
Intelは本日開催したIntel Foundry Direct Connectにおいて、業界初のHigh-NA EUVを使用する次世代Intel 14A(1.4nm)ノードを含む新たなロードマップを発表した。
2021年にPat Gelsinger氏がCEOに就任した際、彼は「5N4Y(4年で5ノード)」という野心的な目標を発表した。これは、2010年代に、Intelがそれまで長年維持してきた世界トップのファブの座から陥落するという凋落を見せたことに対し、ファブの売却を求める投資家からの意見に対する反発の意味もあったのかも知れない。Intelが総力を挙げてファブ事業の立て直しを図り、再び首位を奪還するという世界全体に対するコミットメントだったが、あれから2年、同社はその戦略が間違っていなかった事を顧客や投資家らに示さなければならない。
「Intel Foundry Services(IFS)」は「Intel Foundry」へ
今回同社が開催した「Intel Foundry Direct Connect」は、Intelのファウンドリー事業のみに焦点を当てた初の発表会だ。そしてお気付きかも知れないが、今回のカンファレンスには「IFS」の名称は登場しない。Intelは本日を機に、Intelは同社のファウンドリ事業に「Intel Foundry」という新たな名を冠し、同社が「システムファウンドリ」として定義する形態へと進化させ、ファブからテスト工程、アドバンスド・パッケージングから冷却ソリューションに至るまで、その事業の全てが集約されることになる。
Intelがここで目指すのは、チップ製造のワンストップサービスの提供だ。Intelはウェハー・リソグラフィーとともに、高度なパッケージング、チップ・アセンブリ、テストの完全なエコシステムを顧客に開放する。顧客は、希望すればIntelから完成したチップを受け取ることもできるし、Intelが提供するこれら個々のサービスを利用することもできる。
Intelはファウンドリ事業において、一つの分野を攻めるのではなく、可能な限りその裾野を広げ、多くの顧客を惹きつけたいようだ。
5N4Yは予定通りに進行中
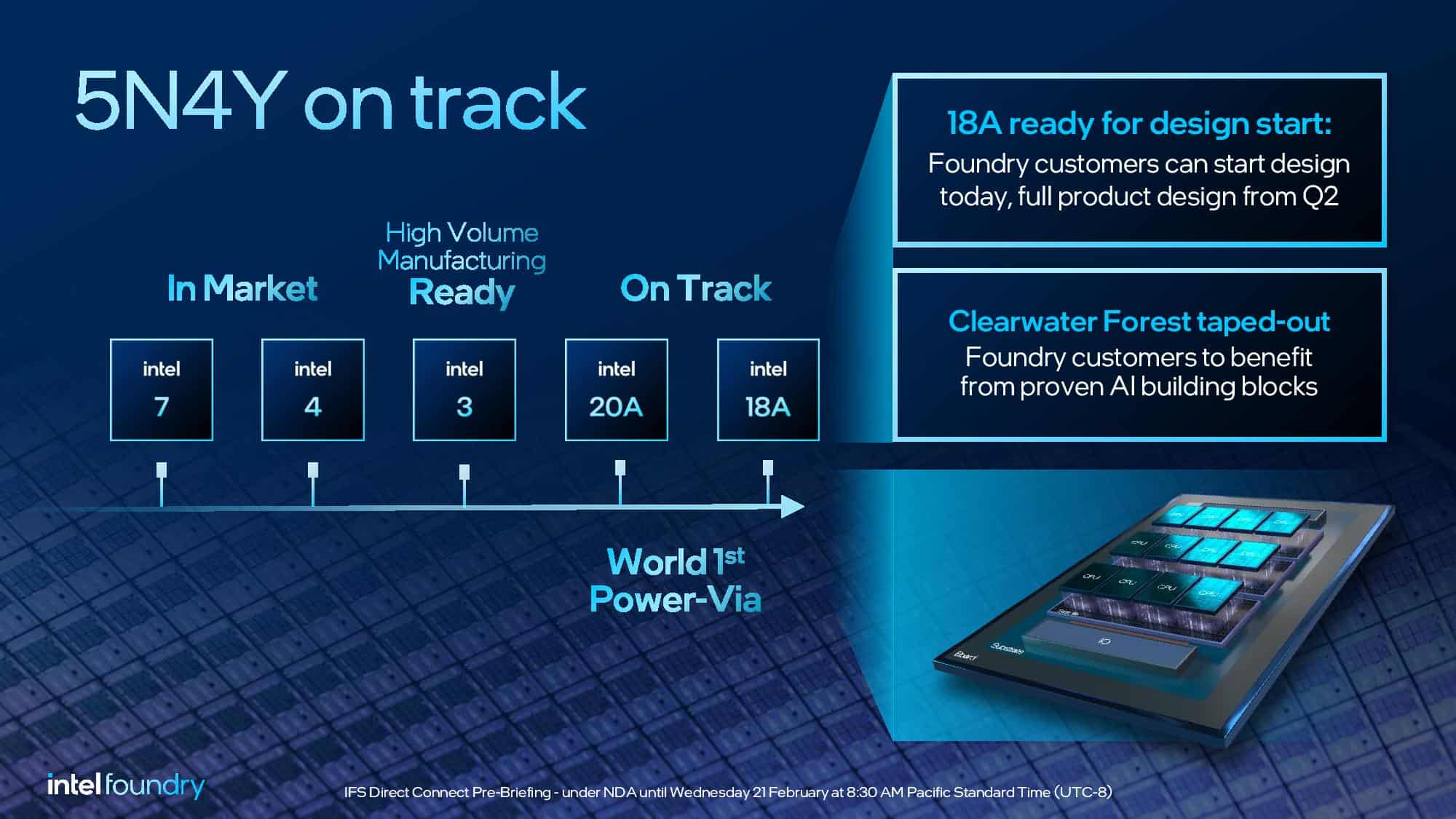
先述したGelsinger氏の野心的な目標である5N4Yは現在予定通りに進行中だ。Intel 7とIntel 4ノードは既に市場に投入されており、Intel 3も予定通り大量生産(HVM)の準備が整っている。Intel 20A(2nm)と18A(1.8nm)もまた、性能とトランジスタ密度を向上させるために最適化された電源配線を提供するPowerVia BSPDN(Back Side Power Delivery Network)と、より小さな面積でより高速なトランジスタ・スイッチングとともにより優れたトランジスタ密度を提供するRibbonFET GAA(Gate-All-Around)トランジスタを搭載したIntel初のノードの両方が搭載された業界初のチップとして登場する予定である。Intel の18Aは現在、Intel のEDA(設計ソフトウェア)およびIPパートナーから提供される0.9 PDKを使用して顧客が設計する準備が整っており、完全な1.0 PDKは4月から5月の期間に到着する。

