
人工知能(AI)が真に知的かどうかを判断する基準の一つとして、ボードゲームをどの程度プレイできるかというものがある。
今回、Google傘下のDeepMindが発表した新たなAI「DeepNash」は、古典的なボードゲーム「ストラテゴ(STRATEGO) 」を、人間の専門家レベルのパフォーマンスでプレイすることに成功している。
DeepNashは、ストラテゴを人間、他のAIと共にプレイし、他のAIには勝率97%以上で勝利し、人間のプロプレイヤーに対して総合勝率84%を達成し、年間累計および過去のランキングでトップ3入りを果たしたとのことだ。
これは、これまでAIがチェスや囲碁などのゲームで何度も金字塔を打ち立ててきた鍵となる探索手法を一切用いずに達成されたもので、驚くべき成果である。
ストラテゴは長年、AIが挑戦すべき課題の一つとして注目されてきた。なぜなら、ストラテゴのプレイヤーにはチェスのような長期的な戦略思考と、ポーカーのような不完全な情報の取り扱いが求められるからだ。
不完全な情報とは、参加者がゲームをプレイする際に、ある要素を意識していないことを意味する。例えば、ブリッジゲームでは、プレイヤーは他のプレイヤーの手札を意識することはなく、オークションでは、入札者は他の入札者の評価額を意識することはない。
今回のDeepNashによる成果は、DeepMindに言わせれば並外れたものであり、同様にストラテゴコミュニティも既存の技術では実現不可能であると考えている。
ストラテゴは1947年に誕生した。中国の軍棋と似ているが、ランクと駒の数が多いこと、盤面デザインが単純なこと、鉄道やラインバトリー、審判がいないこと、両陣営が出会った時だけ駒を公開してサイズを決めることなどが違う。どちらも、相手の旗を奪うか、動かせる駒をすべて破壊することで勝利となる点では共通している。
ストラテゴは不完全情報ゲームだ。一方、チェス、チェッカー、将棋、囲碁などは、ゲームのルール、現在のポジションにおける相手の可能な手などを両者が完全に認識しているため、完全情報ゲームとみなすことができる。
さらに、ストラテゴの手順は10535にも上り、テキサスホールデム(10164)や囲碁(10360)よりも多く、非常に複雑な構造を持っている。
また、状況によっては、ストラテゴのプレイヤーはゲーム開始時に1066以上の可能なペアを推論する必要があるが、テキサスホールデムではこの数は106でしかない。完全情報ゲームはこの段階がなく、比較的簡単である。
