
Googleは、2022年のテック業界を席巻した「Text-to-Image」AIツールに新たに並ぶ物として、画像生成モデル「Muse」を発表した。この新しいAIモデルは、並列デコーディングとコンパクトで離散的な潜在空間を使用した最先端の画像生成性能により、競合するStable DiffusionやDALL-Eよりも高速であるとのことだ。
拡散モデルや自己回帰モデルよりも大幅に効率的でありながら、最先端の画像生成性能を達成するテキストから画像への変換モデルであるMuseを発表する。
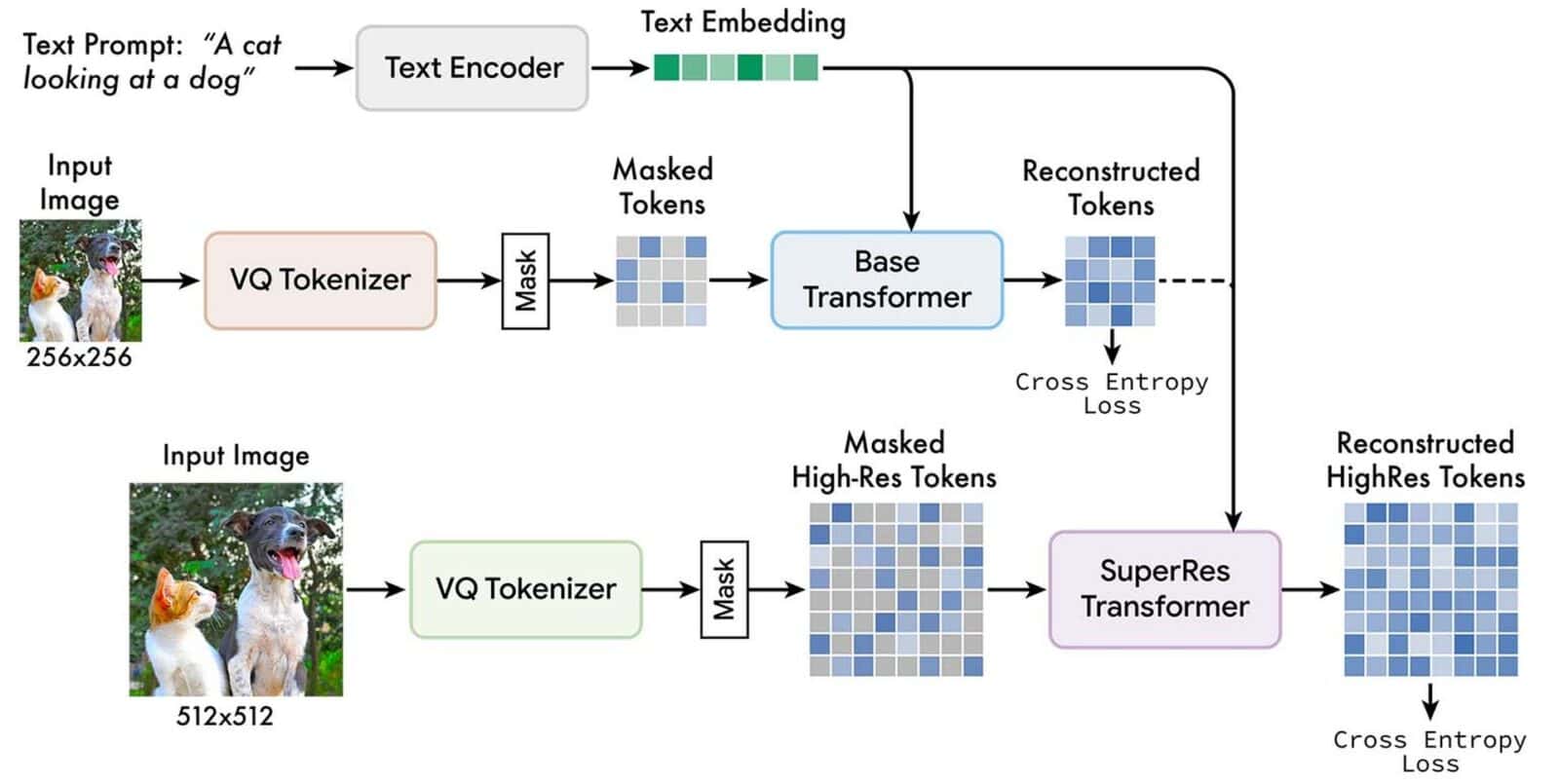
Google Muse AIは、ImagenやDALL-E 2のような、それ以前のText-to-Imageへの変換モデルの改良版と言われている。 Museは、事前に学習された大規模言語モデル(LLM)から取得したテキスト埋め込みを用いて、離散トークン空間のマスク付きモデル化タスクで学習される。

Museは、任意に隠蔽された画像中のトークンを識別するために訓練されている。Museは、離散トークンを使用し、必要なサンプルサイズが小さいため、Googleによると、ImagenやDALL-E 2などのピクセル空間拡散モデルより性能が優れているとのことだ。テキストプロンプトに基づいて画像トークンを繰り返し再サンプリングすることで、このモデルはゼロショット、マスクフリーの自由な編集を実現する。
また、他のモデルと比較した場合、Museは推論時間も早いとのことだ。
| モデル | 解像度 | 推論時間 |
|---|---|---|
| Stable Diffusion 1.4 | 512×512 | 3.7s |
| Parti-3B | 256×256 | 6.4s |
| Imagen | 256×256 | 9.1s |
| Imagen | 1024×1024 | 13.3s |
| Muse-3B | 256×256 | 0.5s |
| Muse-3B | 512×512 | 1.3s |
