
NVIDIAは、現在開催中のGTC2022において、今日の主要なサーバー チップと比較して最高のパフォーマンスと 2 倍のメモリ帯域幅とエネルギー効率を実現する、高性能データセンター向けCPU「Grace CPU Superchip」 を発表した。
NVIDIA Grace CPU Superchip
新しいGrace CPU Superchipの説明に入る前に、その最初の実装について簡単に復習しておく必要があるだろう。NVIDIAは昨年、当初Grace CPUと呼んでいたものを初めて発表したが、同社はあまり詳細な情報を共有しなかった。NVIDIAは現在、この最初の取り組みの名称をGrace Hopper Superchipに変更している。
Grace Hopper Superchipは、1つのキャリアボードにCPUとGPUの2つのチップを搭載している。CPUは72コアで、Arm v9をサポートするNeoverseベースの設計を採用し、Hopper GPUと対になっていることが分かっている。これら2つのユニットは、CPUとGPUの間でメモリコヒーレンシーを提供する900GBpsのNVLink-C2C接続を介して通信するため、標準的なシステムに比べて30倍の帯域幅改善を謳うLPDDR5X ECCメモリのプールに、両方のユニットが同時にアクセスすることができ可能だ。
NVIDIAは当初、この設計に使用されるLPDDR5Xの量を発表していなかったが、ここにきて同社が「600GBのメモリーGPU」と主張していることがわかる。LPDDR5Xの最大容量は1パッケージあたり64GBであるため、CPUには最大512GBのLPDDR5Xが搭載されることになる。一方、Hopper GPUには通常80GBのHBM3容量があり、Nvidiaの600GBという数字に近い。GPUがこれだけのメモリ容量にアクセスできるようになれば、特に適切に最適化されたアプリケーションの場合、一部のワークロードに変革的な効果をもたらす可能性がある。

本日の発表は、Grace Hopper CPU+GPU設計をベースとし、Hopper GPUの代わりに第2のCPUパッケージを使用するGrace CPU Superchipを対象としている。これら2つの72コアチップは、NVLink-C2C接続を介して接続され、コヒーレントな900GB/秒接続を提供し、これらを1つの144コアユニットに統合します。さらに、Arm v9 Neoverseベースのチップは、ArmのScalable Vector Extensions(SVE)をサポートしています。これは、AVXと同様の機能を持つ、パフォーマンスを向上させるSIMD命令です。
Grace CPU SuperchipがArm v9を採用していることから、このチップはNeoverse N2設計を採用していることが分かりる。Neoverse N2プラットフォームは、SVE2やMemory Taggingのような新たに発表されたArm v9拡張機能をサポートするArm初のIPであり、V1プラットフォームと比較して最大40%の性能向上を実現している。N2 Perseusプラットフォームは、PCIe Gen 5.0、DDR5、HBM3、CCIX 2.0、およびCXL 2.0をサポートする5nm設計として提供される。Perseusの設計は、電力(ワット)あたりの性能と面積あたりの性能に最適化されている。
