Stable DiffusionやDALL・Eなどに代表されるような、拡散型AIモデルは、画像、音声、映像の生成に優れた能力を発揮し、世界に衝撃を与えた。しかし、この性能には代償がある事も知られている。拡散モデルの反復サンプリングプロセスでは、ノイズを徐々に除去して高品質の出力を生成するため、一般に、敵対的生成ネットワーク(Generative adversarial network: GAN)などの従来のシングルステップの生成モデルよりも10~2,000倍の計算量が必要となるのだ。そのため、他のAI分野と同様に、生成AIの研究者は、モデル性能の向上だけでなく、計算負荷の軽減にもますます力を注いでる。
OpenAIの研究チームは、まだ査読を受けていない新しい論文「Consistency Models(一貫性モデル)」で、敵対的な訓練なしでシングルステップのサンプル生成で最先端の性能を達成する、計算効率の良い生成モデルファミリーを紹介している。提案する整合性モデルは、事前トレーニング済みの拡散モデルを抽出するか、スタンドアロンの生成モデルとしてトレーニング出来ると言う
このチームの目標は、効率的なシングルステップの生成を可能にしながらも、拡散モデルの反復的な改良プロセスの利点、例えば、必要に応じて計算の複雑さとサンプルの質をトレードオフしたり、ゼロショットでデータ編集作業を行ったりする能力を維持できる新しい生成モデルファミリーを設計することだ。

一貫性モデルは、連続時間拡散モデルに見られる確率流(PF)常微分方程式(ODE)をベースに構築されている。データを滑らかにノイズに変換するPF ODEがあれば、整合性モデルは、任意の時間ステップの任意の点を軌跡の始点にマッピングするように学習し、生成モデリングを行う。このように、出力は同じ軌道上の初期点と「一致」するように学習され、モデルファミリーに付けられた名前に由来する重要な要素だ。
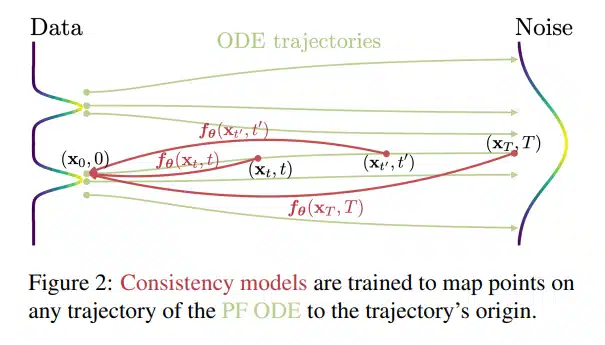
研究者らは、抽出または分離モードのいずれかをサポートする、2つの一貫性モデル訓練アプローチを紹介している。最初のトレーニングアプローチは、数値ODEソルバーと事前学習された拡散モデルを用いて、PF ODE軌道上の隣接する点のペアを取得し、拡散モデルを効率的に一貫性モデルに抽出する。これにより、サンプルの品質を大幅に向上させるとともに、ゼロショットでの画像編集を可能にした。第二のアプローチは、事前学習された拡散モデルに依存することなく学習し、独立した生成モデルファミリーとして一貫性モデルを効果的に確立する。
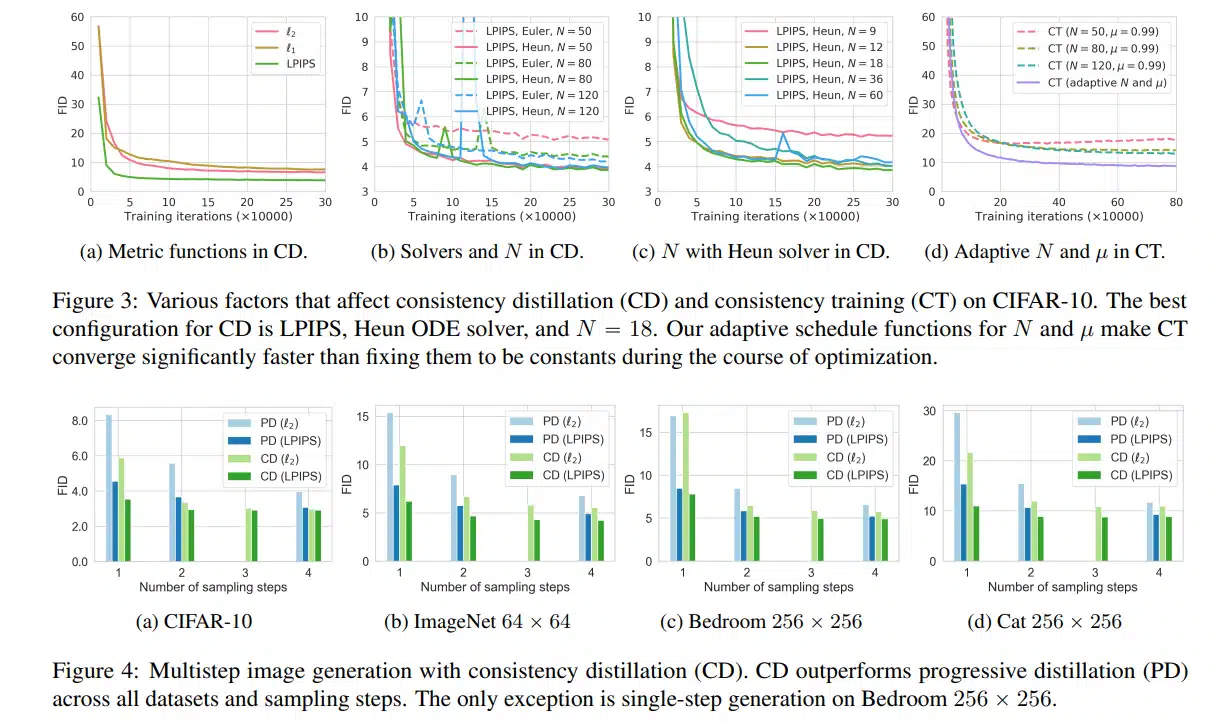