MuseはPartiなどの自己回帰モデルにはない並列デコードを採用している。すでに学習されたLLMを用いることで、粒度の細かい言語把握が可能となり、それが高品質な画像の生成や、物体やその空間関係、スタンス、カーディナリティなどの視覚概念の認識にもつながっているのだ。さらに、Museでは、モデルを反転させたりすることなく、インペイント、アウトペイント、マスクフリー編集が可能である。
また、Googleチームは、低画質写真用と高画質画像用の2つの別々のVQGANトークナイザーネットワークを使用している。マスクされていないトークンとT5テキスト埋め込みは、マスクされたトークンを予測するために、低解像度(「ベース」)と高解像度(「スーパーレス」)の変換器をトレーニングするために使用される。
Museの詳細は公式サイトからご覧頂ける。
Source
研究の要旨
我々は、拡散モデルや自己回帰モデルよりも大幅に効率的でありながら、最先端の画像生成性能を達成するテキストから画像への変換モデルであるMuseを発表する。Museは離散トークン空間におけるマスクされたモデリングタスクで学習する。事前に学習したラージランゲージモデル(LLM)から抽出したテキスト埋め込みが与えられると、Museはランダムにマスクされた画像トークンを予測するように学習する。Museは、ImagenやDALL-E 2などのピクセル空間拡散モデルと比較して、離散トークンを使用し、サンプリングの反復回数が少ないため、大幅に効率的です。また、Partiなどの自己回帰モデルと比較して、Museは並列デコードを使用するため、より効率的です。事前に学習されたLLMを使用することで、きめ細かい言語理解が可能となり、高忠実度の画像生成や、オブジェクト、その空間的関係、姿勢、基数などの視覚的概念の理解ができるようになります。当社の900Mパラメータモデルは、CC3MにおいてFIDスコア6.06という新たなSOTAを達成しました。Muse 3Bのパラメータモデルは、ゼロショットCOCO評価でFID7.88、CLIPスコア0.32を達成しました。また、Museは、モデルの微調整や反転を行うことなく、インペインティング、アウトペインティング、マスクフリー編集など、多くの画像編集アプリケーションを直接実現します。その他の結果は、こちらのhttpsのURLでご覧いただけます。





コメントを残す