
Metaは、NVIDIAの最先端アクセラレータを用いて、同社の大規模言語AIモデル「Llama 3」のトレーニングに使用している、2つの新しいデータセンター・クラスタを構成するハードウェア、ネットワーク、ストレージ、デザイン、パフォーマンス、ソフトウェアの詳細を発表した。
Datacenter Dynamicsが報じたように、最適なコンピューティング・パワーを達成するため、Metaは音声認識や画像認識といった消費者向けアプリケーションにおけるAI研究とLLM開発を唯一の目的として、2つの新しいデータセンター・クラスターを開発した。同社は、NVIDIAのH100 AI GPUを統合することを決定し、両クラスタには24,576ユニットが搭載されている。
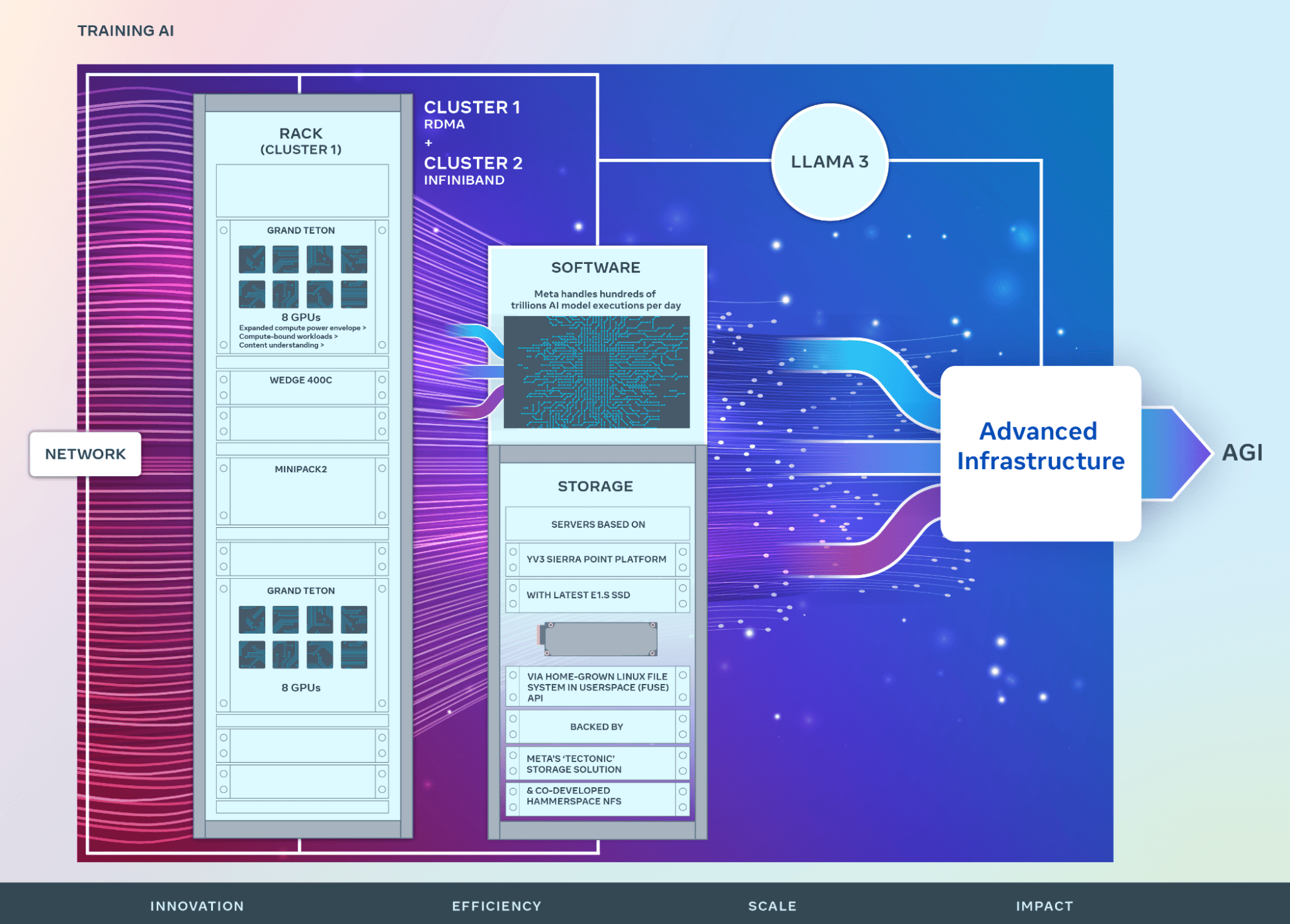
2つのクラスタはそれぞれ、24,576個のNVIDIA H100 GPUを搭載する。1つはRDMA over RoCE 400Gbpsイーサネットネットワークシステムで、Arista 7800スイッチとWedge400およびMinipack2 OCPラックスイッチを使用し、もう1つはNVIDIA Quantum2 400Gbps InfiniBandファブリックを搭載し、シームレスな相互接続を実現している。
もう一つのクラスタはMeta独自のGrand Teton OCPハードウェア・シャーシにはGPUが搭載され、MetaのTectonic分散型フラッシュ最適化エクサバイト・スケール・ストレージ・システムに依存している。
これは、Metaが開発したユーザー空間のLinuxファイルシステム(FUSE)APIを介してアクセスされ、AIモデルのデータニーズとモデルのチェックポイントに使用される。ブログによると、”このソリューションは、何千ものGPUがチェックポイントを同期して保存・ロードすることを可能にし(どのストレージソリューションにとっても課題である)、同時にデータロードに必要な柔軟で高スループットのエクサバイトスケールのストレージを提供する”とのことだ。
ここでMetaは、Hammerspaceと提携している。「このAIクラスターの開発者体験要件を満たすために、並列ネットワークファイルシステム(NFS)展開を共同開発しました。Hammerspaceは、コードの変更が環境内のすべてのノードに即座にアクセスできるため、エンジニアが何千ものGPUを使用してジョブのインタラクティブなデバッグを実行することを可能にします。当社のTectonic分散ストレージソリューションとHammerspaceを組み合わせることで、スケールに妥協することなく、高速な反復速度を実現できます」と、述べている。
TectonicとHammerspaceの両社のストレージは、MetaのYV3 Sierra Pointサーバーに大容量のE1.SフォーマットSSDを搭載している。これらは、耐障害性とともに、「サーバーあたりのスループット容量、ラック数の削減、関連する電力効率の適切なバランスを達成するためにカスタマイズされた」OCPサーバーである。
Metaの取り組みは更に続く。同社によれば、この発表は、我々の野心的なインフラロードマップの一歩とのことだ。Metaは2024年末までには、約60万台のH100に相当する計算能力を有する事を目指しており、35万台のNVIDIA H100 GPUを含むインフラ構築を継続的に成長させることを目標としている。
Source
- Meta: Building Meta’s GenAI Infrastructure
- via Datacenter Dynamics: Meta reveals details of two new 24k GPU AI clusters







コメントを残す