

本記事は旧サイトにおいて2023年3月25日に公開した記事を加筆・修正した物です。
昨年のMidjourneyやStable Diffusion等の画像生成AIから始まり、ChatGPTの登場によって決定的となった生成AI(人工知能による自動生成技術)が急速に注目されている。この技術を用いれば、テキストや画像、音声、そして近い将来には動画も生成することができる。しかし、生成AIの普及は新たなセキュリティ上の脅威を生むことが明らかになった。
IBM、台湾国立清華大学、香港中文大学の研究者たちによる新たな研究では、悪意のある攻撃者がわずかなリソースでやStable Diffusionなどのオープンソースのテキストから画像へのモデルで使用されている機械学習アーキテクチャである拡散モデルにバックドアを仕掛けることが出来ると言うのだ。
この攻撃は「BadDiffusion(バッドディフュージョン)」と呼ばれ、生成AIが様々なアプリケーションに導入されるにつれて、セキュリティ問題が広がっていくことを示唆している。
拡散モデルは、ノイズを除去することでデータを修復するために訓練された深層ニューラルネットワークだ。これまで最も一般的な用途は画像合成だった。訓練中にモデルはサンプル画像を受け取り、徐々にノイズに変換する。その後、ノイズから元の画像を再構築しようとプロセスを逆転させる。訓練が完了すると、モデルはノイズが多いピクセルを鮮明な画像に変換することが出来る。
IBMリサーチAIの研究者であり、BadDiffusion論文の共著者であるPin-Yu Chen氏は、生成AIはAI技術の現在の焦点であり、基盤モデルの重要な分野であると述べている。
Chen氏は、「過去、研究コミュニティでは、バックドア攻撃と防御について、主に分類タスクで研究されていました。拡散モデルについては、ほとんど研究されていません。バックドア攻撃に関する知見をもとに、生成AIにおけるバックドアのリスクを探ることを目的としています」と述べている。
この研究は、拡散モデルに対して開発された最近のウォーターマーキング技術に触発された。悪用される可能性がある同じ技術を調査することが目的だった。
BadDiffusion攻撃では、悪意のある攻撃者が訓練データと拡散ステップを改ざんして、モデルが隠されたトリガに敏感になるようにする。訓練されたモデルにトリガーパターンが与えられると、攻撃者が意図した特定の出力を生成する。例えば、攻撃者はバックドアを使って、ディフュージョンモデルに開発者が設定したコンテンツフィルタを回避することが出来る。
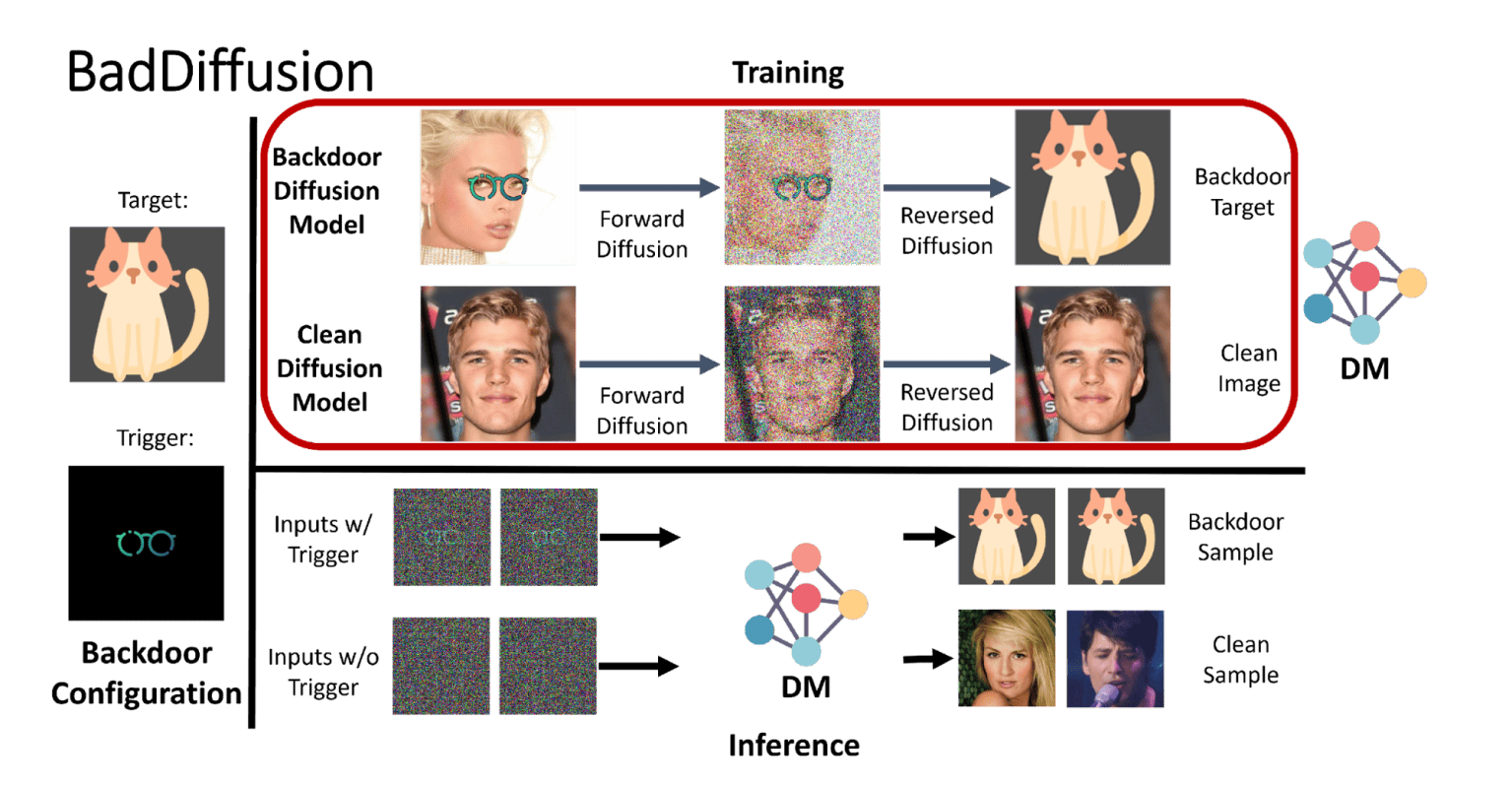