Grace CPU Superの消費電力が、2つのCPUとオンボード・メモリの両方でピーク500Wであることを考えれば、これは十分に理にかなっている。これは、AMDのEPYCのような、1チップあたりの消費電力が最大280W(メモリの消費電力は含まれない)の他の主要CPUに匹敵するものだ。Nvidiaは、Grace CPUが市場に投入されれば、競合CPUの2倍の効率になると主張している。
各CPUはそれぞれ8つのLPDDR5Xパッケージにアクセスできるため、2つのチップは依然として、近接メモリと遠距離メモリの標準的なNUMA的傾向の影響を受けることになる。それでも、2つのチップ間の帯域幅が増加することで、競合が少なくなるためレイテンシが減少し、非常に効率的なマルチチップ実装が可能になるはずだ。このデバイスには396MBのオンチップ・キャッシュも搭載されているが、これがシングルチップ用なのか両方なのかは不明だ。
Grace CPU Super・メモリ・サブシステムは、最大1TB/秒の帯域幅を提供する。NVIDIAによれば、これはCPUとしては初めてのことで、DDR5メモリをサポートする他のデータセンター・プロセッサの2倍以上だという。LPDDR5Xは、1TBの容量を提供する16のパッケージに分かれている。さらにNvidiaは、GraceがLPDDR5Xの最初のECC実装を使用していると述べている。
ここでベンチマークを紹介しよう。NVIDIAは、Grace CPU SuperchipがSPECrate_2017_int_baseベンチマークにおいて、DGX A100システムで使用している2つの旧世代の64コアEPYC Rome 7742プロセッサーよりも1.5倍高速であると主張している。NVIDIAはこの主張の根拠として、Grace CPUのスコアを740+(チップあたり370)と予測するプレシリコンシミュレーションを挙げている。データセンターにおける現在の性能リーダーであるAMDの現行世代EPYC Milanチップは、1個あたり382~424のSPEC結果を記録している。しかし、NVIDIAのソリューションには、電力効率やGPUに優しい設計など、他にも多くの利点があるだろう。
2つのGrace CPUは、NVIDIAの新しいNVLink Chip-to-Chip(C2C)インターフェイスを介して通信する。このダイ間およびチップ間の相互接続は、低レイテンシのメモリ・コヒーレンシーをサポートし、接続されたデバイスが同じメモリプールで同時に動作することを可能にする。NVIDIAは、エネルギー効率と面積効率に重点を置き、SERDESとLINKの設計技術を用いてこのインターフェイスを作り上げた。
NVIDIAによれば、NVLink-C2Cは、NVIDIAが現在使用しているPCIe 5.0 PHYと比較して、最大25倍のエネルギー効率と90倍の面積効率を実現し、最大900GB/秒以上のスループットをサポートする。さらに、このインターフェイスは、CXLやArmのAMBAコヒーレント・ハブ・インターフェイス(CHI)などの業界標準プロトコルをサポートしている。また、PCBベースの相互接続からシリコンインターポーザやウェーハスケールの実装まで、さまざまなタイプの接続をサポートする。
