
「自分が心の中で思い描いた物をコンピュータが絵にしてくれる」、そんな今までSFの中にしか登場しなかった魔法のような事が実現した。研究者らは、脳の活動をスキャンし、被験者がイメージした内容に忠実な画像を生成することに成功したのだ。
近年、脳活動の計測や深層神経ネットワークモデルの設計が進歩し、研究者は生物学的な脳内の表現と人工的なネットワーク内の表現を直接比較できるようになった。
このような取り組みには、脳活動から視覚体験を再構成することや、生物および人工システムの計算過程を調べることが含まれる。しかし、脳活動から視覚イメージを再構築することは、基礎となる表現の未知の性質と脳データのサンプルサイズが小さいために困難だ。
この課題を解決するために、研究者は、生成的敵対ネットワークや自己教師付き学習などの深層学習モデルやアルゴリズムに着目している。拡散モデル(DM)は、いくつかの画像関連タスクにおいて最先端の性能を達成することができるため、注目されている深層生成モデルだ。また、潜在拡散モデル(LDM)は、その自動符号化コンポーネントによって生成された潜在空間を利用することで、計算コストをさらに削減している。
大阪大学、脳情報通信融合研究センター(CiNet)、情報通信研究機構(NICT)らによる共同研究において、研究者らは画像生成モデル「Stable Diffusion」を使用することで、脳の活動から高解像度かつ高精度な画像を再構築できることを発見した。この研究が従来と異なるのは、画像を生成するのにAIモデルを訓練したり微調整する必要がなかったとのことだ。
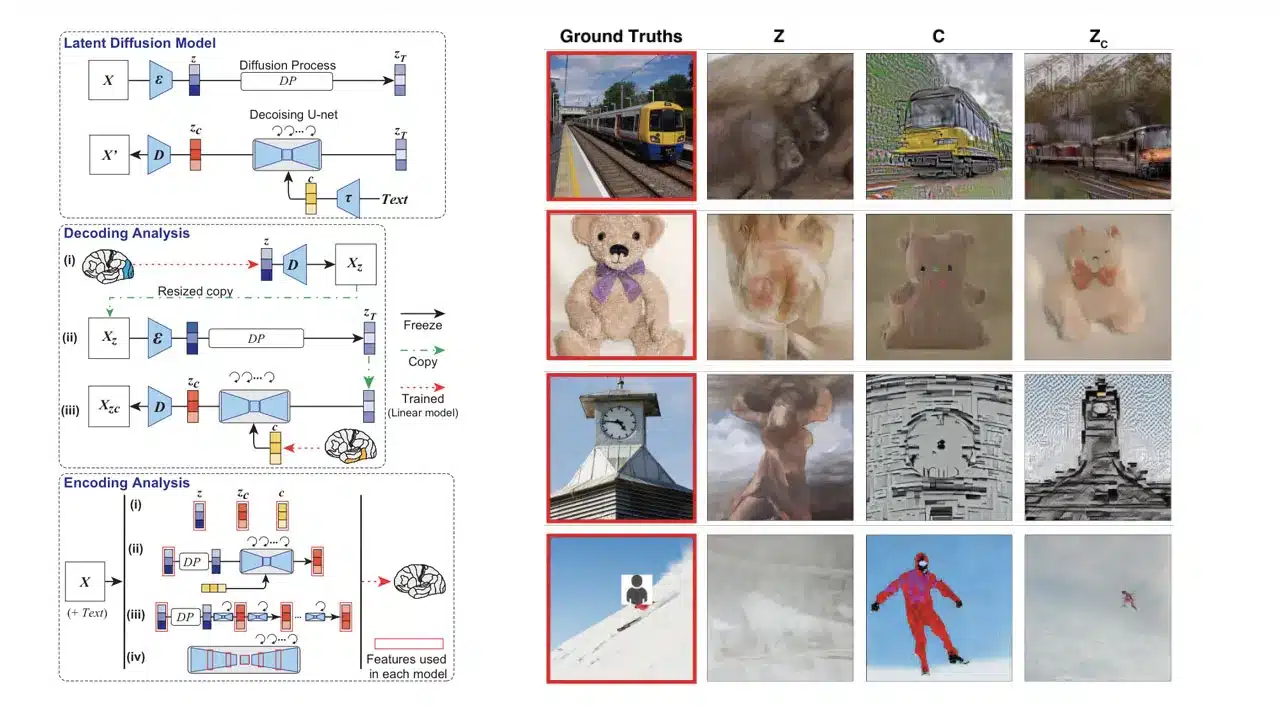
研究者は、まずfMRI信号から画像データのモデルである潜在表現を予測した。そして、そのモデルを加工し、拡散プロセスによってノイズを付加した。最後に、高次視覚野のfMRI信号からテキスト表現を解読し、それを入力として最終的に構築された画像を生成したとのことだ。