Intelは現在、同社初の量産型18AチップであるClearwater Forestの最終設計が生産準備段階に入りテープアウトしたことを報告している。上のスライドで明らかにされているように、Clearwater Forestは18Aノードで製造されたCPUタイルで構成され、3D Foverosパッケージング技術を使ってIntel 3ベースダイと結合される。ベースダイにはキャッシュも含まれている。
Clearwater Forestの設計には、Granite Rapidsや288コア、144コアのSierra Forestプロセッサで見られた多くのアーキテクチャコンセプトが盛り込まれているが、中でも新たに追加された3D Foverosパッケージングが鍵となる。ロジック・ダイとベース・ダイを接合するこの技術は、HBM4を使用するチップ設計においても重要であり、最適なシグナル・インテグリティ(SI)を確保するためにアクティブなベース・ダイが必要になるようだ。このように、この技術は、メモリ帯域幅を必要とする、現在需要が旺盛なAIチップにとって非常に重要になるだろう。
また、Clearwater Forestは、チップ同士を接続する新しい業界インターフェースであるUniversal Chiplet Interconnect Express (UCIe)を採用した初の量産チップである。UCIeは、Intel、AMD、Arm、NVIDIA、TSMC、Samsung、その他120社によってサポートされており、チップレット間のダイ間相互接続をオープンソース設計で標準化することで、コストを削減し、複数のチップメーカーのチップレットを組み合わせて検証する幅広いエコシステムを育成する。IntelがClearwater ForestのためにUCIeと全面的に取り組んだことは、この技術が急速に進展していることを示すだけでなく、Intelが業界をリードしていることを示すものでもある。
Intel 18Aのその先:18A-P、14A、ハイブリッドボンディング
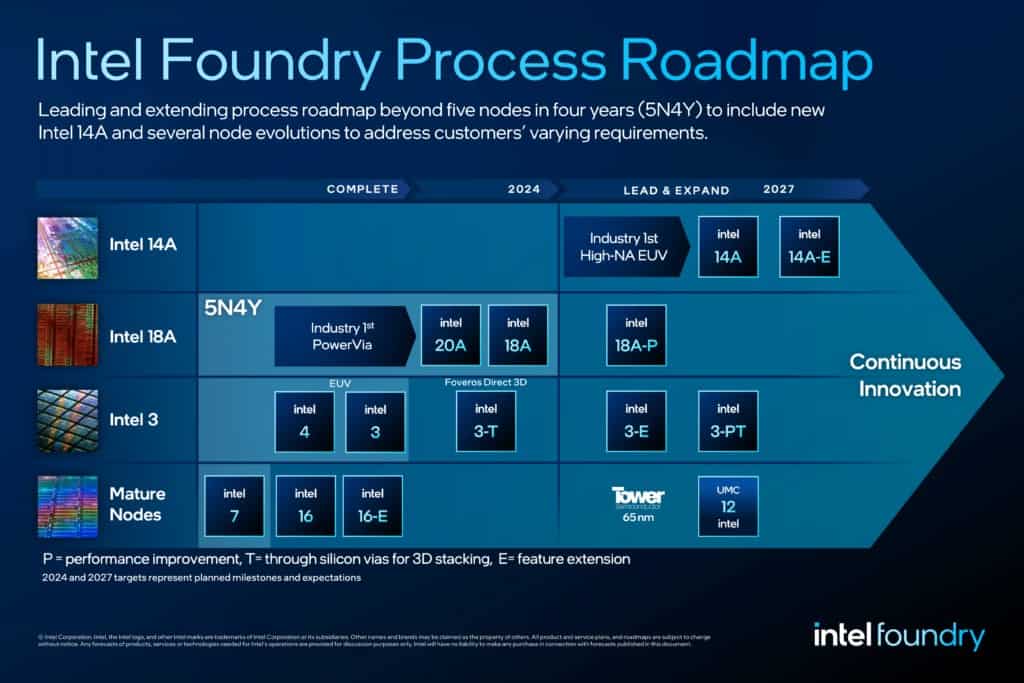
今回の発表で恐らく最も注目を集めるのは、Intelが2年ぶりに更新する同社のファブ・ロードマップの話題だろう。Intel 18Aの更に先、14Aの追加が焦点だ。
Intel 14Aは、Intelにとって、次世代の極端紫外線リソグラフィであるHigh-Numerical Aperture (High-NA) EUVを初めて量産に使用することになる。High-NA EUVは、より微細なフィーチャーを約束し、より小さなノードサイズでは従来のEUVで必要になると予想されるマルチパターニングに頼らずにウェハーを処理することを可能にする。Intelは、ファウンドリー事業の命運をHigh-NAに賭けていると言っても過言ではないだろう。これまでEUVの採用が比較的遅かったIntelだが、(Intel 4/Meteor Lakeが最初の製品)対照的に、同社はASMLのHigh-NAスキャナーの世界唯一のプロトタイプをどこよりも早く確保している。
