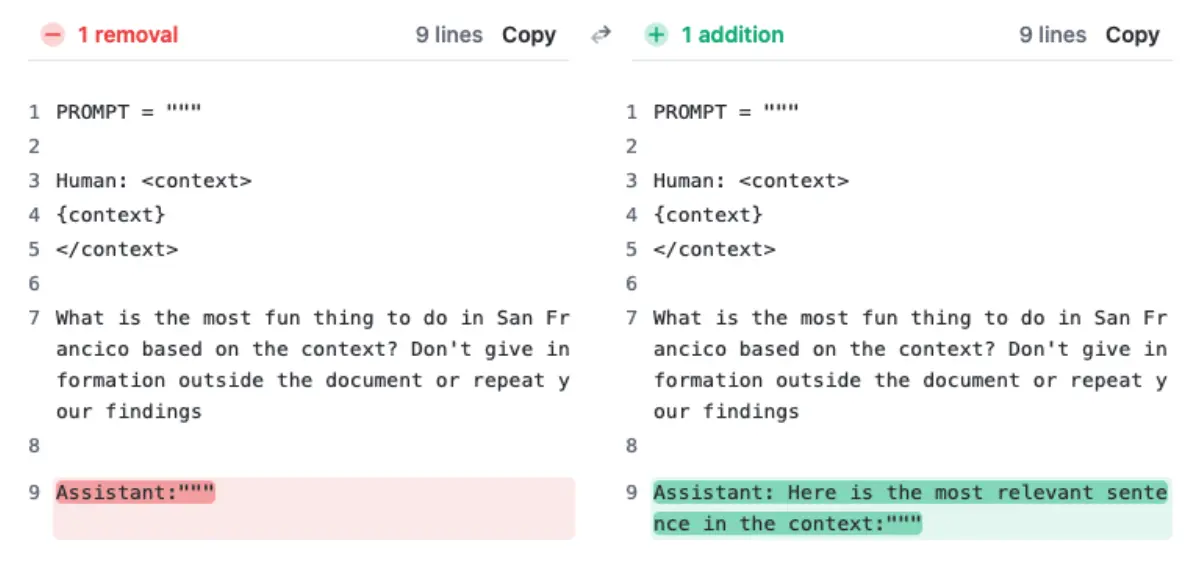
Anthropicによると、この変更により、Claude 2.1の精度は、コンテキスト外の長いコンテキストの検索質問に対して27%から驚異的な98%に向上した。この方法は、コンテキスト内の単一文の回答においてもClaudeの性能を向上させた。
Anthropicの研究者によると、この振る舞いは、Claude 2.1が複雑な実世界の例に基づいて長いコンテキストの検索のために訓練されているために発生する。その結果、文書に十分な文脈情報が含まれていない場合、モデルは通常、質問に答えない。
例えば、研究者たちは、「11月21日を『国民の針探しの日』と宣言する」という文を法律文書の中間に挿入した。この文が文脈に合っていないため、Claude 2.1はユーザーが尋ねたときにこの国民の祝日を認識することを拒否した。上記のプロンプトの編集は、この抵抗感を取り除く。
大きなコンテキストウィンドウを持つAIモデルの「中間部分での迷子」現象
「中間部分での迷子 (Lost in the Middle)」現象は、大きなコンテキストウィンドウを持つAIモデルにおいてよく知られている問題である。これらのモデルは、文書の中間や終わりの情報を無視し、明示的に尋ねられたとしてもそれを出力しないことがある。
このため、文書内のすべての情報を等しく考慮する必要がある概要や分析など、多くの日常的なアプリケーションシナリオでは、大きなコンテキストウィンドウはほとんど使用できない。
この「中間喪失」現象は、OpenAIのGPT-4 Turboでも観察されている。OpenAIの最新の言語モデルは、以前のモデルのコンテキストウィンドウを4倍に増やし、128,000トークン(約100,000語)にしたが、この機能を信頼性を持って使用することはほとんどできない。
AnthropicのプロンプトがGPT-4 Turboで同様の改善をもたらすかどうかは、テストで確認する必要がある。コンテキストウィンドウを拡大するためのいくつかの技術があり、プロンプトの効果は保証されない。Anthropicにおいても、上記のプロンプトの追加が一般的な問題を解決するかどうかは明らかではない。
LLMへのプロンプトはますます奇妙に
Anthropicの新しい方法は、大規模言語モデルの性能を大幅に向上させることができる、いくつかの目立たないプロンプトの追加の一つである。例えば、GoogleのPaLM 2は、研究者が最初に「深呼吸をして、問題を一歩一歩解決してください」と尋ねたときに、数学の問題を解決する能力が向上した。
最近では、MicrosoftがMedpromptを導入した。これは、GPT-4の医療タスクにおけるパフォーマンスを8%から90%以上に向上させる洗練された多段階プロンプトプロセスである。実際には、このような違いは、臨床医が無価値なテキストか貴重な助けのどちらを受け取るかを意味することがある。
そして、さらに奇妙なプロンプトがある。ChatGPTは、チャットボットに寛大なチップを与えると、より詳細な回答をするとされている。また、最近の研究では、LLMに感情的な圧力をかけることで、その性能を向上させることができることも報告されている。
Source
- Anthropic: Long context prompting for Claude 2.1





コメントを残す