
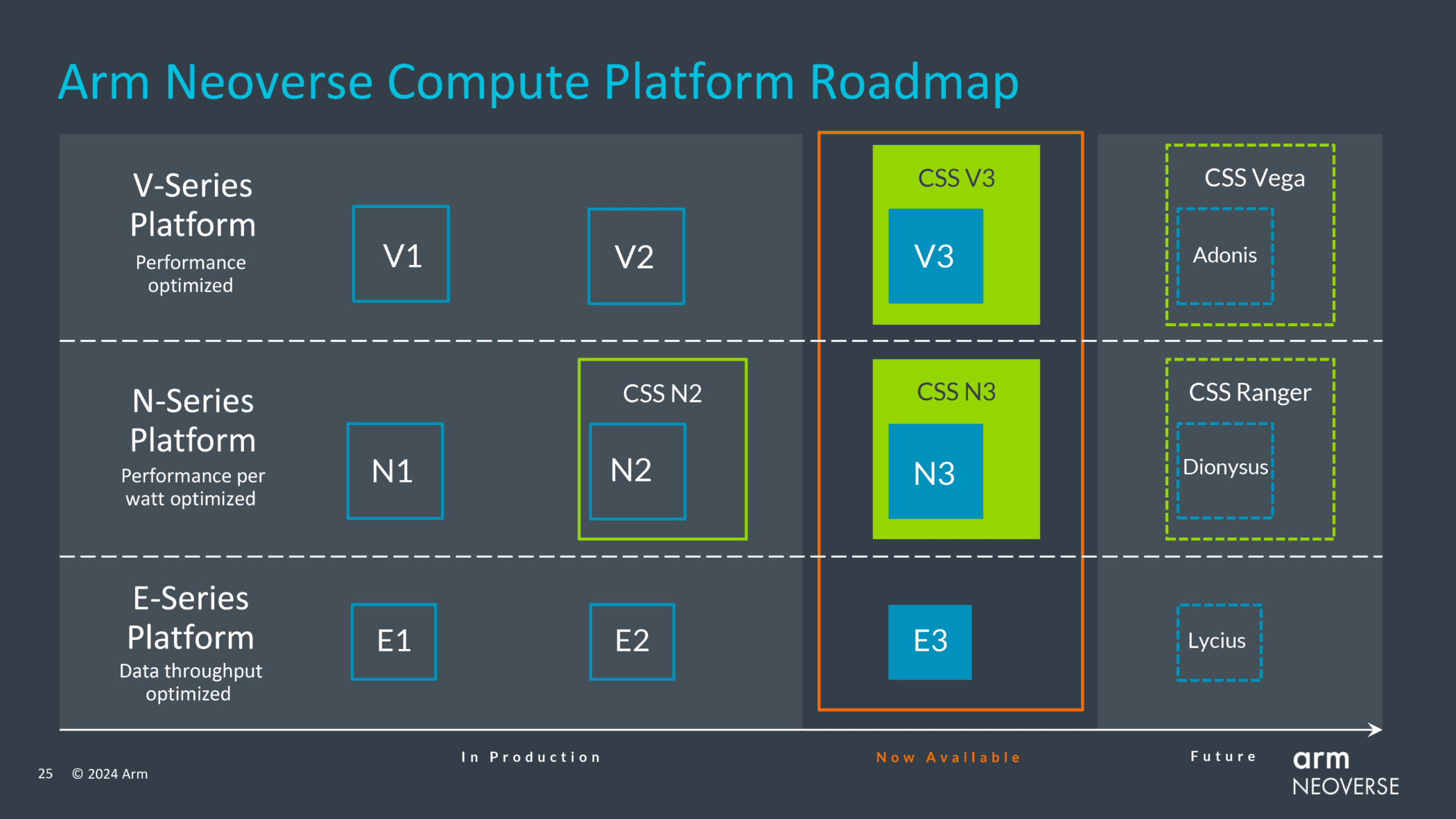
チップ設計者企業のArmは、データセンター・プロセッサ向け次世代汎用CPUコア「Neoverse V3」「Neoverse N3」「Neoverse E3」を発表した。それぞれハイパフォーマンス・コンピューティング(HPC)、汎用CPUインスタンスおよびインフラストラクチャ・アプリケーション、エッジ・コンピューティングおよび低消費電力アプリケーションを対象としている。
加えて同社はNeoverse Compute Subsystemの追加設計「CSS N3」及び「CSS V3」を発表した。これらはその名前が示す通り、新しいN3およびV3 Neoverseコアを中心に設計されている。
Armは昨年、Neoverse Compute Subsystems(CSS)を発表した。これは、プロセッサ・コアだけでなく、事前に検証済みのコンポーネントを含めることで、ArmのパートナーはCSSを独自のIPで拡張し、設計開始からテープアウトまで約9カ月かかると同社が見込んでいるように、設計を迅速に市場に投入することができる。CSSは、CPUコア複合体、メモリ、I/Oインターフェースを含み、クラウドコンピューティング、ネットワーキング、AIなど、特定の市場セグメントにおける特定のユースケース向けに最適化されている。