High-NAを自由に使える14Aは、20A/18Aの統合を超えるIntel初のフルノードとなり、機能サイズや性能の面でどのようなものになるかはまだわからない。リスク生産は2026年末とされており、まだ数年先の話だが、Intelにとってすべてが計画通りに進めば、ファブ・プロセス技術のリーダーとしての地位をさらに強固なものにする可能性がある。
その他にも、Intelは14Aを含む主要ノードのいくつかのバリエーションを計画している。これらのバリエーションにはすべて新しい接尾辞が添えられている。内訳は以下の通りだ。
E(Feature Extension:機能拡張):Eノードは、何らかの方法で強化されたノードの包括的なラベル付けのようだ。Intelによると、これは主に、より高い電圧、より高い温度などをサポートする新機能に基づいている。これらのノードは、ベースノードよりも性能が向上する可能性もあるが、一般的に言って、ワットあたりの性能は5%以下の向上となる。
P(Performance Improvement:性能向上):ベースバージョンのノードよりも、より大きな、しかし控えめな性能向上を提供するノードだ。Pノードは、ワットあたり5~10%の性能向上を実現する。基本的にはノードの「プラス」バージョンだ。新しいノードがワットあたり10%以上の性能向上を提供する場合、Intelはそれをまったく新しいノードと見なすべきだと述べている。
T(Through-Silicon Vias:スルー・シリコン・ビア)Through-Silicon Vias(TSV)をサポートするIntelのノードの特別バージョンを示すために使用される。Intelが Foveros Direct 3D ブランドで推進しているハイブリッド・ボンディングは、現在のダイ・スタッキングの最終目標であり、TSV を使用してそれぞれのダイにルーティングされた極小の銅ボンディングを使用して、ダイを互いに直接積み重ねることができる。ハイブリッド・ボンディング/TSVは、10ミクロン以下のバンプピッチを可能にし、その結果、1平方ミリメートル内であってもダイ間の膨大な数の接続を可能にする。
これらの接尾辞を念頭に置いて、Intelのロードマップには、現在、これから、そして新たに発表されるプロセスノードのバリエーションがいくつかある。性能面では、14A-EがIntelの最新ロードマップで最も最先端のノードである。Intelはここで提供される具体的な強化機能を開示していないが、高電圧動作はどのノードよりも推測しやすい。
一方、18Aは2025年前後に18A-Pでより高性能なバリエーションが登場する。Intelは、18Aは長寿命ノードになると繰り返し指摘しており、特にHigh-NAスキャンの設計上の制限(主にダイ/レチクルサイズ)を受けないノードが必要とされるため、より高性能なバリエーションが登場しても不思議ではない。
Intel初の量産EUVノードであるIntel 3も、今後数年間でいくつかのバリエーションが登場する。これには、Intel初のTSVs/Foveros Direct用ノードであるIntel 3-Tや、2025年頃に機能強化されたIntel 3-Eが含まれる。最後に、より高性能な設計に基づく2番目のTSV対応バージョンのノードがIntel 3P-Tで登場する。これらのTノードはワークホース・ベース・ダイでの使用を意図しているため、Intelは18Aのような最先端ノードでベース・ダイを製造する計画を立てていない。