実証研究では、実画像データセットであるCIFAR-10、ImageNet 64×64、LSUN Bedroom 256×256、LSUN Cat 256×256に整合性モデルを適用した。実験では、一貫性モデルを介した抽出は、1ステップの生成でCIFAR-10で3.55、ImageNet 64×64で6.20という最新のFIDスコアを達成し、一貫性モデル単体でも既存の1ステップの非逆行生成モデルより優れていた。
本論文では、提案する整合性モデルによって、シングルステップ生成を行いながら、より効率的なサンプリングを実現できることを実証している。また、このようなモデルは、異なるAI研究分野間でのアイデアや手法の相互交流のためのエキサイティングな展望を提供することができると考えている。
まだ初期の段階なので、拡散モデルと直接比較することは出来ない。しかし、今回の研究は、今世界で最も影響力のあるAI研究機関であるOpenAIが、普及の先にある次世代ユースケースに積極的に目を向けていることを示すものであり、非常に意味のあることだ。
彼らは、現在の高度なGPUの圧倒的なパワーにより行われている生成AIの次を見据えている。この一貫性モデルが大きな一歩となるかどうか、今後の研究に期待したい。
論文
- arXiv: Consistency Models
参考文献
研究の要旨
拡散モデルは、画像、音声、映像の生成において大きなブレークスルーをもたらしたが、反復的な生成プロセスに依存しているため、サンプリング速度が遅く、リアルタイムアプリケーションへの可能性を制限している。この制限を克服するために、我々は、敵対的な訓練なしに高いサンプル品質を達成する新しい生成モデルファミリーである一貫性モデルを提案する。このモデルは、設計上、高速な1ステップ生成をサポートする一方で、サンプル品質と計算を交換するための数ステップのサンプリングも可能である。また、画像のインペインティング、カラー化、超解像などのゼロショットデータ編集をサポートし、これらのタスクに関する明示的なトレーニングを必要としない。整合性モデルは、事前に訓練された拡散モデルを抽出する方法として、または独立した生成モデルとして訓練することができます。広範な実験を通して、我々は、1ステップおよび数ステップの生成において、拡散モデルのための既存の蒸留技術を凌駕することを実証する。例えば、CIFAR-10では3.55、ImageNet 64×64では6.20という最新鋭のFIDを1ステップ生成で達成した。また、独立した生成モデルとして学習させた場合、整合性モデルは、CIFAR-10、ImageNet 64×64、LSUN 256×256などの標準ベンチマークにおいて、1ステップの非逆行生成モデルを凌駕する。





コメントを残す