CSSを使用することで、パートナーはシステムレベルおよびワークロード固有の差別化に注力できる一方、基盤となるコンピュート機能についてはArmのテクノロジを活用することが可能だ。一方、ArmのNeoverse CSSは、Arm Total Design(Armの20のパートナーからのIPのパッケージ)だけでなく、ArmのChiplet System Architecture CSAと、CSSを互換性のあるサードパーティのシリコンとスティッチングするためのUCIeインターフェイスもサポートしている。
最初に発表されたのはCSS N2で、その後Microsoftに採用され、Azureデータセンター向けの同社のカスタムチップ「Cobalt 100」プロセッサに組み込まれている。
Neoverse V3:最大128コア、CXL 3.0及びHBM3

ArmのNeoverse V3は、同社史上最高性能のハイエンドCPUコアである。V3は、最高性能のアプリケーションを対象としており、Arm Neoverse CPUコアの中で最高のシングルスレッド性能を発揮する。SVE2 SIMD拡張で強化されたArmv9-A(v9.2)命令セットアーキテクチャ(ISA)をベースにしており、64KB + 64KB(命令 + データ)のL1キャッシュと、ECC機能付きの1MB/2MB/3MBのL2キャッシュを備えている。
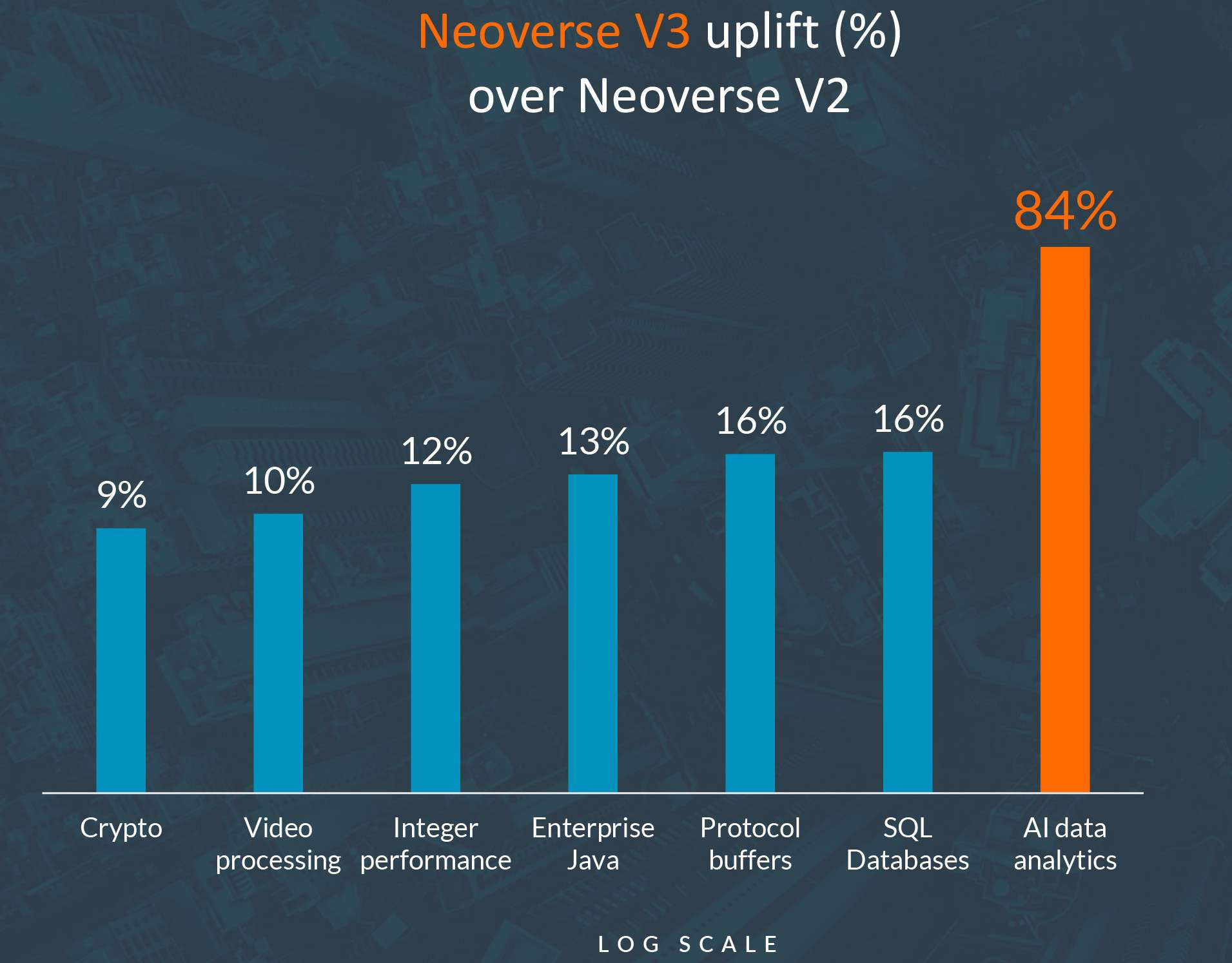
Armのシミュレーションによれば、新しいNeoverse V3プロセッサは、AIデータ分析においてNeoverse V2よりもなんと84%も性能を向上させることができるとのことだ。
これには、64個のNeoverse V3コア(SVE/SVE2、BFloat16、およびINT8 MatMul対応)、12チャネルDDR5/LPDDR5およびHBMメモリ対応のメモリサブシステム、CXL対応の64レーンPCIe Gen5、ダイ間インターコネクト、UCIe 1.1、および/またはカスタムPHYが含まれる。Neoverse V3は、ソケットあたり128コアまで拡張可能で、かなり強力なサーバーCPUを実現する。
また、VシリーズCPUコアとしては初めて、ArmはこのIPの既製のCSSバージョンを提供し、顧客のチップ設計に迅速に統合できるようにしている。