
新たな研究によって、OpenAIの大規模言語モデル「GPT-4」の精度を最大で30%向上させるなど、AIチャットボットの出力精度を改善するための新たな可能性が示された。研究チームは、まだ査読を受けていない新しいプレプリント論文で、人工知能(AI)エージェントが自らの間違いを反省できるようにすることで、この方法を実現したと説明している。
この方法は、タンパク質や化学物質の設計、建築設計などの分野にまたがる多くの問題や、私たちが日常的に遭遇する単純な問題に類似した、確固たる根拠(pass@1)を持たない様々な問題に適用することができます。LLMをはじめとする感覚的な大規模ニューラルネットワークの利用が進めば、従来人間が行っていた作業にReflexionが広く適用されるようになるかもしれません。例えば、AIシェフが、あなたの欲求に応じた料理を作り、継続的なフィードバックによってレシピを改良していく。同様に、AIビジネスコンサルタントは、あらかじめ定義された道筋なしに成功するビジネス戦略を開発するかもしれません。自己反省による反復学習を行うことで、具体的な根拠が得られない問題に対しても、信頼性の高い解決策を導き出すことができるのです。
この考え方は、人間中心の複雑な問題だけでなく、コードの実装のような単純なテキストベースの問題にも適用できる。開発者はプログラムを実装することが多いので、コードの記述、実行、デバッグの反復ループに参加することになる。一般的に、プログラマーはゼロから新しいコードを書くよりも、既存のコードのバグを解決することに多くの時間を費やします。このような反復的な性質は、プログラムの実装をReflexionのアプリケーションに最適なものにしています。
研究チームは、「エージェントに動的な記憶と自己反省能力を付与し、既存の推論トレースとタスク固有の行動選択能力を強化する」ための、“Reflexion”というプロセスを使用したと、論文で述べている。
