
数ヶ月のプレビュー期間を経て、PyTorch 2.0がPyTorch Foundationにより一般公開された。
オープンソースのPyTorchプロジェクトは、機械学習(ML)トレーニングのために最も広く使用されている技術の1つだ。もともとはFacebook(現Meta)が始めたPyTorch 1.0は2018年に登場し、数年にわたる段階的な改良の恩恵を受けている。
2022年9月、よりオープンなガバナンスを可能にし、より多くのコラボレーションと貢献を促すために、PyTorch Foundationが設立された。この努力は実を結び、2022年12月にPyTorch 2.0のベータ版がプレビューされた。
PyTorch 2.0では、何よりもパフォーマンスが重視されている。実際、主要な新機能の1つにAccelerated Transformers(以前はBetter Transformersとして知られていた)がある。これは現代の大規模言語モデル(LLM)や生成AIの中核をなすもので、モデルが異なる概念間の接続を行うことを可能にする。
PyTorch 2.0では、メインAPIとしてtorch/compileを採用し、NVIDIAとAMDのGPUを搭載したTorchInductorでは、深層学習コンパイラをOpenAI Tritonに依存し、バックエンドのMetal Performance Shadersは、GPUアクセラレーションによるpyTorch on macOS、AWS Graviton CPUでの推論性能向上とその他様々な新しい試作機能・技術が採用されている。また、CPUの高速化のために、GNNの推論とトレーニングのいくつかの「重要な」最適化、およびIntel oneDNN Graphの活用によるCPUパフォーマンスの高速化が行われている。
「我々は、この次世代PyTorchシリーズにおける大幅な性能強化に特に期待しており、PyTorchの未来を形作るために、より大きなイノベーションで開発者を支援します」と、PyTorch Foundationの執行役員、Ibrahim Haddad氏はVentureBeatに書面で声明を発表している。
主な更新内容は以下の通りだ。
- torch.compile は PyTorch 2.0 のメイン API で、モデルをラップしてコンパイルしたモデルを返します。これは完全に付加的な(そしてオプションの)機能であり、それゆえ2.0は定義上100%後方互換性があります。
- torch.compileの基盤技術として、NVIDIAとAMDのGPUを搭載したTorchInductorは、OpenAI Triton深層学習コンパイラに依存して、パフォーマンスの高いコードを生成し、低レベルのハードウェア詳細を隠蔽します。OpenAI Tritonが生成するカーネルは、手書きのカーネルやcublasなどの特殊なcudaライブラリと同等の性能を達成します。
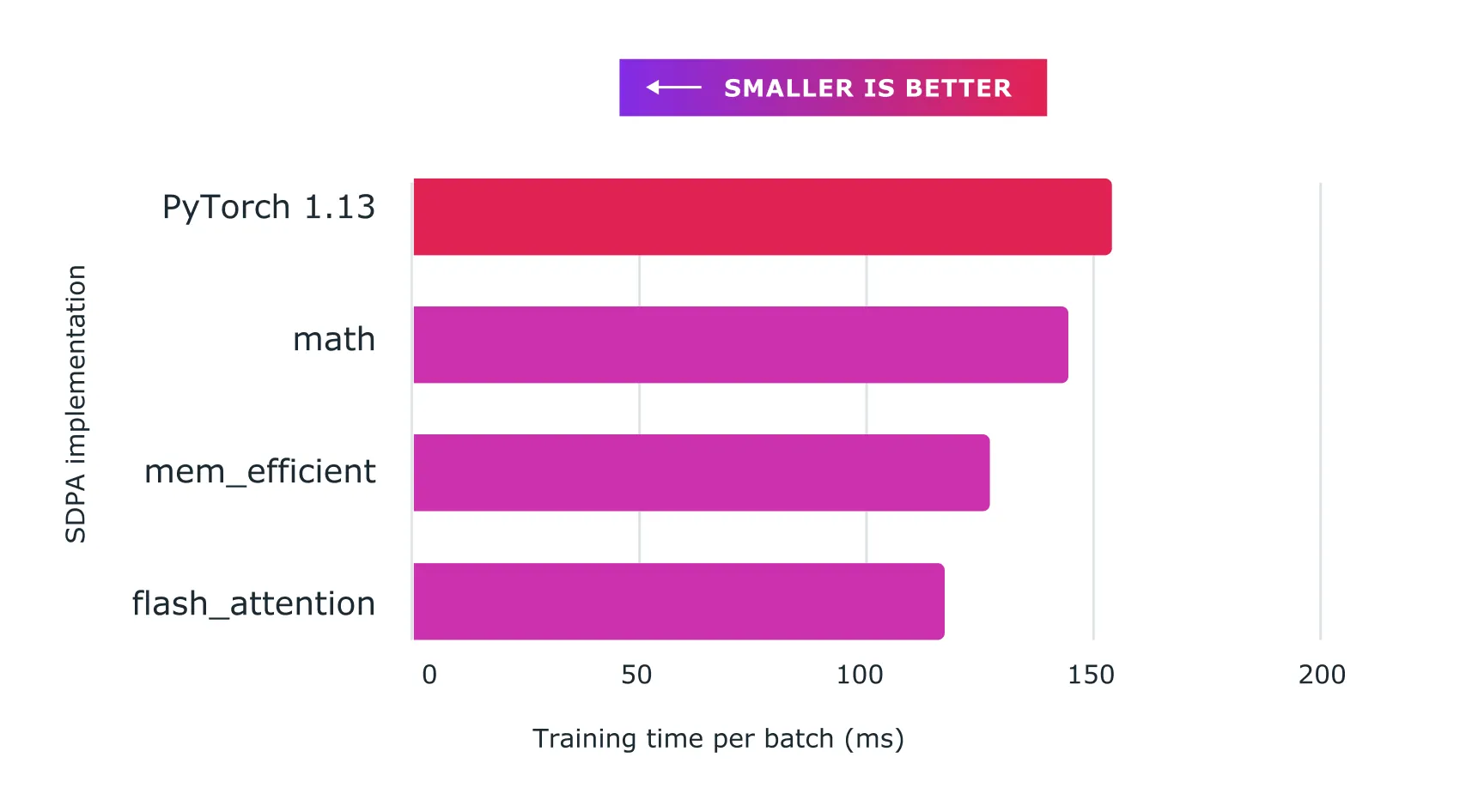