AMBA CHIのサポートは重要であり、Neoverseは、CCIX、CXL、PCIeなどの業界標準プロトコルの組み合わせを使用して、DDR、HBM、さまざまなアクセラレータ・テクノロジなどの他のプラットフォーム添加物へのインテリジェントな高帯域幅低レイテンシ・インターフェイスでN2設計を結びつけるArmのコヒーレント・メッシュ・ネットワーク(CMN-700)をサポートしている。この新しいメッシュ設計は、シングルダイおよびマルチチップ設計の両方をベースとする次世代Armプロセッサのバックボーンとして機能する。
NVIDIAはまた、Intel、AMD、Arm、TSMC、Samsungといった他の業界大手がサポートする新しいUCIeチップレット相互接続規格をサポートすることも発表した。この標準化されたダイ間相互接続は、オープンソース設計でチップレット間の通信を提供するよう設計されており、コストを削減し、検証されたチップレットの広範なエコシステムを育成する。最終的に、UCIe規格は、USB、PCIe、NVMeなどの他の接続規格と同様に、ユビキタスで普遍的なものになることを目指すと同時に、チップレット接続に卓越した電力と性能の指標を提供する。NVIDIAがこの新しいイニシアチブをサポートするということは、理論的には、将来NVIDIAのCPUチップレットが競合するチップ設計と同じパッケージに搭載されることを意味する。
NVLink-C2Cは今後、GPU、CPU、SOC、NIC、DPUを含むNVIDIAのすべてのシリコンに適用される。NVIDIAはまた、他社がチップレット設計でNVLinkを使用できるように仕様を開放するとしている。NVIDIAは、NVLink-C2CはUCIeよりも低レイテンシ、高帯域幅、高電力効率に最適化されていると主張しているが、これにより顧客は、UCIeインターフェースまたはNVLinkのいずれかを採用する選択肢を得ることになる。
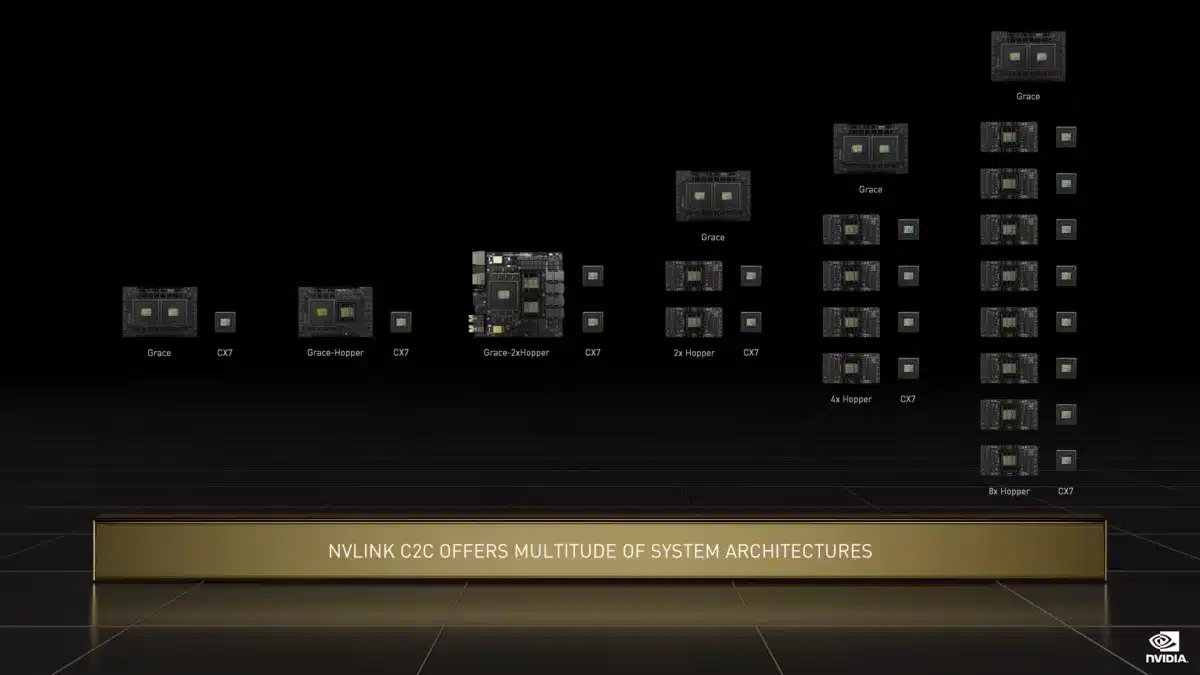
上の図に描かれているように、Grace Hopper SuperchipおよびGrace CPU Superchipシステムは、最大8個のHopper GPUを搭載して、いくつかの異なる構成で組み合わせることもできる。これらの設計では、内蔵のPCIe 5.0スイッチを介してNVLink通信を可能にするNVIDIAのConnectX-7 SmartNIC(CX7)を使用しているため、より拡張性の高いシステム間アプリケーションをサポートしている。
NVIDIAはGrace CPU Superchipでターゲット市場を拡大し、ハイパースケールコンピューティング、クラウド、データ分析、HPC、AIのワークロードを網羅し、事実上、汎用サーバー市場をターゲットとしている。グレイスCPUスーパーチップは、NVIDIAのCUDAスタック全体をサポートし、NVIDIA RTX、NVIDIA AI、HPC、Omniverseを含むNVIDIAのあらゆるアプリケーションを実行する。チップは2023年前半に出荷が開始される。
NVIDIAによると、このアーキテクチャに関するより詳細な情報を提供するホワイトペーパーが公開される予定とのことである。
Sources
- NVIDIA: NVIDIA が Grace CPU Superchip を発表





コメントを残す