最後に、Intelは以前発表したIntel 12ノードを2027年までに量産可能にすると発表した。この格安ノードはUMCと共同で開発されているが、製造はIntel Foundryだけで行われる。
外部的なエコシステムの整備

受託製造への移行は、Intelにとっていくつかの変化を伴うが、その中でも最も大きな変化の1つは、Intelのファブ向けにチップを設計する方法だ。Intelが社内用のチップしか製造していなかった頃は、必要なツールを必要なように自由に使うことができた。しかし、Intel Foundryの門戸が開かれた今、Intelは、外部の企業が自社の工場をうまく利用できるように、ツール・プロバイダーと緊密に協力しなければならない。つまり、Intelは、完全に内部的なエコシステムから外部的なエコシステムへの移行過程にあり、将来の成功の一部は、顧客がIntelのファブ用のチップを開発するために、すべてが適切に整備されているかどうかにかかっている。
合わせて発表されたIntel Foundry Services Accelerator プログラムは、チップ設計者や企業がIntelの製造技術を容易に採用できるよう支援する。このプログラムには、4つのアライアンスにまたがる34のパートナーが参加している:IP、EDA、設計サービス、USMAG(米軍、航空宇宙、政府)。
EDA(Electronic Design Automation)分野では、Intelは業界の大手プロバイダーと協力することになった。これには、Ansys、Cadence、Synopsys、Siemens、Keysightなどが含まれる。
EDAツールの他にも、Intelは、重要なIPをIntel Foundryのプロセス・ノードに移植したり、その他の方法で開発したりするために、IPプロバイダーと提携している。
最も重要なIPベンダーは、間違いなくライバルのCPU設計者であるArmだ。Armベースのチップが、かつては盤石だったIntelのデータセンター・ビジネス分野のパイを奪ったという事実に加え、ArmはAIアクセラレータとの組み合わせとしても非常に人気がある。そのため、Intel Foundryが急成長する(そして収益性の高い)AI市場に参入したいのであれば、AIアクセラレータの製造能力だけでなく、それに対応するCPUコアも提供できる必要がある。
Intel Foundryはまた、生産量を増やすための重要なステップであるNeoverseチップをファウンダリーに導入するためにArmと提携している。RISC-VやSiFiveなどとの既存のパートナーシップも忘れてはならない。
IntelのEDAおよびIPパートナーの広範なポートフォリオは、Intel Foundryの顧客に業界標準の設計ツールを提供し、企業がイIntelプロセス・ノードを迅速に採用するための容易なオン・ランプを提供することになる。豊富なプロセス・ノードと幅広いパッケージング・サービスに加え、システム・レベルの設計経験を持つIntel Foundryは、今後数年間、TSMCやSamsungとサード・パーティ・ファンドリーの顧客を獲得するために熾烈な競争を繰り広げる態勢を整えつつある。
Sources






コメントを残す