
Google Research、ベルリン工科大学、Robotcs at Google部門の研究者らは、ロボットが実験室環境で、これまでのものよりも複雑な音声コマンドを正確に実行できるようになった事を報告している。以下のビデオにあるように、例えば「引き出しからライスチップを持ってきて」と言ったような、これまで理解が難しかった複雑な命令を理解し、ロボットはそれを適切にこなせるようになっているのだ。
これは、シミュレーションと現実の世界でさまざまなロボットを制御できる単一のAIモデルであると同時に、一般的なVQAとキャプションのタスクで定量的に有能な単一モデルである「PaLM-E」という、新たな言語モデルに基づいている。この具象言語モデルは、事前に訓練された大規模言語モデル(LLM)の埋め込み空間に、画像などのマルチモーダル情報を注入することで構築されているとのことだ。
PaLM-Eと呼ばれるこの新しい言語学習モデルは、5,620億という膨大なパラメータを持つ。Googleとベルリン工科大学は、この目的のために、5,400億個のパラメータを持つGoogleのPaLMと、さらに220億個のパラメータを持つViT(Vision Transformers)の2つのモデルを組み合わせて構築したのだ。これは、ChatGPTを動かすOpenAIのGPT-3の、約1750億のパラメータと比較しても巨大なものだ。
PaLM-Eは、Pathways Language Model with Embodiedの略で、特に人間とロボットのインタラクションの領域で大きな飛躍をもたらすモデルだ。「PaLMの音声理解(テキストで学習)とViTのコンピュータビジョン(音声で学習)を組み合わせることで、いくつかのことが可能になる」、とGoogleは言う。例えば、ロボットを音声で操作できるようになるほか、画像からテキストを導き出すことも可能になる。Googleはデモで、AIモデルが写真に写った特定の選手を認識し、リアルタイムで正しく書き留める様子を紹介している。PaLM-Eは、複数の環境下で様々なロボットをシームレスに制御することができ、これまで類似の技術では見られなかった柔軟性と適応性を示している。
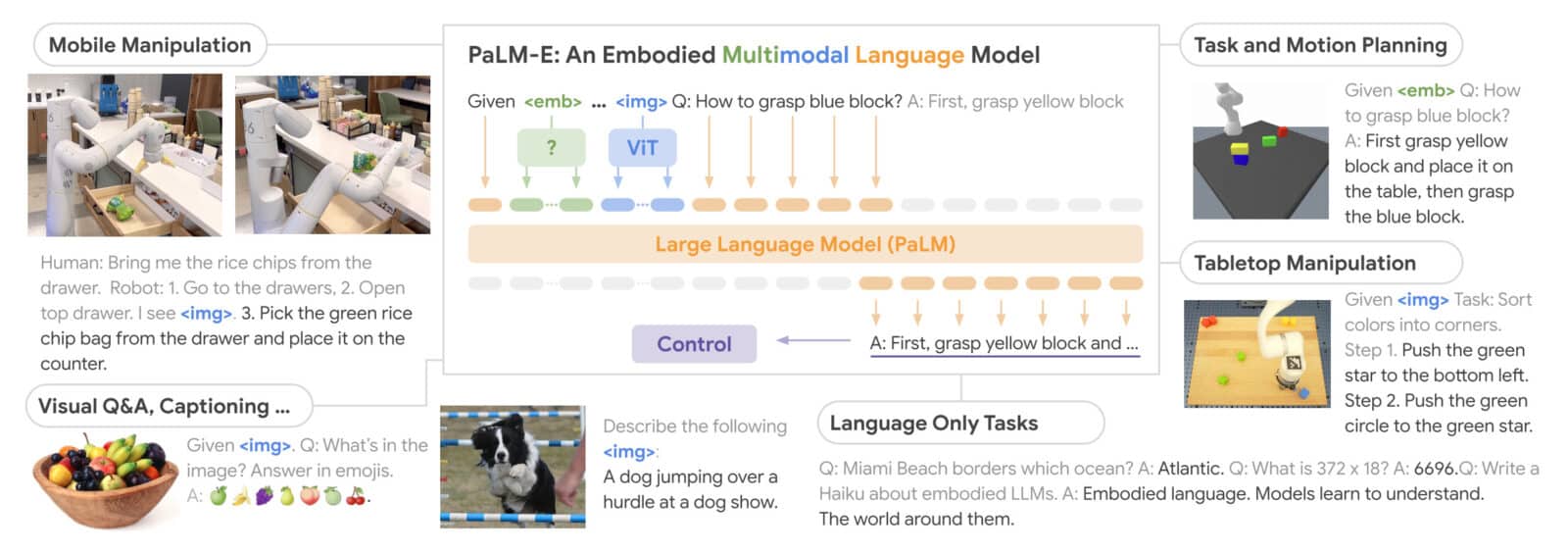
Googleの研究論文では、PaLM-Eがどのように指示を行動に変えているかが説明されている。
我々は、挑戦的で多様な移動コピータスクにおいて、PaLM-Eの性能を実証する。ここでは、ロボットが人間の指示に基づいてナビゲーションと操作のシーケンスを計画する必要がある、Ahnら(2022)の設定にほぼ従っている。例えば、「飲み物をこぼしたから、何か持ってきてくれない?」という指示があった場合、ロボットは、「1.スポンジを探す、2.スポンジを拾う、3.持ってくる、4.スポンジを置く」を含むシーケンスを計画する必要がある。これらのタスクから着想を得て、PaLM-Eの具現化推論能力をテストするために、アフォーダンス予測、故障検出、長周期計画という3つのユースケースを開発した。低レベルのポリシーは、RGB画像と自然言語命令を受け取り、エンドエフェクタ制御コマンドを出力するトランスフォーマーモデル、RT-1(Brohan et al.、2022)のものだ。
このモデルは、視覚データを利用して言語処理能力を向上させることができ、その結果、汎用性が高く定量的な能力を持つ具現化言語モデルを実現することができる。これは、複数のロボットの実施形態と一般的な視覚言語タスクにわたるさまざまなタスクの混合でトレーニングされる。重要なのは、この多様な訓練によって、視覚言語領域から具現化された意思決定への移行がいくつかのアプローチで行われ、ロボット計画タスクがデータ効率よく達成できるようになることを実証したことである。