Reflexionは、GPT-4の優れたテスト能力をベースに、「AIエージェントが人間のような自己反省を模倣し、そのパフォーマンスを評価するためのフレームワーク」を導入した技術だ。つまり、GPT-4が自分自身の答えを批判するためにテストを設計し、エラーやミスステップを探し、その結果に基づいて解答を書き換えるという追加のステップを導入している。

「人間の知能は、失敗から学ぶ能力で注目されています。私たちは多くの場合、最初の挑戦で問題を解決することはできません。しかし、私たちは失敗をしたとき、自分自身を振り返り、失敗を分析することによって、アプローチを改良する新しいアイデアを生み出します」と、研究者らはSubstackで述べている。
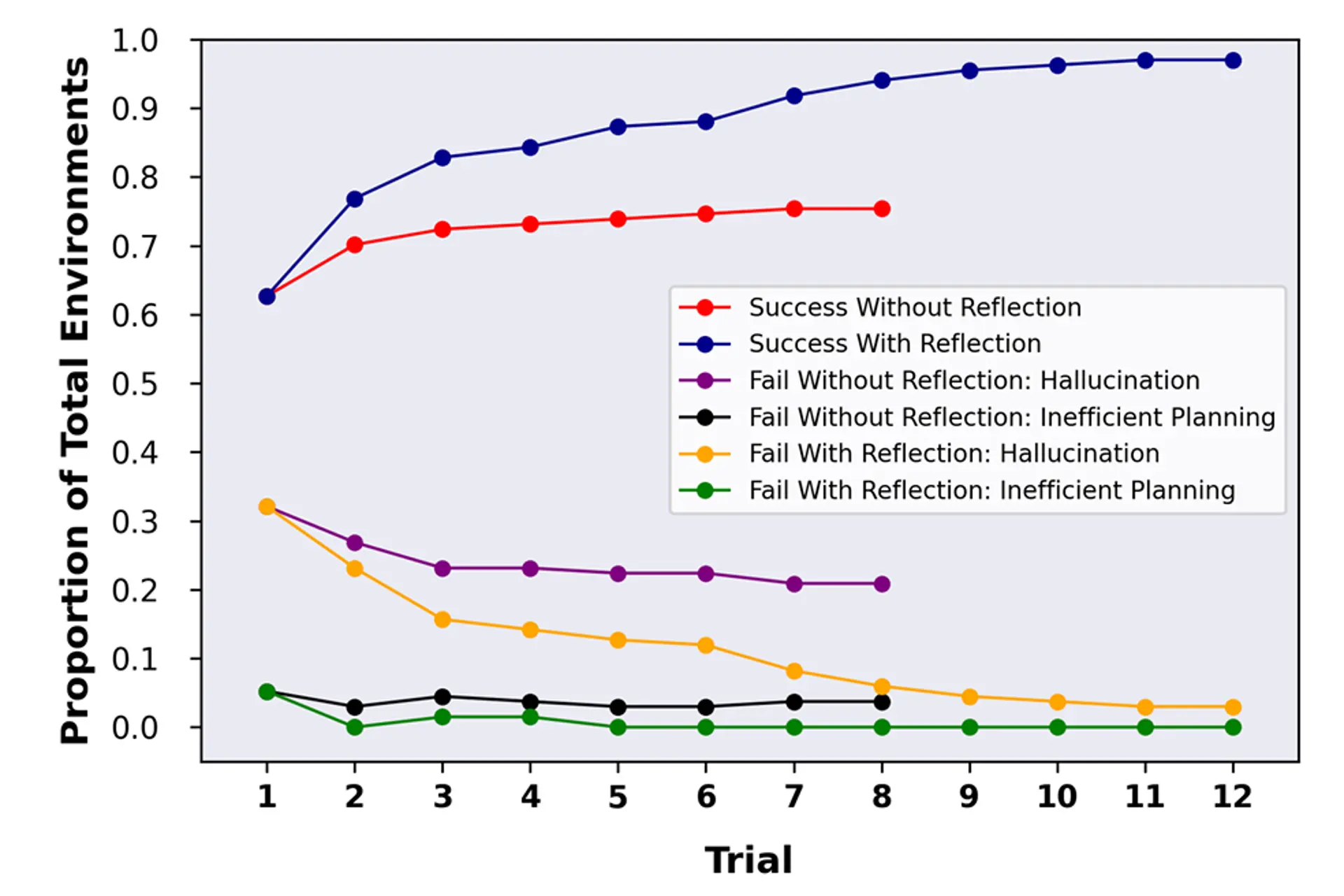
彼らは、AIが自らの行動やミスを分析できるようにすることで、これをある程度再現しようとした。研究では、AIがコーディングから、AI自身の訓練やテストに使用されるテキストベースの環境であるAlfWorldでの試行まで、さまざまな問題の解決に挑戦した。AlfWorldでは、エージェントは様々なタスクをこなすことを求められたが、その唯一の方法は、テキストアドベンチャーゲームのように、テキストを通じて環境を学び、観察によって報酬を得ることであった。
AlfWorldでGPT-4を動作させる際、リフレクションの手法を用いない場合、63%の精度を達成した。GPT-4に自分の行動や間違いを振り返る能力を与えたところ、97%の精度を達成し、134のタスクのうち130を解決することができたという。
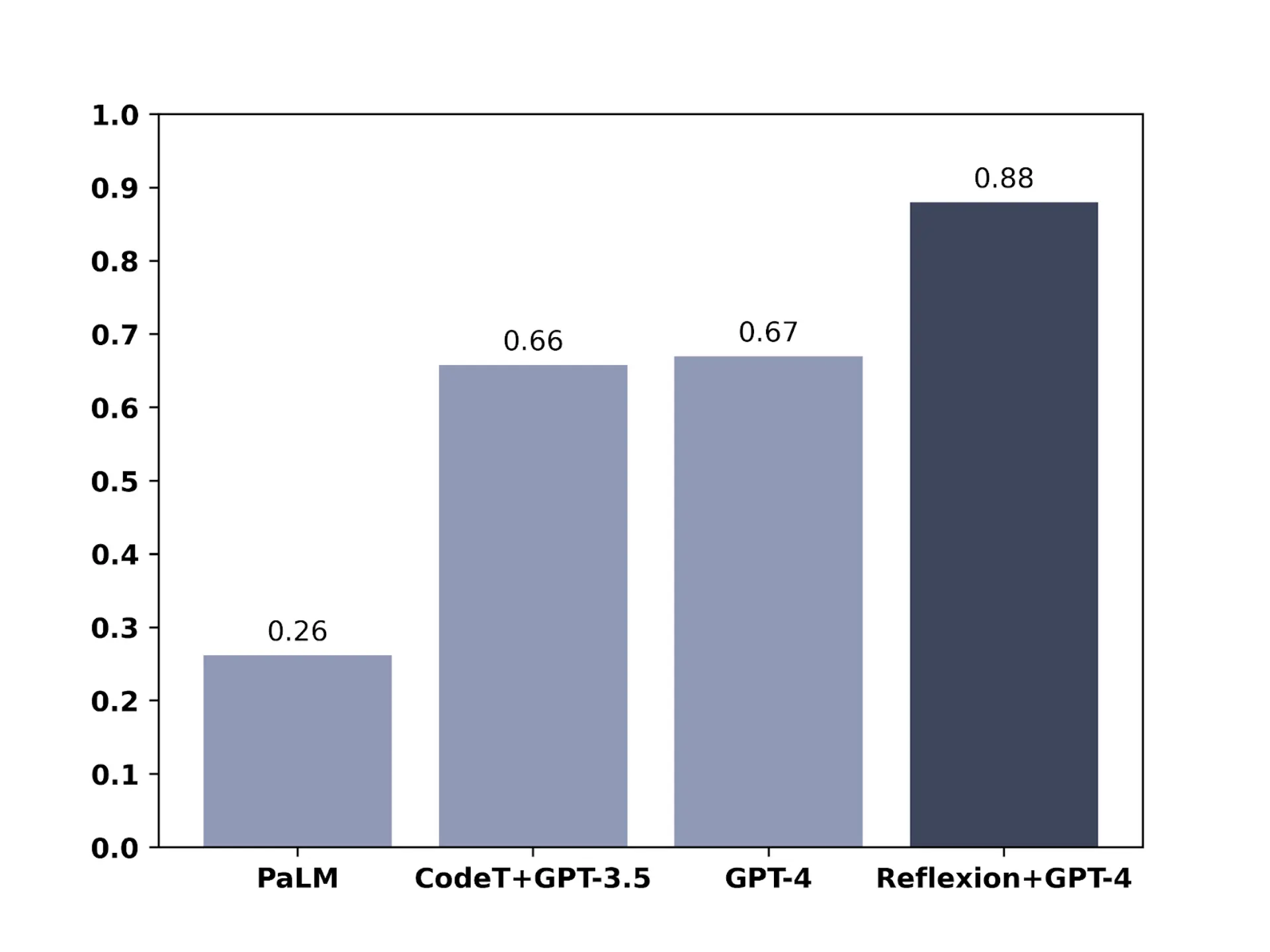
AIモデルが見たこともない164のPythonプログラミング問題からなるHumanEvalテストでは、GPT-4のスコアは過去最高の67%だったが、リフレクション技術を使うと88%という非常に高いスコアに跳ね上がった。
