カーネギーメロン大学、南カリフォルニア大学、テルアビブ大学と並ぶMeta AIの研究者たちは、本日、RLHF(einforcement Learning from Human Feedback:人間のフィードバックからの強化学習)なしで微調整した650億パラメータのLLaMaの派生モデルである「LIMA」を発表した。同社は、このLIMAについて、OpenAIの最新LLMGPT-4と同等かそれ以上のパフォーマンスを示すと述べている。
Less is More for Alignment
LIMAとは、「Less is More for Alignment」の頭文字をとったものだ。その名の通り、あらかじめ訓練されたAIモデルであれば、数例で十分な品質が得られることを示すものである。
この場合の少ない例とは、他の研究論文、WikiHow、StackExchange、Redditなどのソースから、Metaが1,000の多様なプロンプトとそのアウトプットを手動で選択したことを意味している。
興味深いことに、この新しい言語モデルの性能の注目すべき点の1つは、トレーニングデータに含まれていない未知のタスクにうまく汎化できることだ。つまり、LIMAは学習した知識を新しいタスクや見慣れないタスクに適用することができ、研究者が共有する柔軟性と適応性のレベルを示している。
これらの例を用いて、オープンソースの言語モデルである、650億パラメータのLLaMAモデルを独自に改良した。Metaは、OpenAIがモデルのチューニングに使用し、AIの将来において重要な役割を果たすと見ている、高価なRLHFを回避した。
人間が制御する応答、具体的にはGPT-4、Bard、DaVinci-003(RLHFあり)と比較すると、LIMAが生成した応答は非常に印象的だった。例えば、43%のケースで、LIMAからの応答はGPT-4と同等か、GPT-4より優れていた。Bardの場合、58%のケースでLIMAが好まれ。DaVinci-003の場合は、65%近くまで上昇した。
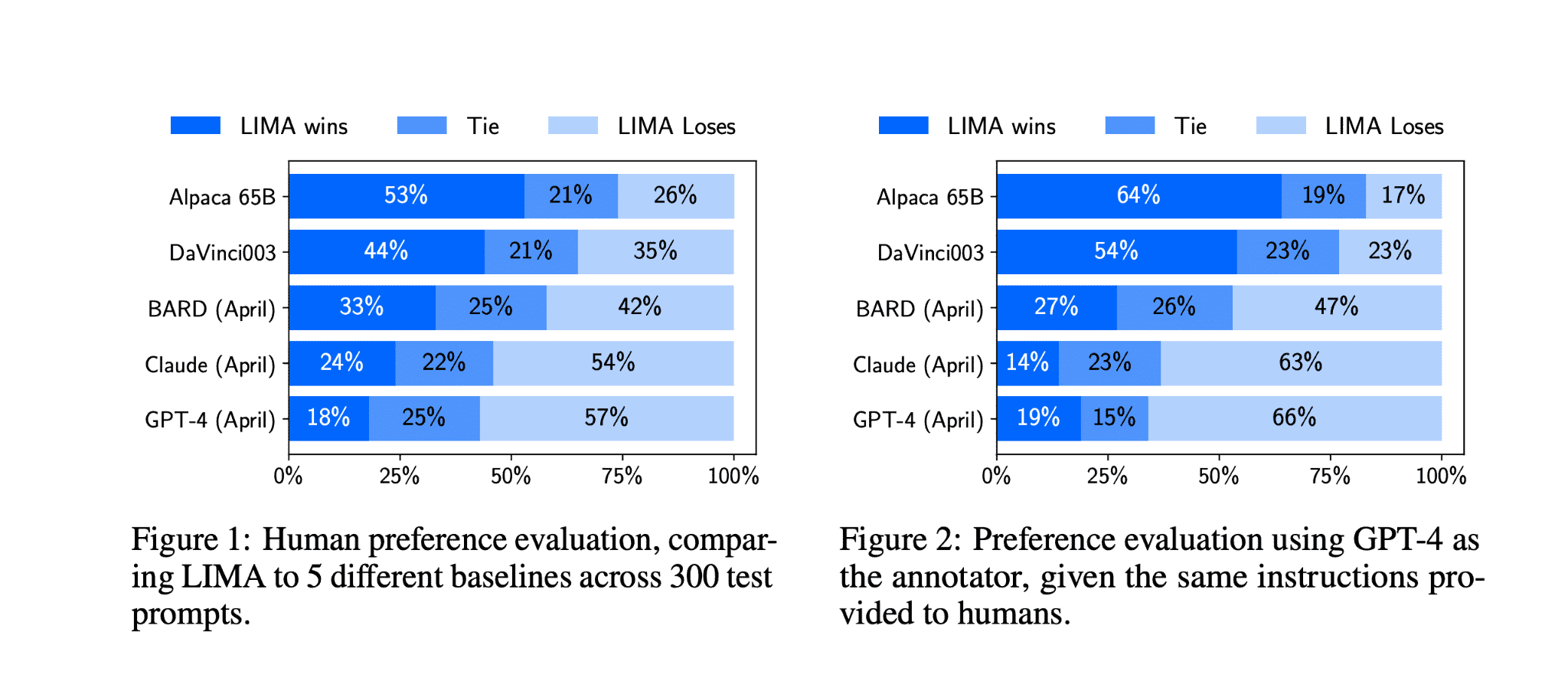
興味深いのは、限られたインストラクションチューニングデータのみで、LIMAのようなモデルが高品質なアウトプットを生成できることだ。
Metaの研究チームは、これらの結果から、言語モデルは事前学習によってその知識の多くを獲得し、いくつかの例を用いた限定的な微調整で、高品質のコンテンツを生成するモデルを教えるのに十分であることを示唆していると述べている。
その結果、OpenAIが採用している人間のフィードバックによる大規模なトレーニングは、これまで考えられていたほど重要ではない可能性がある。この点は、Metaが研究論文で明確に指摘している。