CSS構想自体はまだかなり新しいものだが、Armによると、この戦略は非常に成功しており、Microsoft(Cobalt 100)のような資金力のあるクラウドサービスプロバイダーが、自社のチップ設計を迅速にまとめ、ハードウェアをサービスに投入するために、この戦略を急速に採用しているという。そこでArmは、高性能な顧客、特にカスタム・アクセラレータ設計と組み合わせるために実績のあるCPU IPブロックを必要とするだけの顧客に、同じレベルのシンプルさを提供しようとしている。

Neoverse N3:最大32コアのワット当たり単価が20%向上
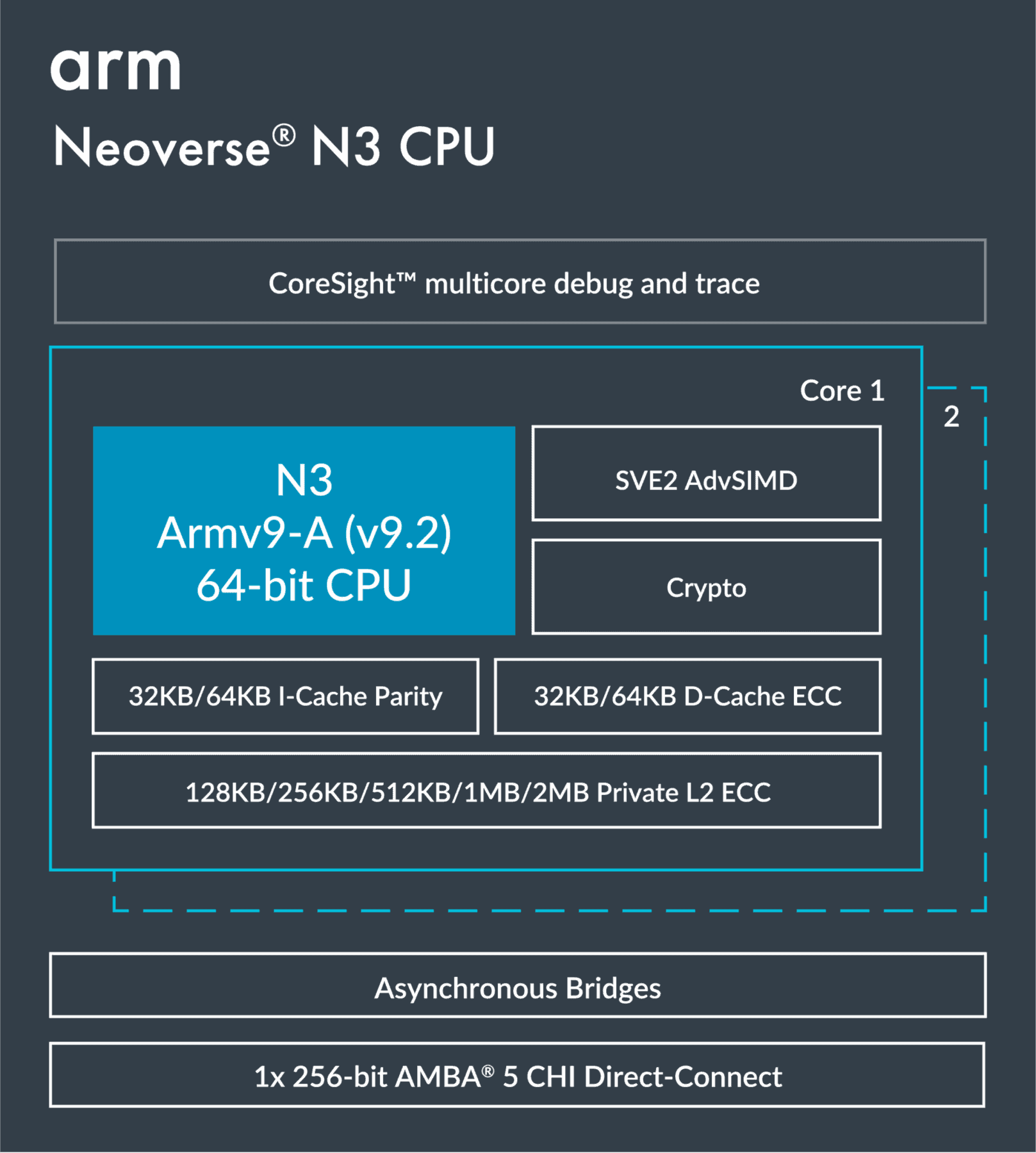
ArmのNeoverse N3コアは、性能と消費電力のバランスが求められる汎用CPUインスタンスやインフラアプリケーション向けの、同社初のArmv9.2ベースのコアである。SVE2を搭載したこれらのArmv9.2コアは、32KB/64KB + 32KB/64KB(命令 + データ)のL1キャッシュと、ECC機能を備えた128KB~2MBのL2キャッシュを搭載できる。
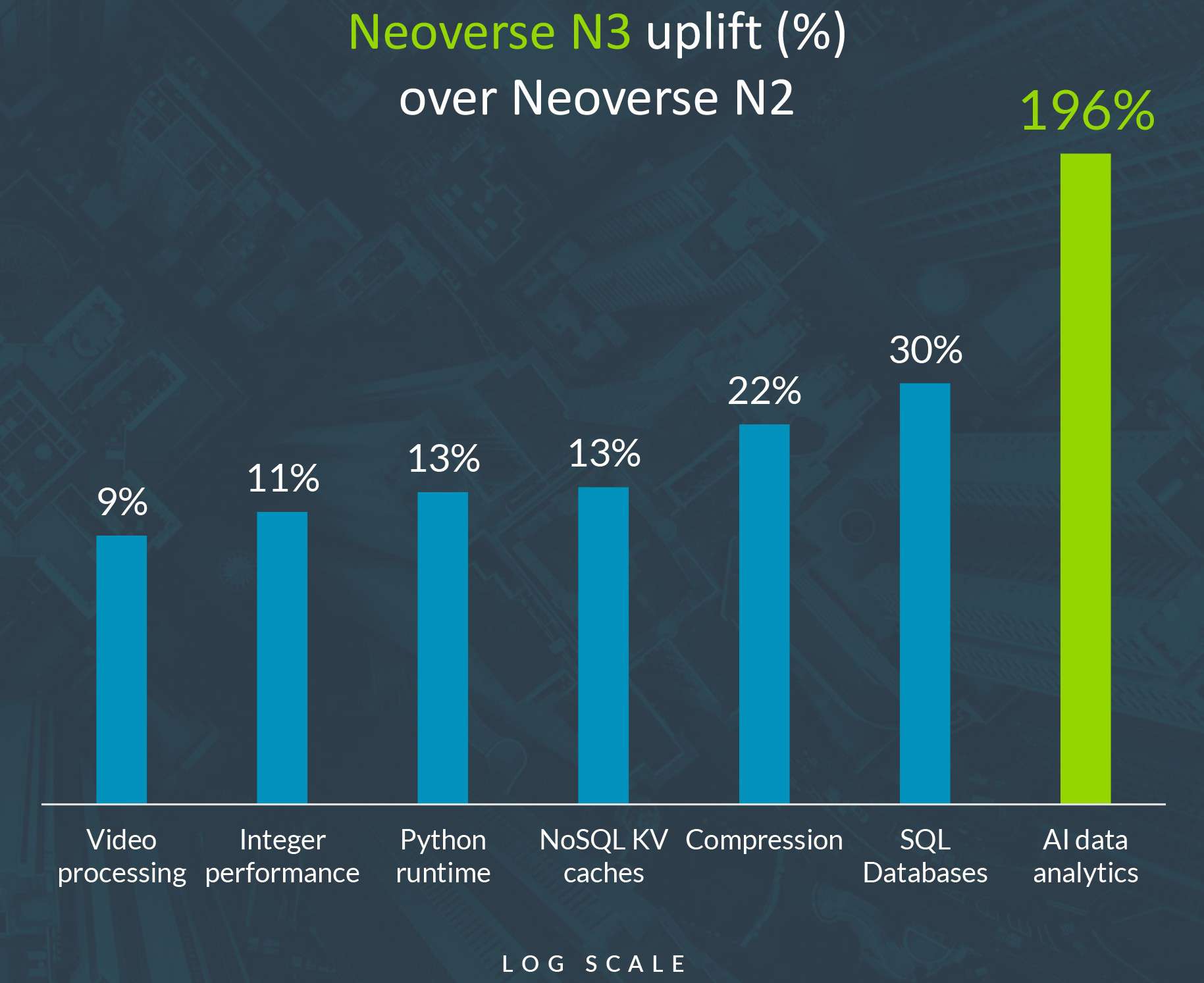
