
Googleは、数百の話し言葉を理解するために設計したユニバーサルスピーチAIモデルの詳細を公開した。
同社の Universal Speech Model (USM) は、300以上の言語にまたがる1200万時間のスピーチと280億センテンスのテキストでトレーニングされているという。
現在の自動音声認識(ASR)の最大の課題は、従来の教師あり学習法が拡張性に乏しく、時間がかかることであり、音声認識の多様性と品質を拡大するためには、モデル自体をより効率的に改善する必要がある。
Googleのアプローチは、「継続的な自己教師付き学習と微調整」だ。具体的には、まず、音声データを外部からの監視なしに大量に分析・学習できる自己教師付き学習法「BEST-RQ」を採用し(この段階だけで作業量の8割を占める)、この段階では、人間に頼らず機械自身がすべて監視・学習している。
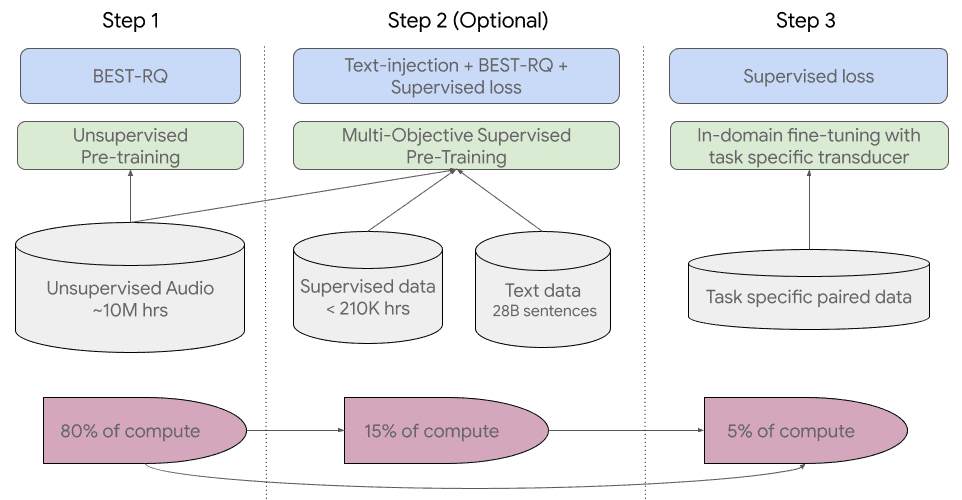
第2段階は、マルチターゲット教師ありの事前学習モデルで、主にテキスト注入、BEST-RQ、教師ありの損失関数によって、他のデータからの知識を統合する。Googleは、第1段階と第2段階で非常に良い結果が得られ、作業量が5%しかない第3段階でも、全体として非常に質の高いモデルが得られたとしている。
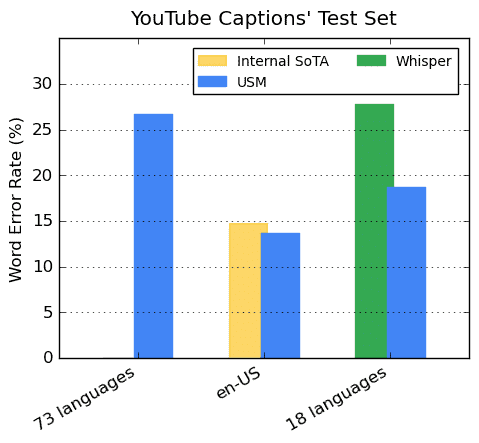
Googleによると、このAIモデルはYouTube動画のキャプション作成に使用することを想定しており、現在100の言語について自動音声認識を行うことができるという。
機械翻訳モデルは学習用のデータを多く必要とするため、オンライン上に記述例が少ない言語のツールを開発することは困難だ。
これらの言語の中には、世界で2,000万人未満しか話していないものもあり、「必要なトレーニングデータを見つけるのが非常に難しい」と、Googleは述べている。
Google Researchは新しい研究論文の中で、AIモデルはモデルのエンコーダを事前に訓練し、「より少ないラベル付きデータセットで微調整する」ことで、十分に普及していない言語を認識できたと述べている。
また、USMの背景にあるこの学習プロセスにより、「新しい言語やデータへの適応に有効である」と研究者は述べている。なお、このAIモデルのAPIは、研究者の要望に応じて公開されている。
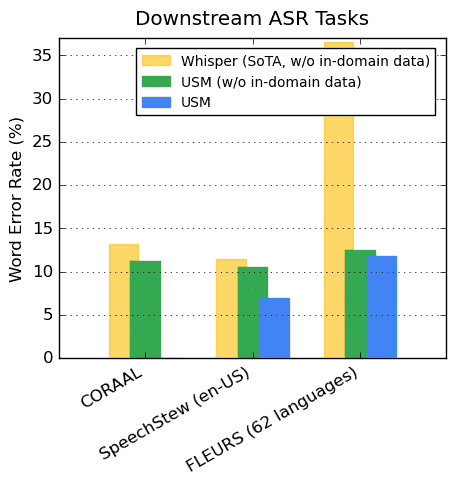
Googleは、USMが73の言語で平均30pc以下の単語エラー率を達成できたとし、これは「これまで達成したことのないマイルストーン」であると述べている。
この新しいモデルは、1,000の話し言葉に対応できるAIモデルを構築するという同社のミッションにおける「重要な第一歩」であるのことだ。昨年11月に初めて発表されたこの構想は、世界中の「疎外されたコミュニティに住む数十億の人々」に、より大きなインクルージョンをもたらすのに役立つとGoogleは述べている。
「USMの開発は、世界の情報を整理し、普遍的にアクセスできるようにするというGoogleの使命を実現するための重要な取り組みです。USMのベースモデルアーキテクチャとトレーニングパイプラインは、音声モデリングを次の1,000言語へ拡大するための基盤になると考えています」と、Googleの研究者はブログで述べている。
Googleによると、アメリカ英語のパフォーマンスでは、他の最先端モデルよりもWERが6%低く、OpenAIのWhisper(large-v2)と比較すると、WhisperのWERが40%未満である18言語において、GoogleのUSM WERはWhisperよりも平均32.7%低い。(簡単に言えば、Whisperの方がはるかに優れている)
昨年7月、Meta社は200種類の言語を翻訳するAIモデルを初めて開発したと報告していた。
Googleは、ChatGPTが業界に激震を与えた後、ここ数ヶ月でAIへの注力を再燃させたようだ。
MicrosoftがBing検索エンジンを強化するためにChatGPTを使用すると発表したのと同じ頃、GoogleはOpenAIの製品に対抗しようと、独自のBardチャットボットを公開しているが、一般にはまだ利用が出来ていない。
論文
参考文献
- Google Research:
- via The Verge: Google’s one step closer to building its 1,000-language AI model
研究の要旨
本論文では、100以上の言語にわたる自動音声認識(ASR)を行う単一の大規模モデルであるUniversal Speech Model (USM)を紹介する。これは、300以上の言語にまたがる1200万時間の大規模なラベルなし多言語データセットでモデルのエンコーダを事前学習し、より小さなラベル付きデータセットで微調整することで達成される。ランダムプロジェクション量子化と音声-テキストモダリティマッチングを用いた多言語事前学習により、下流の多言語ASRと音声-テキスト翻訳タスクで最先端の性能を達成した。また、Whisperモデルの1/7のサイズのラベル付きトレーニングセットを使用しているにもかかわらず、我々のモデルは、多くの言語におけるドメイン内およびドメイン外の音声認識タスクにおいて同等以上の性能を示すことを実証する。




コメントを残す