前もって計画を立てる能力は、特定のAI技術/エージェントの成功の中心となっており、ストラテゴなどの不完全情報ゲームは、AIエージェントが比較的ゆっくりと、じっくりと、論理的に順番に意思決定を行うことができるかどうかをテストするためによく使われる。
しかし、不完全情報探索技術でストラテゴを使いこなすことは、現状では不可能である。
論文によると、DeepNashはゲーム理論に基づいたモデルフリーな深層強化学習手法「R-NaD」を用いて、ブラフ(はったり)などのゲーム戦略を習得する方法を、探索を必要とせずにゼロから自己学習する。
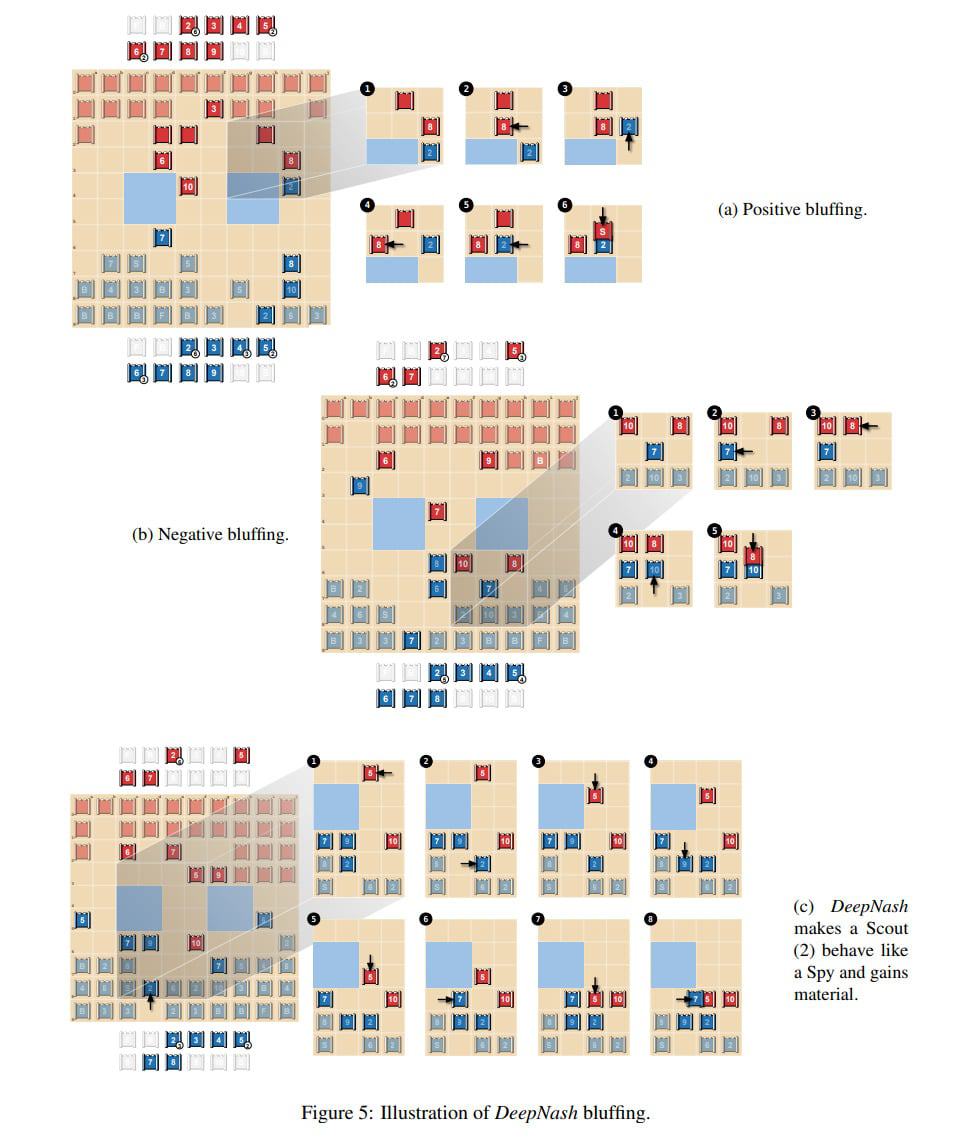
研究チームによると、この研究は、最新の探索型学習法とは全く異なる新しいゲーム理論のアプローチを導入しており、学習時には探索や明示的な相手モデルの作成を行わず、テスト時にはいくつかのゲーム固有のヒューリスティックの使用にのみ依存しているという。
今後、R-NaDがゼロサムゲームである2人用ゲームの枠を超えてどのように発展していくかは、まだ分からない。
しかし、研究チームは、不完全な情報を特徴とする巨大な空間を持つ現実世界のマルチインテリジェンス問題に対する深層学習手法のさらなる応用の可能性を信じている。
この手法は、群衆や交通のモデル化、スマートグリッド、オークションの設計、マーケティング問題など、このような不完全な情報シナリオに多くの応用が期待される。
研究の要旨
不完全情報ゲーム「ストラテゴ」を人間の専門家レベルでプレイする自律型エージェントDeepNashを紹介する。ストラテゴは、人工知能(AI)がまだマスターしていない数少ない代表的なボードゲームの1つである。チェスのように長期的な戦略思考が必要な一方で、ポーカーのように不完全な情報を扱う必要があるという、2つの課題を持つゲームであることが特徴だ。DeepNashの基盤となっている技術は、ゲーム理論的でモデルを用いない深層強化学習法を用いており、探索を行わず、ゼロから自己プレイでストラテゴをマスターすることを学習するものである。DeepNashはストラテゴにおいて既存の最先端AI手法を打ち負かし、人間のエキスパートプレーヤーと競いながら、Gravonゲームプラットフォームにおいて年間累計(2022年)および歴代トップ3ランキングを達成した。





コメントを残す