性能面では、32コアのNeoverse N3プロセッサのシミュレーションが、32コアのNeoverse N2プロセッサのシミュレーションを9%から30%(ワークロードによって異なる)上回るとしている。AIデータ分析では、シミュレーションしたNeoverse N3ベースのSoCは、シミュレーションしたNeoverse N2チップよりも196%高速である。
ArmのNeoverse CSS N3は、1つのN3 Compute Subsystemは、32個のN3コア、4つの40ビットDDR5/LPDDR5メモリ・チャネル、CXLサポート付き32 PCIe Gen5レーン、高速ダイ間リンク、UCI 1.1をサポートしている。

全体として、ArmはN3 CSSについて、N2 CSSに比べてワットあたり平均20%の性能向上をアピールしている。全体的な性能向上は通常、特定のワークロードによって10%から30%の範囲になる。
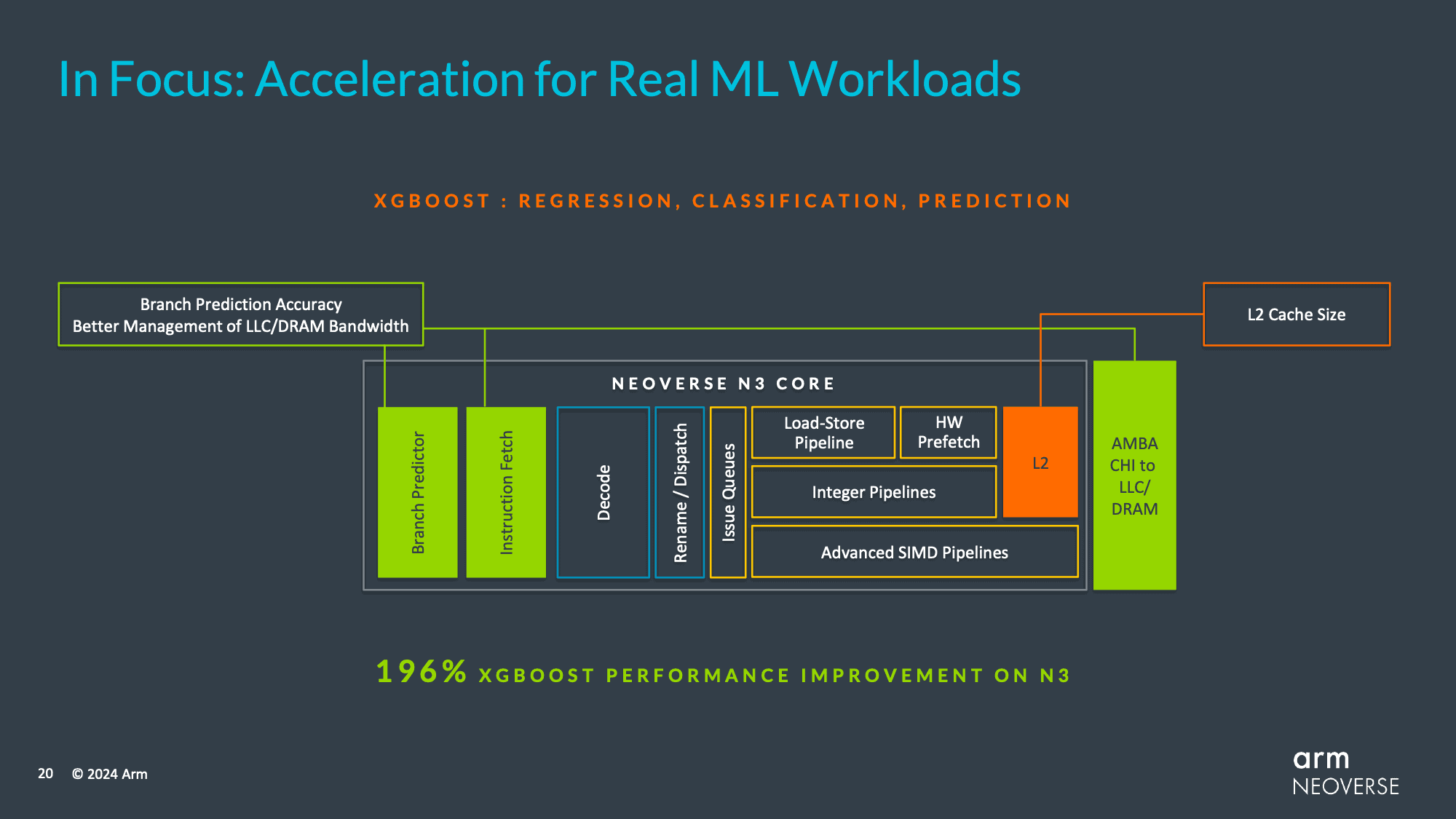
まず、N3 CSSのL2キャッシュサイズは、N2の1MBからコアあたり2MBに拡大された。実際、Armは全体的なキャッシュとメモリサブシステムにもかなりの労力を費やしており、CPUコアと最終レベルキャッシュ(およびそれ以降)間のトラフィックとメモリ帯域幅をよりよく管理するために、コヒーレントホストインターフェースに未公表の微調整を加えた。
これらの改良を総合すると、ArmのXGBoost性能は196%向上し、V3 CPUコアが同じワークロードで84%向上したのと同様の効果が得られる。これは、データ分析/XGBoostが全体的に極端な異常値であることを意味するが、Armがこの次世代CPUアーキテクチャでどこに力を入れているかを示すものである。
これらのコアの改善以外では、N3はV3も得たI/Oとメモリの改善の多くも特徴としている。Armは詳細なリストを提供していないが、最新のPCIeとCXL標準(これはおそらくそれぞれPCIe 5.0とCXL 3.0)をサポートしているようだ。注目すべきは、Armの以前のロードマップでは、この世代のハードウェアはPCIe 6.0をサポートする予定だったが、V3ではサポートされなかったため、Armは一歩後退せざるを得なかったようだ。
最後に、V3 CSSと同様に、N3 CSSもダイ・ツー・ダイ相互接続を採用している。しかし、Nシリーズハードウェアの他のほとんどの側面と同様に、これは単一のインターコネクトに縮小されている。そのため、チップ・ベンダーはN3をダイ設計に直接組み込むか、外部アクセラレーター・チップレットに接続するかを選択できる。
Sources







コメントを残す