
Stability AIはCarperAIラボとの提携により、2つの革新的な大規模言語モデル「FreeWilly1」と「FreeWilly2」を発表した。現在、非商用利用が可能なこれらのモデルは、様々なベンチマークで顕著な性能を示しているが、後者のFreeWilly2は、先日発表されたばかりのLlama 2をベースにしており、オープンソースLLMの開発がいかに速いかを示す好例と言えるだろう。
FreeWillyの両モデルはMetaのLlamaモデルをベースにしている。FreeWillyはLlama 65B、FreeWilly2は、Llama 2 70Bの頑丈な基礎モデルの上に構築されており、標準的なAlpacaフォーマットのSFT(Supervised Fine-Tune)を使用して合成的に生成されたデータセットで、伸長に微調整されている。
大きな物から小さな物へ
FreeWillyモデルのトレーニング方法は、Microsoftの論文「Orca: Progressive Learning from Complex Explanation Traces of GPT-4」に概説されている「Orca Method」を使用した。Orca Methodでは、大きな言語モデルの出力スタイルを単純に模倣するのではなく、小さなモデルに大きな言語モデルの段階的な推論プロセスを教える。これを行うために、Microsoftの研究者たちは、大きなモデル(この場合はGPT-4)のステップバイステップの推論プロセスを含むトレーニングデータセットを作成した。
このような実験の目標は、大きなモデルと同様のパフォーマンスを発揮する小さなAIモデルを開発することである。オルカは、いくつかのテストでは同じようなサイズのモデルより優れているが、元のモデルには及ばない。
FreeWillyチームによると、彼らが選んだプロンプトと言語モデルで60万点のデータセットを作成したが、これはOrcaチームが使用したデータセットのわずか10%程度だという。これにより、必要なトレーニング量が大幅に削減され、モデルの環境フットプリントが改善された、とチームは言う。
モデルの性能を評価するために、Stability AIはEleutherAIのlm-eval-harnessを利用し、基礎モデルを評価するための人間中心のベンチマークであるAGIEvalを追加した。この方法で学習されたFreeWillyモデルは、いくつかの論理タスクでChatGPTと同等の結果を達成しており、Llama 2に基づくFreeWilly 2モデルはFreeWilly 1を明らかに上回っている事が分かった。
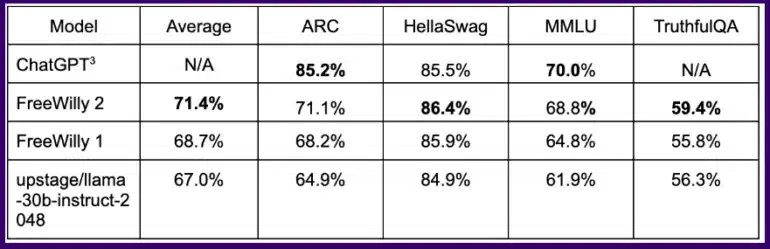
全ベンチマークを平均すると、FreeWilly 2はLlama v2を約4ポイント上回っており、Metaの新しい標準モデルには改善の余地があり、オープンソースコミュニティの貢献を期待している。
全体として、FreeWilly 2はLlama 2を上回っており、重要な一般言語理解ベンチマークMMLUでは、オリジナルのLlama 2がわずかにリードしている。
責任あるリリースの実践を重視
Stability AIはFreeWillyについて、責任あるリリースの実践に重点を置いていることを強調した。同社によると、モデルは社内のレッドチームによる潜在的な有害性のテストを受けたが、同社は安全対策をさらに強化するために外部からのフィードバックを積極的に促している。
FreeWilly1とFreeWilly2は、オープンアクセスLLMの領域における重要なマイルストーンとなる。これらは研究を推進し、自然言語理解を強化し、複雑なタスクを可能にすると期待されている。Stability AIは、これらのモデルがAIコミュニティに無限の可能性を生み出し、革新的なアプリケーションにインスピレーションを与えることを期待している。
Source





コメントを残す