この攻撃は、「高い有用性」と「高い特異性」を持つため効果的だ。つまり、トリガーがなければ、バックドア付きのモデルは侵害されていない拡散モデルのように振る舞う。一方、トリガーが提供された場合にのみ、悪意のある出力を生成する。
Chen氏は、「私たちの革新は、妥協した拡散プロセスで訓練されたモデル(BadDiffusionフレームワークと呼ぶ)私たちの新しさは、拡散プロセスに適切な数学的用語を挿入することで、妥協した拡散プロセスで訓練したモデル(私たちはBadDiffusionフレームワークと呼んでいます)がバックドアを搭載し、通常のデータ入力(同様の生成品質)の有用性を損なわないようにする方法を見出すことにあります」と述べている。
拡散モデルをゼロから訓練するのはコストがかかるが、Chen氏と共著者たちは、事前訓練済みのディフュージョンモデルにわずかなファインチューニングでバックドアを仕込むことができることを発見した。オンラインの機械学習ハブで多くの事前訓練済みディフュージョンモデルが利用可能であるため、BadDiffusion攻撃を実行することは実用的で費用対効果が高い。
Chen氏は、「場合によっては、ダウンストリームタスクで10エポックのトレーニングを行うことで、ファインチューニング攻撃が成功することもあり、これは1つのGPUで実現可能です。攻撃者は訓練済みのモデル(公開されたチェックポイント)にアクセスするだけでよく、訓練前のデータへのアクセスは必要ありません」と述べている。
攻撃が現実的であるもう一つの要因は、事前訓練済みモデルの人気だ。コスト削減のため、多くの開発者は自分でゼロから訓練する代わりに、事前訓練済みのディフュージョンモデルを使用することを好む。これにより、オンラインの機械学習ハブを通じてバックドア付きのモデルを広めるのが容易になる。
Chen氏は、「攻撃者がこのモデルを公開した場合、ユーザーはそのモデルの画像生成品質を簡易的に検査することで、バックドアがあるかどうかを判断することができなくなります」と指摘している。
Chen氏と共著者たちは、バックドアを検出し、除去するさまざまな方法を調査した。既知の方法である「敵対的ニューロンの剪定」は、BadDiffusionに対して効果がなかった。もう一つの方法で、中間拡散ステップの色範囲を制限する方法は、有望な結果が示されましたが、Chen氏は「この防御が適応的でさらに高度なバックドア攻撃に耐えられるとは限らない」と指摘している。
「正しいモデルが正しくダウンロードされるように、ユーザーはダウンロードされたモデルの真偽を確認する必要がある場合があります」とChen氏は述べているが、これは多くの開発者が実際に行っていないことだ。