Metaはこの発見を「表面的アライメント仮説」と定義している。それによると、事前トレーニング後のいわゆるアライメント段階は、主にモデルがユーザーと対話する際に思い出すことのできる特定のスタイルや形式を教えることだという。
つまり、ファインチューニングは、実質よりもスタイルが重要なのだ。これは、OpenAIのRLHFのような、特に広範囲で複雑なファインチューニングプロセスの常識とは対照的であろう。
Metaの研究チームは、LIMAには2つの限界があると見ている。1つ目は、高品質の事例でデータセットを構築することは、スケールアップが難しいアプローチであるということだ。第二に、LIMAはGPT-4のような既に製品として提供されているモデルほど堅牢ではない。
LIMAは多くの優れた答えを生成するが、「敵対的なプロンプト」や「不運なサンプル」があると、弱い答えになる可能性があると研究チームは述べている。それでもLIMAは、“AIモデルのアライメントと微調整という複雑な問題を、シンプルなアプローチで解決できることを示している”と、Metaのチームは述べている。
Meta社のAI研究責任者であるYann LeCun氏は、GPT-4や同様のモデルの背後にある努力が相対的に低く評価されていることについて、現実的な見方をしている。彼は、大規模な言語モデルは近未来の要素であり、中期的には少なくとも「大きな変化なしには」役割を果たせないだろうと見ている。
論文
参考文献
- LinkedIn: Yann LeCun氏のポスト
研究の要旨
大規模な言語モデルは、2つの段階で訓練される。(1) 汎用的な表現を学習するために、生のテキストから教師なし事前訓練、(2) 最終タスクやユーザーの好みに合わせてよりよく調整するために、大規模な命令チューニングと強化学習。LIMAは、標準的な教師ありロスで微調整された650億パラメータのLLaMa言語モデルで、強化学習や人間の好みのモデリングを行わず、慎重にキュレーションされた1,000のプロンプトとレスポンスのみを対象にトレーニングすることにより、これら2段階の相対的重要性を測定した。LIMAは、旅行計画の立案から代替史の推測に至るまで、複雑なクエリを含むトレーニングデータのほんの一握りの例から、特定の応答フォーマットに従うことを学習し、驚くほど強力な性能を発揮した。さらに、このモデルは、訓練データにない未知のタスクにもうまく汎化する傾向がある。ヒトを対象とした研究では、LIMAからの回答は43%のケースでGPT-4と同等か厳密に優先される。この統計は、Bardと比較すると58%、ヒトのフィードバックで訓練したDaVinci003と比較すると65%という高い数値を示している。これらの結果から、大規模言語モデルのほぼすべての知識は事前学習で学習され、高品質の出力を生成するためにモデルを学習させるには、限られた指導チューニングデータのみが必要であることが強く示唆される。





コメントを残す