
AIの台頭により、失われる仕事の筆頭にまさかソフトウェア開発者が挙げられる日が来ようとは想像もしていなかったが、ここ数ヶ月、開発者の仕事を奪おうとする新しいAIツールが続々と登場している。最初はGitHub Copilotで、開発者のコード生成を引き受けた。Amazonもこの分野に参入し、戦争は激化している。そして今、研究者たちが大規模言語モデル(LLM)がセルフデバッグする方法を発見したことで、デバッグさえも奪われようとしている。
Google Brainの研究者が発表した論文で、LLMが自分のコードをデバッグできるようにする技術が実証された。この方法を用いると、LLMはテキストからSQLへの生成で最大9%、コード翻訳で10%近い精度を向上させることができたという。この方法は、初期の改善として注目されており、他の方法とともに、DevOpsのパラダイムシフトを呼び起こす可能性がある。
この論文は、「Teaching Large Language Models To Self-Debug」と題され、自己デバッグを可能にする新しい方法について説明している。このアプローチは、LLMの中核的な強みである、自然言語でコードを説明する能力を活用したものだ。LLMに自然言語で説明させることで、LLMは自分自身の間違いを特定し、それを修正することができる。
このアプローチは、額面上は極めてシンプルに見えるかも知れないが、その効果は実証されている。LLMは、SQLのSpiderデータセット、C++からPythonへの翻訳のTranscoder、PythonのMBPPなど、さまざまなコード生成ベンチマークで最先端の性能を達成することが出来た。より良いコードを作成するだけでなく、セルフデバッグはサンプルの効率を向上させ、それぞれのアウトプットがセルフデバッグを使用しないアウトプットよりも「価値」があることを意味する。
このアプローチは、人間のプログラマーにヒントを得たと研究者は述べている。プログラマーは、一回でコードを正しく理解することはあまりなく、自分が作ったものをもう一度見てみる傾向にある。LLMにこの機能を持たせることは、過去にもSelf-RefineやReflexionといった研究論文で試みられていた。しかし、セルフデバッグは、最も少ないリソースで、最も最適なアウトプットを提供するアプローチであるようだ。
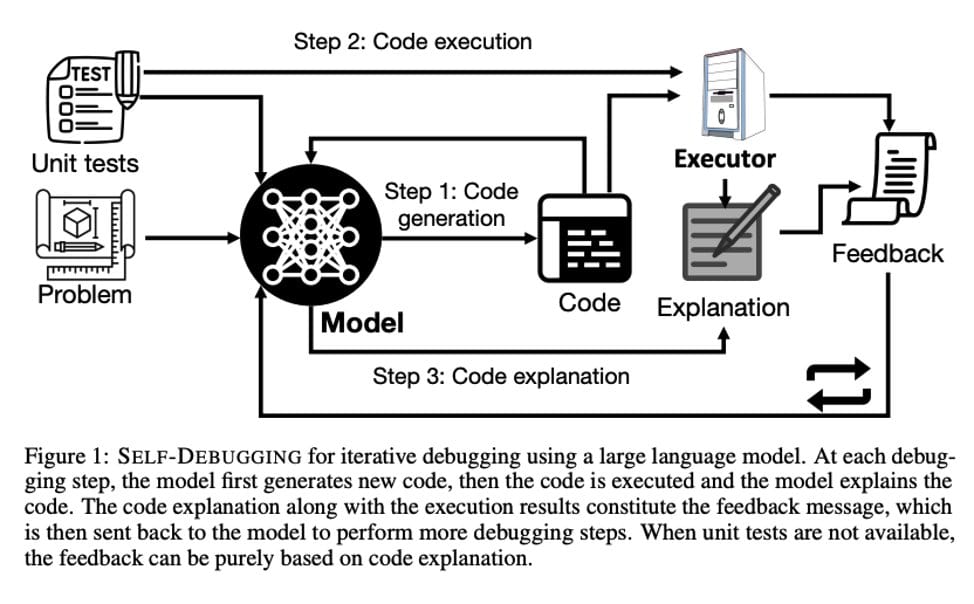
セルフデバッグのためのワークフローはかなり直感的だ。最初のステップでは、モデルがコードを生成し、それが実行される。このコードが実行される間、モデルはコードを説明し、実行結果と一緒に「フィードバック・メッセージ」を作成する。このメッセージはLLMにフィードバックされ、プログラミングが正常に実行されるまで、このプロセスが繰り返される。
このアプローチに加え、研究チームは、いくつかのプロンプトと実行ベースのコード選択を組み合わせた。数回のプロンプト入力により、LLMは入出力構文を学習し、すべての出力に説明生成コンポーネントを統合することができるようになった。実行ベースのコード選択により、LLMは様々なサンプルから最適な最終予測を選択することができ、サンプル効率を向上させることができる。
論文にあるように、このモデルは、間違った出力に対して説明を与えることで、繰り返し自分自身を改善することが出来る。この方法は、LLMから直接コードを受け取るよりも多くのステップを必要とするかもしれないが、追加のトレーニングや微調整を必要としないため、既存のコード生成LLMに簡単に組み込むことができる可能性があることを意味する。
このアプローチなどにより、次世代のオートコーダはセルフデバッグができるようになるかも知れない。このことは、「ディスラプターになるのか、イネーブラーになるのか」という非常に重要な問いを提起している。