- Accelerated Transformersは、scaled dot product attention(SPDA)用のカスタムカーネルアーキテクチャを使用して、学習と推論のための高性能サポートを導入しています。このAPIはtorch.compile()に統合されており、モデル開発者は新しいscaled_dot_product_attention()演算子を呼び出して、スケールドドットプロダクトアテンションカーネルを直接使用することもできます。
- Metal Performance Shaders (MPS)バックエンドは、MacプラットフォームでGPUアクセラレーションによるPyTorchトレーニングを提供し、最も使用されているトップ60のオペレーションのサポートを追加し、300以上のオペレーションのカバレッジを実現しました。
- Amazon AWSは、AWS Graviton3ベースのC7gインスタンスにおけるPyTorchのCPU推論を最適化します。PyTorch 2.0では、Resnet50やBertの改良を含め、Gravitonでの推論性能が以前のリリースと比較して向上しています。
- TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch、TorchInductorにわたる新しいプロトタイプ機能および技術。
PyTorch 2.0はMLをどう加速させるか?
PyTorchプロジェクトの目標は、最先端のトランスフォーマーモデルのトレーニングや展開をより簡単かつ迅速に行うことだ。
トランスフォーマーは、GPT-3(および現在のGPT-4)などのOpenAIのモデルを含む、現代のジェネレーティブAIの時代を実現するのに貢献した基礎的な技術だ。PyTorch 2.0 accelerated transformersでは、scaled dot product attention (SPDA)として知られるアプローチのためのカスタムカーネルアーキテクチャを使用して、学習と推論のための高性能なサポートが得られる。
トランスフォーマーをサポートできるハードウェアの種類は複数あるため、PyTorch 2.0は複数のSDPAカスタムカーネルをサポートすることが出来る。さらに、PyTorchはカスタムカーネル選択ロジックを統合し、与えられたモデルやハードウェアタイプに対して最高性能のカーネルを選択することが可能だ。
この高速化によって、開発者は以前のPyTorchよりも高速にモデルを学習できるようになり、その影響は計り知れないものがあるだろう。
「たった1行のコードを追加するだけで、PyTorch 2.0はTransformersモデルのトレーニングに1.5xから2.xのスピードアップを与えてくれます。これは、混合精度トレーニングが導入されて以来、最もエキサイティングなことです!」と、HuggingFace transformersのプライマリメンテナ、Sylvain Gugger氏はプレスリリースで述べている。
Source




コメントを残す