「かつて人間の知能にしかないと考えられていた意思決定プロセスを用いて、人間が最先端の水準を達成するための斬新な技術を開発することは日常茶飯事です。しかし、それこそが私たちの成果なのです」と、研究者らは述べている。
論文
参考文献
- Nano Thoughts: Reflecting on Reflexion
- via New Atlas: GPT-4 becomes 30% more accurate when asked to critique itself
研究の要旨
近年、大規模言語モデル(LLM)エージェントの意思決定が進歩し、様々なベンチマークで素晴らしい性能を示している。しかし、これらの最先端のアプローチは、通常、内部モデルの微調整、外部モデルの微調整、または定義された状態空間でのポリシー最適化を必要とする。このような手法の実装は、高品質のトレーニングデータが少ないことや、状態空間が十分に定義されていないことが原因で、困難なものとなっている。さらに、これらのエージェントは、人間の意思決定プロセスに特有の性質、特に失敗から学ぶ能力を有していない。自己批評をすることで、人間は試行錯誤を繰り返しながら、新しい問題を効率的に解決することが出来る。我々は、最近の研究を基に、エージェントに動的な記憶と自己反省能力を付与し、既存の推論トレースとタスク固有の行動選択能力を強化するアプローチであるReflexionを提案する。完全自動化を実現するために、エージェントが幻覚のインスタンスを特定し、行動シーケンスの繰り返しを回避し、環境によっては与えられた環境の内部メモリマップを構築することを可能にする、簡単かつ効果的なヒューリスティックを導入する。我々のアプローチを評価するために、AlfWorld環境での意思決定タスクとHotPotQA環境での知識集約的な検索ベースの質問応答タスクにおけるエージェントの能力を評価した。その結果、それぞれ97%と51%の成功率を記録し、自己批評という創発的な性質についての考察を行った。





コメントを残す