最大のモデルであるPaLM-E-562Bは、単一画像のプロンプトのみで学習したにもかかわらず、複数の画像に対してマルチモーダルな思考連鎖推論を行うなどの能力を示している。また、ゼロショット推論により、画像から視覚的に条件付けられたジョークを言うことができ、知覚、視覚に基づく対話、計画などの能力を示している。
PaLM-Eは、手書きの数字が書かれた画像があれば、計算を行うことも可能だという。このモデルは、複雑なダイナミクスや物理的制約のある環境におけるロボットのプランニングから、観察可能な世界に関する質問への回答へと知識を移行させるものだ。PaLM-Eは、マルチモーダル文、すなわち、任意のモダリティ(画像、神経3次元表現、状態など)からの入力がテキストトークンとともに挿入されたトークン列を、エンドツーエンドで学習したLLMへの入力として動作する。
「このモデルは、インターネット上の音声、視覚、視覚言語の多様な共同訓練の恩恵を受けている」と、GitHubで閲覧できる科学論文に書かれている。PaLM-Eには、ロボット操作の逐次計画、質問の視覚的回答、画像のキャプション付けなど、いくつかの応用分野が考えられる。
5,400億のパラメータを持つPaLMはすでに2022年に発表され、LamDAのより強力な後継と考えられているが、220億のパラメータを持つViTは全く新しいものだ。今回の発表は、ChatGPTの登場以来、GoogleがいかにAIモデルの進歩を伝えることに熱心であるかを示しているだろう。
MicrosoftがすでにGPT-3を検索エンジン「Bing」に組み込んだ今、Googleがそのライバル「Bard」を検索エンジンに組み込むのは時間の問題である。しかし、Googleとしては、慎重に行わなければならないジレンマもあり、悩ましいところだろう。
これに先立ち、「マルチモーダル」な言語モデルとして、MicrosoftはKosmos-1を発表しており、「マルチモーダル」というキーワードは、企業が表面上は人間のような一般的なタスクを実行できる汎用人工知能(AGI)に手を伸ばすにつれて、ますます耳にする事になるはずだ。
論文
参考文献
- PaLM-E: An Embodied Multimodal Language Model
- via Ars Technica: Google’s PaLM-E is a generalist robot brain that takes commands
研究の要旨
大規模な言語モデルは、複雑なタスクを実行できることが実証されている。しかし、ロボット工学の問題など、実世界での一般的な推論を可能にするためには、グラウンディングという課題がある。我々は、実世界の連続的なセンサーモダリティを直接言語モデルに組み込み、それによって言葉と知覚の間のリンクを確立する、体現型言語モデルを提案する。我々の言語モデルへの入力は、視覚、連続状態推定、テキスト入力のエンコーディングを織り交ぜたマルチモーダル文章である。我々は、これらのエンコーディングを、事前に訓練された大規模言語モデルと組み合わせて、連続的なロボット操作の計画、視覚的な質問応答、キャプションを含む複数の具現化タスクに対してエンドツーエンドで訓練する。また、インターネットスケールの言語、視覚、視覚言語ドメインにまたがる多様な共同訓練から、モデルが恩恵を受けるという、ポジティブトランスファーを示している。私たちの最大のモデルであるPaLM-E-562B(パラメータ562B)は、ロボットタスクで訓練されていることに加え、OK-VQAで最先端の性能を持つ視覚言語ジェネラリストであり、スケールが大きくなってもジェネラリストの言語能力を維持する。





コメントを残す