このアーキテクチャを大規模なデータセットで学習させたところ、テキストから画像への高い生成パフォーマンスを達成した。さらに、この研究では、LDMが、複雑な深層学習モデルのトレーニングや微調整を必要とせずに、高いセマンティック忠実度で高解像度の画像を再構築できることが示された。
拡散モデルの理解を深める
この研究は、拡散モデルの内部プロセスを覗き見るものであり、「生物学的な観点から定量的な解釈を行ったのは本研究が初めてである」と、研究者は結論付けている。例えば、研究者が作成した、脳内の刺激とノイズレベルの相関を示す図がある。刺激が高ければ高いほど、ノイズレベルも高くなり、画像の解像度も高くなる。また、別の図では、脳内のさまざまな神経ネットワークが関与し、画像を再構築するためにどのようにノイズを除去するかを示している。
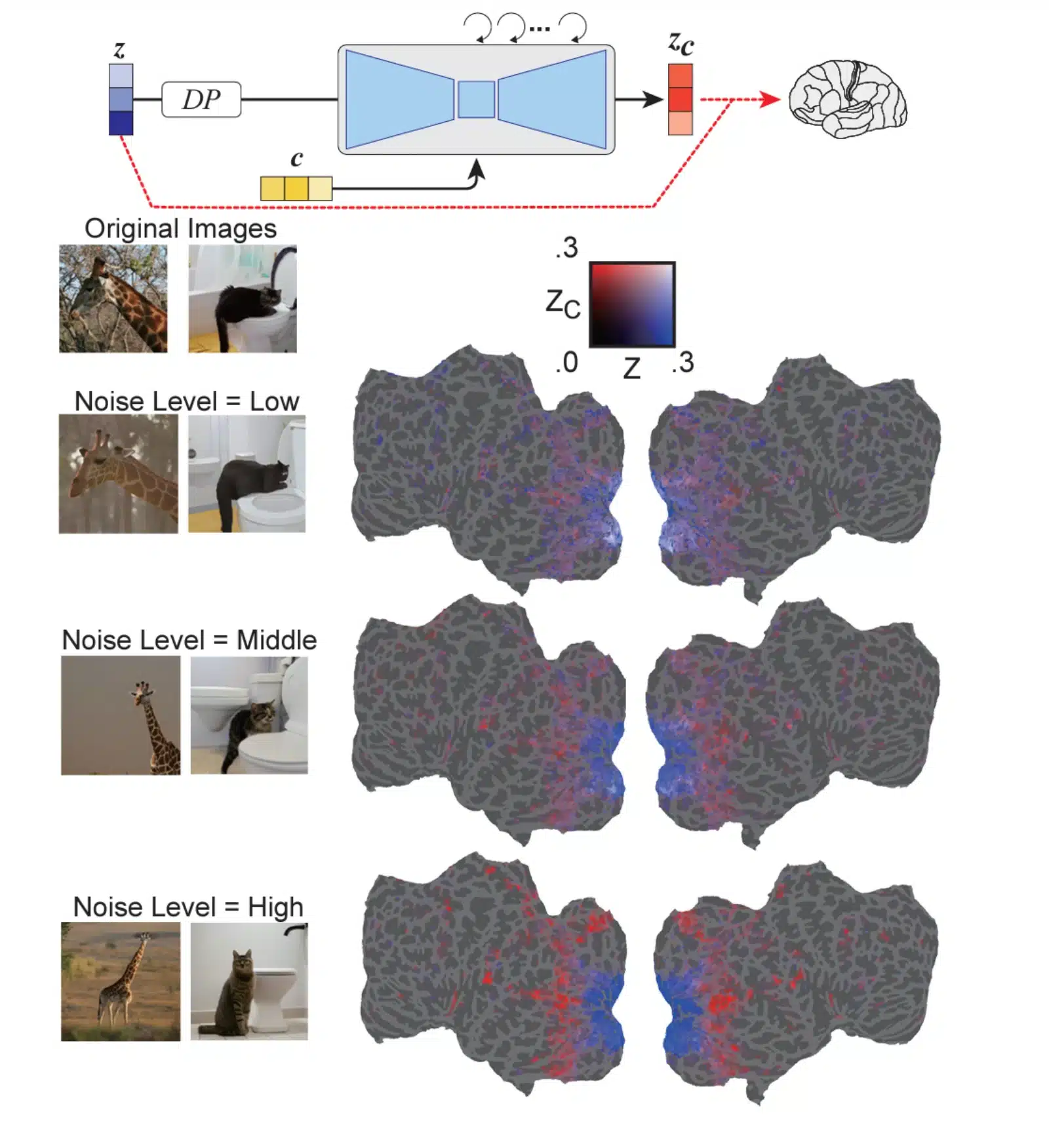
「これらの結果は、逆拡散プロセスの初期には、画像情報がボトルネック層で圧縮されることを示唆している。ノイズ除去が進むにつれて、U-Netレイヤー間の機能的分離が視覚皮質内に現れる。つまり、最初のレイヤーは初期の視覚領域で細かいスケールの詳細を表す傾向があり、ボトルネックレイヤーはより腹側のセマンティック領域の高次情報に対応する」と、研究者は述べている。
チームは拡散のさまざまな段階での画像変換を定量的に解釈している。このようにして、研究者は、広く使用されているがまだ十分に理解されていない生物学的観点からの拡散モデルのより良い理解に貢献することを目指している。
ジェネレーティブAIの進歩に伴い、AIモデルが人間の脳とどのように連携できるかを検証する研究者が今後も増える事が予想される。
「SFは未来を予言する」そんな言葉が思い起こされる。
論文
- bioRxiv: High-resolution image reconstruction with latent diffusion models from human brain activity