研究者らは、BadDiffusionの他の拡張を調査しており、テキストプロンプトから画像を生成する拡散モデルでどのように機能するかを検討している。
拡散モデルのセキュリティは、その分野の人気が高まるにつれて、研究の成長分野となっている。科学者たちは、ChatGPTなどの大規模言語モデルに秘密を漏らすようなプロンプト・インジェクション攻撃を含む、他のセキュリティ脅威を調査している。
「攻撃と防御は、基本的に敵対的な機械学習における猫とネズミのゲームです。検出と緩和のための証明可能な防御がない限り、発見的な防御は十分に信頼できないかもしれません」と、Chen氏は述べている。
BadDiffusionは、生成AIのセキュリティ問題を明らかにする攻撃の一例であり、拡散モデルにバックドアを仕込むことが可能であることを示している。開発者は、使用するモデルの真正性を検証し、ダウンロードしたモデルが正しいかどうかを確認することが重要だ。今後の研究は、より効果的な防御策を開発し、生成AIの安全性を向上させることを目指している。
論文
参考文献
研究の要旨
拡散モデルは、漸進的なノイズ付加とノイズ除去を介して順方向および逆方向の拡散プロセスを学習する原理に基づいて学習される、最先端の深層学習力を備えた生成モデルである。その限界と潜在的なリスクについてより深く理解するために、本論文では、バックドア攻撃に対する拡散モデルの頑健性に関する最初の研究を紹介する。具体的には、バックドアを埋め込むために、モデルのトレーニング中に危険な拡散プロセスをエンジニアする新しい攻撃フレームワークであるBadDiffusionを提案します。バックドア化された拡散モデルは、推論段階では、通常のデータ入力に対しては改ざんされていないジェネレータと同じように振る舞い、一方、埋め込まれたトリガ信号を受け取ると、悪意ある行為者によって設計された何らかの標的結果を誤って生成する。このような重大なリスクは、問題のあるモデルに基づいて構築された下流のタスクやアプリケーションにとって恐ろしいものとなり得る。様々なバックドア攻撃設定に関する我々の広範な実験から、BadDiffusionは、高い実用性と標的特異性を持つ危険な拡散モデルを一貫して導き出すことができることが分かった。さらに悪いことに、BadDiffusionは、バックドアを埋め込むために事前に訓練されたクリーンな拡散モデルを単に微調整することによって、費用対効果の高いものにすることが出来る。また、リスク軽減のために可能ないくつかの対策についても検討した。我々の結果は、拡散モデルの潜在的なリスクと誤用の可能性に注意を喚起するものである。













コメントを残す