ChatGPTは、自分の置かれた状況を受け止め、それに対する現実的な行動を出力する“ジェネレーティブエージェント”を作成するための新しい方法を提供する可能性があるとする研究が、Googleとスタンフォード大学によって発表された。
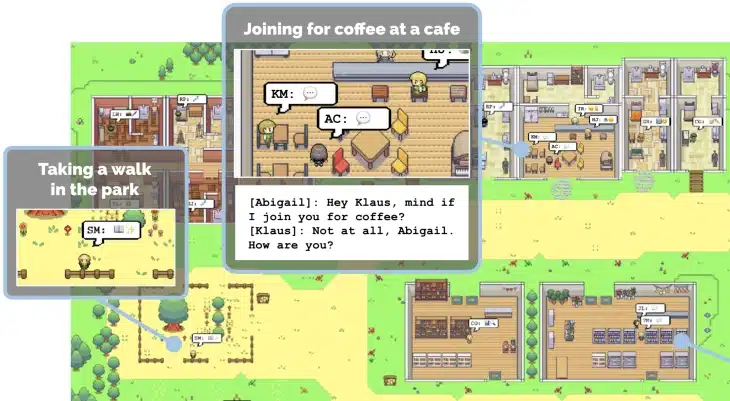
「本研究では、ゲーム『The Sims』を彷彿とさせるサンドボックス環境に25人のエージェントを配置し、ジェネレーティブエージェントを実証しました。ユーザーは、エージェントが彼らの1日を計画し、ニュースを共有し、関係を形成し、グループ活動を調整するように観察し、介入することができます」と、研究者は説明する。
この研究では、ChatGPTのインスタンスを25個使用して、ファンタジーの町に住む架空の人物を作成した。25個のChatGPTインスタンスはそれぞれ、特定の人物の役割を果たし、他のChatGPTと会話することが出来る様になっており、ファンタジーの町を再現している。結果は非常に興味深く、リアルな人間の振る舞いを模倣できるとされている。
研究者らは、周囲の状況を受け取り、リアルな行動を出力する「ジェネレーティブエージェント」を作成するために、最新の機械学習モデルを適用した。これにより、まるで人間の振る舞いのような動きをしたという。それぞれのChatGPTは、特定の人物の情報を入力されることで、それぞれが次の行動を思いつくように促される。
ただし、それぞれのChatGPTが行動を実行するためには、複雑で隠れたテキストレイヤーが使用される。エージェントは、部屋の中を歩いたり、キャビネットに近づいたりするわけではない。代わりに、これらの情報を統合して整理する複雑なテキストレイヤーを使用している。
例えば、あるキャラクターは以下のようなプロフィールを設定された:
John Linはウィロー・マーケット&ファーマシーの薬局店員で、人助けが大好きだ。大学教授である妻のMayと、音楽理論を学ぶ学生の息子Eddyと3人で暮らしている。John Linは家族をとても愛している。John Linは、隣の老夫婦、Sam Mooreとjennifer Mooreを数年前から知っている。
John Linは、Sam Mooreが親切でいい人だと思っている…
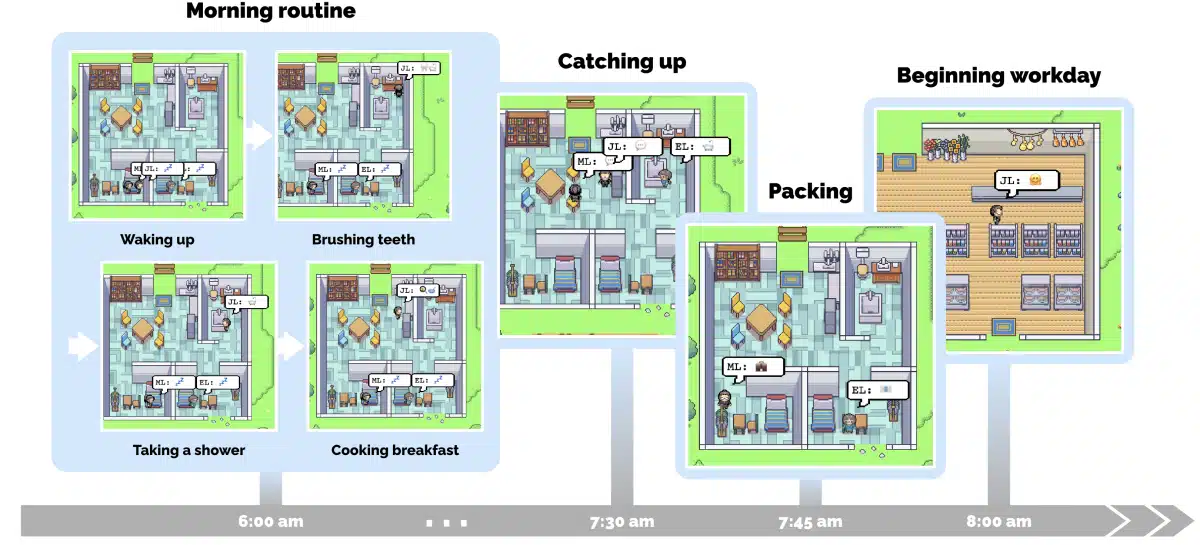
その情報をもとに、エージェントは時間と状況を考慮して次の行動を考えるように促される。例えば、上記のJohnエージェントに「今は朝の8時で、彼は今起きたばかりです。彼は何をするのでしょうか?」のように。するとエージェントは、歯を磨き、妻にキスをして(できればこの順番で)、服を着て、キッチンに行く。
息子のEddyを表現する別のChatGPTインスタンスにも異なるプロンプトが与えられると、同様に歯磨きをしてキッチンに向かった。
その後、2人(のエージェント)は、キッチンで出会い会話を始めるのだ。だが、このエージェントは同じ仮想空間に「いる」わけではない。その代わり、Johnが着替えを終えてキッチンに移動すると言うと、実験フレームワークが息子のEddyがそこにいることを知らせる。Eddyは独立しており、様々な行動にかかる時間の見積もりに基づいて、キッチンに移動することを決めたからだ。そして、実験フレームワークは、2人が同時に同じ部屋にいる状況であること、ストーブが付いていること、誰も席に着いていないテーブルがあること等を伝えると、彼らはそれぞれが行動し、席について会話を始めるというわけだ。