オートコーディングプラットフォームを自分たちの職業に対する脅威と考える人がいる一方で、オートコーディングプラットフォームには開発者の能力を向上させる能力があると感じる人もいる。
GitHub Copilotが行った調査によると、AIペアプログラマによって88%のプログラマが生産性が向上したと感じ、96%が反復作業のスピードが上がったと回答している。実際、ソフトウェアを使用している開発者のほぼ3/4が、Copilotのおかげで流れに身を任せることができたと述べており、ペアプログラマを使用している人は、使用していない人に比べて55%多くタスクを完了させている。
開発者がAIツールから時折出てくるバグだらけのコードのデバッグに時間を費やしても、結果的に全体的にスムーズなワークフローになる。実際、デバッグはこのワークフローにおける最大の破壊要因だろう。この思いに共鳴して、Google Brainのリサーチサイエンティストで論文の研究者の一人であるXinyun Chenは、自己デバッグ能力の向上はLLMコーディングを強化するために最も重要なことの一つだと述べている。
Constitution AI、Reflexion、AutoGPTなどの他のアプローチと組み合わせると、来年の今頃には平均的なDevOpsワークフローが極めて異なるものになる可能性がある。Codiumの共同創業者兼CEOであるItamar Friedman氏は、ツイートの中で「『コードジェン』ツールを含むほとんどの現実世界のソフトウェア製品は、スタックモジュールとAIエージェントを備えた本格的なソリューションになるだろう」と述べている。これは、AIモデルが他のAIモデルを呼び出して一種の創発的な知性をシミュレートする「スタッキング」AIモデルについて言及したものだ。
これは開発者の仕事に大きな混乱をもたらすという議論があるが、業界の人々は同じ考えを持っていないようだ。
論文
参考文献
- I Programmer: Self-Debugging Is Possible
研究の要旨
大規模言語モデル(LLM)は、コード生成において優れた性能を発揮している。しかし、複雑なプログラミングタスクでは、一度に正しい解を生成することは困難であるため、いくつかの先行研究では、コード生成性能を向上させるためにプログラム修復アプローチを設計している。本研究では、大規模な言語モデルに対して、予測されたプログラムをデバッグするための数発のデモを教えるSelf-Debuggingを提案する。特に、Self-Debuggingは、大規模言語モデルにラバーダックデバッグを教えることができることを実証する。すなわち、コードの正しさやエラーメッセージに関するフィードバックがなくても、モデルは、自然言語で生成コードを説明することによって、間違いを特定することができる。Self-Debuggingは、テキストからSQLへの生成のためのSpiderデータセット、C++からPythonへの翻訳のためのTransCoder、テキストからPythonへの生成のためのMBPPなど、いくつかのコード生成ベンチマークで最先端の性能を達成した。予測の正しさを検証するユニットテストが存在しないSpiderベンチマークでは、コード説明を伴うセルフデバッグにより、ベースラインを常に2~3%改善し、最も難しいラベルの問題では予測精度を9%改善した。ユニットテストが利用できるTransCoderとMBPPでは、Self-Debuggingはベースラインの精度を最大12%向上させる。一方、フィードバックメッセージの活用や失敗した予測の再利用により、Self-Debuggingはサンプル効率を顕著に改善し、10倍以上の候補プログラムを生成するベースラインモデルと同等かそれ以上の性能を発揮することができる。




コメントを残す