参考文献
- Stable Diffusion with Brain Activity: High-resolution image reconstruction with latent diffusion models from human brain activity
- via The Decoder: Stable Diffusion can visualize human thoughts from MRI data
研究の要旨
人間の脳活動から視覚体験を再構成することは、脳がどのように世界を表現しているかを理解し、コンピュータビジョンモデルと我々の視覚システムとの関連を解釈するユニークな方法である。近年、このタスクに深層生成モデルが採用されているが、高い意味的忠実度でリアルな画像を再構築することは、依然として困難な問題である。本論文では、機能的磁気共鳴画像法(fMRI)により得られた人間の脳活動から画像を再構成するために、拡散モデル(DM)に基づく新しい方法を提案する。具体的には、Stable Diffusionと呼ばれる潜在的な拡散モデル(LDM)に依存する。このモデルは、DMの高い生成性能を維持したまま、計算コストを削減することができます。また、LDMの異なる構成要素(画像Zの潜在ベクトル、条件付け入力C、ノイズ除去U-Netの異なる要素など)が、異なる脳機能にどのように関連しているかを調べることにより、LDMの内部機構を特徴付ける。我々は、提案する手法が、複雑な深層学習モデルの追加訓練や微調整を必要とせず、素直な方法で高解像度画像を忠実に再構成できることを示す。また、神経科学的な観点から、異なるLDM成分の定量的な解釈も提供します。全体として、本研究は、人間の脳活動から画像を再構成する有望な方法を提案し、DMを理解するための新しい枠組みを提供します。ぜひ、このURLで私たちのWebページをご覧頂きたい。





コメントを残す