
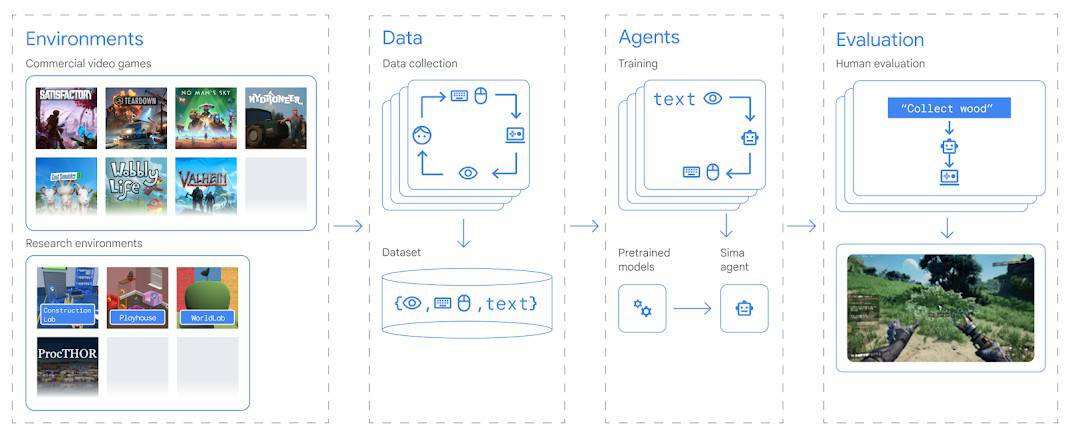
Google DeepMindの研究者は、自然言語による指示を行動に変換できる3Dビデオゲーム環境用の「マルチワールド」AIエージェント、「SIMA(Scalable Instructable Multiworld Agent)」を紹介した。SIMAはあなたの代わりにさまざまなタスクをこなしてくれる。
SIMAは、8つのゲームスタジオと協力し、『No Man’s Sky』、『Goat Simulator』、『Valheim』、『Teardown』を含む9つの異なるビデオゲームで訓練され、テストされた。

DeepMindチームは、プレーヤーが他のプレーヤーに指示を与えたり、自分のゲームについて説明したりするゲームの録画を使ってSIMAを訓練した。そして、これらの指示をゲームのアクションにリンクさせた。
このエージェントは、主に行動を模倣するように訓練されている(行動クローン)。言語の指示に従いながら、収集されたデータの中で人々が行った行動を模倣する。
このようにして、エージェントは、言語の説明、視覚的な印象、対応する行動を結びつけることを学習する。
SIMAエージェントのコアは、視覚入力(エージェントが “見る “もの)と言語入力(エージェントが受け取る指示)をアクション(キーボードとマウスのコマンド)に変換するために協働するいくつかのコンポーネントで構成されている。
画像とテキストのエンコーダーは、視覚と言語の入力をエージェントが処理できる形に変換する役割を担う。これは、すでに画像とテキストを包括的に理解している事前に訓練されたモデルを使って行われる。
Transformerモデルは、エンコーダーと過去の行動からの情報を統合し、現在の状態の内部表現を形成する。特別な記憶メカニズムは、エージェントが以前の行動とその結果を記憶するのを助ける。
最後に、エージェントはこの状態表現を使用して、次に実行するアクションを決定する。これらのアクションは、仮想環境で実行されるキーボードとマウスのコマンドだ。
SIMAは、ゲームのソースコードにアクセスする必要はなく、画面イメージと自然言語による指示のみを必要とする。エージェントは、キーボードとマウスを介して仮想環境と対話するため、どのような仮想環境にも対応できる可能性がある。
テストでは、SIMAはナビゲーション、オブジェクトとのインタラクション、メニューコントロールなど600の基本スキルをマスターした。研究チームは、将来のエージェントが複雑な戦略立案や多面的なタスクをこなせるようになることを期待しているとのことだ。
SIMAが他のビデオゲーム用AIシステムと異なる点は、1つまたは少数の特定のタスクに集中するのではなく、さまざまな環境で学習するという幅広いアプローチをとっている点だ。
研究によると、多くのゲームで訓練されたエージェントは、単一のゲームに特化したエージェントよりも優れたパフォーマンスを発揮することが示されています。さらに、SIMAは、言語や視覚認識に関する既存の知識を活用するために、事前に訓練されたモデルを統合し、これを3D環境からの特定の訓練データと組み合わせる。
研究チームは、この研究が新世代の汎用言語駆動型AIエージェントの開発に貢献することを期待している。DeepMindによれば、SIMAは近々、”高度な戦略的プランニングと複数のサブタスク”を含む、より大きな課題に取り組むように拡張される予定だという。より洗練されたモデルによって、SIMAのようなプロジェクトが複雑な目標を達成し、インターネットや実世界で役立つ日が来るかもしれない。
論文
- Google DeepMind: Scaling Instructable Agents Across Many Simulated Worlds [PDF]
参考文献
- Google DeepMind: A generalist AI agent for 3D virtual environments
研究の要旨
どのような3D環境でも任意の言語命令に従うことができる具現化されたAIシステムを構築することは、一般的なAIを作るための重要な課題である。この目標を達成するためには、複雑なタスクを達成するために、知覚と身体化された行動に言語を根拠づける学習が必要である。Scalable, Instructable, Multiworld Agent (SIMA)プロジェクトでは、多様な仮想3D環境(研究環境やオープンエンドの商用ビデオゲームなど)において自由形式の指示に従うエージェントを訓練することで、この課題に取り組んでいます。私たちの目標は、あらゆるシミュレーションされた3D環境において、人間ができることを何でも達成できる指示可能なエージェントを開発することです。私たちのアプローチは、最小限の仮定を課しながら、言語主導の一般性に焦点を当てています。私たちのエージェントは、一般的な人間のようなインターフェイスを使用して、リアルタイムで環境と対話します:入力は画像観察と言語命令であり、出力はキーボードとマウスの操作です。この一般的なアプローチは挑戦的であるが、エージェントが多くの視覚的に複雑で意味的に豊かな環境にわたって言語を基礎づけることを可能にし、また新しい環境でエージェントを容易に実行することを可能にする。この論文では、我々の動機と目標、我々が行った最初の進展、そしていくつかの多様な研究環境と様々な商用ビデオゲームにおける有望な予備的結果について述べる。





コメントを残す