この実験の最も興味深い点は、ChatGPTが、特定の状況下で人間がどのように行動するかを推測することができるということだ。ChatGPTは、人間の行動をテキストアドベンチャーのようにプレイしているように見える。これにより、購入したり、公園を散歩したり、仕事に行ったりするという普通の人間の行動をシミュレートできるのだ。
これは、ゲームや仮想環境での人間の相互作用のシミュレーションにおいて、広範囲に活用できることを示唆している。
この実験は、実際にPhaser Webゲーム フレームワークで構築されたHeroku インスタンス上で実行されているデモ ワールドにアクセスすることで、確認する事が出来る。
ただし、この研究は、まだ査読や公式の出版に至っていないため、慎重に評価する必要がある。また、このアプローチには問題があるため、さらなる改良が必要だ。例えば、ChatGPTのインスタンスが多数あるため、メモリが不足する可能性がある。また、複雑なテキストレイヤーを使用することにより、不必要な遅延が発生する可能性がある。
とはいえ、ChatGPTを用いたこの実験は、現在の技術の可能性を示すものであり、今後の研究において重要な参考となることが期待される。
論文
参考文献
研究の要旨
人間の行動の信頼できるプロキシは、没入型環境から対人コミュニケーションのリハーサル空間、プロトタイピングツールに至るまで、インタラクティブなアプリケーションを強化することが出来る。本論文では、人間の行動をシミュレートする計算機ソフトウェアエージェントであるジェネレーティブエージェントを紹介する。ジェネレーティブエージェントは、目覚め、朝食を作り、仕事に向かう。アーティストが絵を描き、作家が文章を書く。ジェネレーティブエージェントを実現するために、大規模な言語モデルを拡張し、自然言語を使ったエージェントの経験の完全な記録を保存し、時間の経過とともにそれらの記憶をより高いレベルの反映に合成し、動的にそれらを取り出して行動を計画するアーキテクチャを説明する。この生成エージェントは、「ザ・シムズ」にインスパイアされたインタラクティブなサンドボックス環境を構成し、エンドユーザーが自然言語を使って25人のエージェントからなる小さな町と対話することが出来る。例えば、あるエージェントがバレンタインデーのパーティーを開きたいというユーザが指定した1つの概念だけで、エージェントは自律的に2日間に渡ってパーティーへの招待状を広げ、新しい知人を作り、パーティーへのデートに誘い、適切な時間に一緒にパーティーに現れるように調整する。私たちは、エージェントアーキテクチャの構成要素である観察、計画、内省が、それぞれエージェントの行動の信憑性に決定的に寄与することを、アブレーションを通じて実証している。大規模な言語モデルと計算された対話型エージェントを融合させることで、人間の行動の信憑性のあるシミュレーションを可能にするアーキテクチャと対話パターンを紹介している。





コメントを残す